The Ultimate WorkstationFor Open Source AI
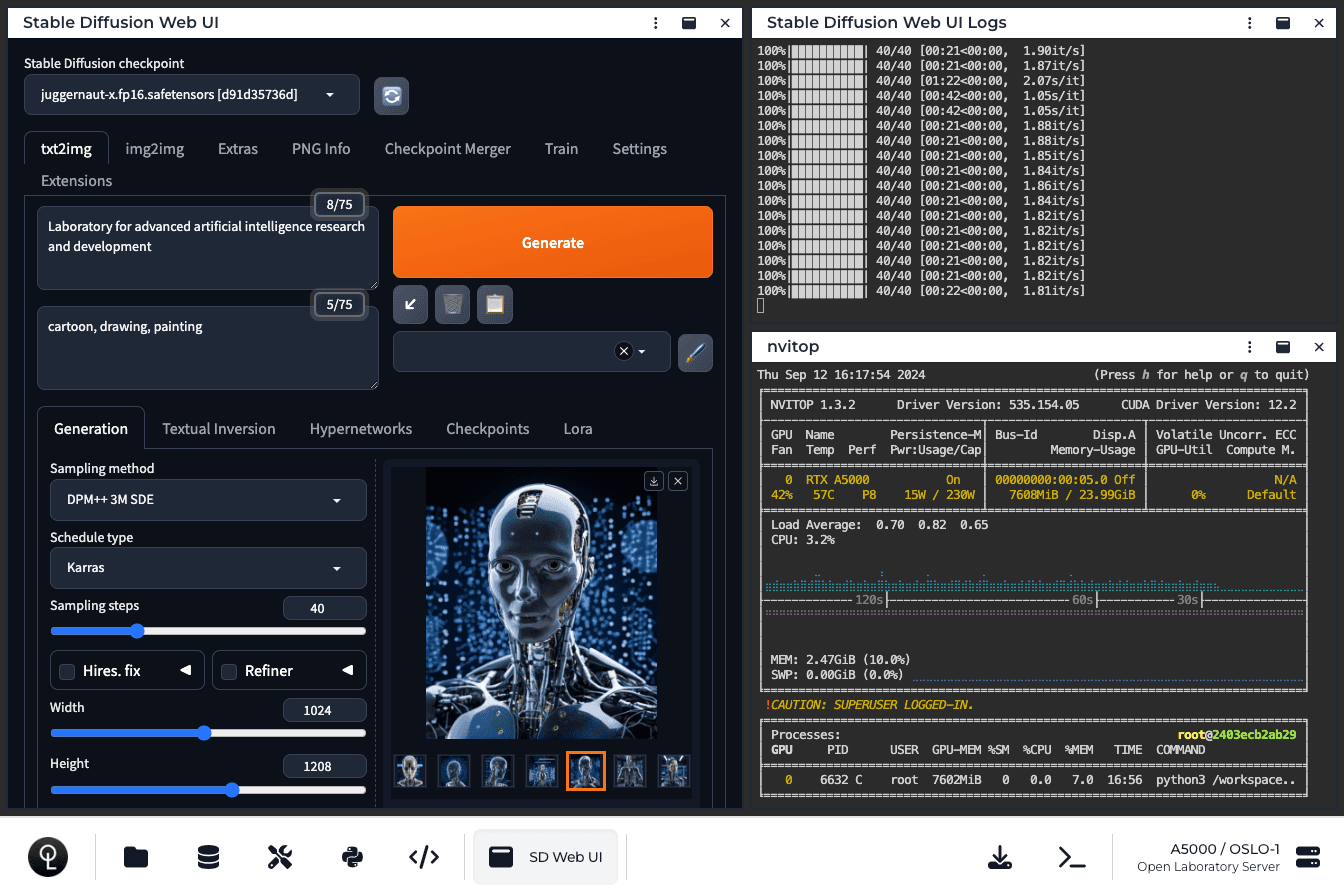
Stable Diffusion Web UI
App Library
Install AI research tools, APIs, and applications with one click.

Generate images and videos using a powerful low-level workflow graph builder - the fastest, most flexible, and most advanced visual generation UI.

Forge is a platform built on top of Stable Diffusion WebUI to make development easier, optimize resource management, speed up inference, and study experimental features.

Simple, intuitive, and powerful image generation. Easily inpaint, outpaint, and upscale. Influence the generation using image prompts.

Train your own LoRAs and finetunes for Stable Diffusion and Flux using this popular GUI for the Kohya trainers.
Generate images and videos using a powerful low-level workflow graph builder - the fastest, most flexible, and most advanced visual generation UI.
Forge is a platform built on top of Stable Diffusion WebUI to make development easier, optimize resource management, speed up inference, and study experimental features.
Simple, intuitive, and powerful image generation. Easily inpaint, outpaint, and upscale. Influence the generation using image prompts.
Train your own LoRAs and finetunes for Stable Diffusion and Flux using this popular GUI for the Kohya trainers.
Generate images and videos using a powerful low-level workflow graph builder - the fastest, most flexible, and most advanced visual generation UI.
Forge is a platform built on top of Stable Diffusion WebUI to make development easier, optimize resource management, speed up inference, and study experimental features.
Simple, intuitive, and powerful image generation. Easily inpaint, outpaint, and upscale. Influence the generation using image prompts.
Train your own LoRAs and finetunes for Stable Diffusion and Flux using this popular GUI for the Kohya trainers.
Generate images and videos using a powerful low-level workflow graph builder - the fastest, most flexible, and most advanced visual generation UI.
Forge is a platform built on top of Stable Diffusion WebUI to make development easier, optimize resource management, speed up inference, and study experimental features.
Simple, intuitive, and powerful image generation. Easily inpaint, outpaint, and upscale. Influence the generation using image prompts.
Train your own LoRAs and finetunes for Stable Diffusion and Flux using this popular GUI for the Kohya trainers.

Open WebUI is an open-source, self-hosted web interface with a polished, ChatGPT-like user experience for interacting with LLMs. Integrates seamlessly with local Ollama installation.

Automatic1111's legendary web UI for Stable Diffusion, the most comprehensive and full-featured AI image generation application in existence.

The most full-featured web interface for experimenting with open source Large Language Models. Featuring a wide range of configurable settings, inference engines, and plugins.

Experiment with various cutting-edge audio generation models, such as Bark (Text-to-Speech), RVC (Voice Cloning), and MusicGen (Text-to-Music).
Open WebUI is an open-source, self-hosted web interface with a polished, ChatGPT-like user experience for interacting with LLMs. Integrates seamlessly with local Ollama installation.
Automatic1111's legendary web UI for Stable Diffusion, the most comprehensive and full-featured AI image generation application in existence.
The most full-featured web interface for experimenting with open source Large Language Models. Featuring a wide range of configurable settings, inference engines, and plugins.
Experiment with various cutting-edge audio generation models, such as Bark (Text-to-Speech), RVC (Voice Cloning), and MusicGen (Text-to-Music).
Open WebUI is an open-source, self-hosted web interface with a polished, ChatGPT-like user experience for interacting with LLMs. Integrates seamlessly with local Ollama installation.
Automatic1111's legendary web UI for Stable Diffusion, the most comprehensive and full-featured AI image generation application in existence.
The most full-featured web interface for experimenting with open source Large Language Models. Featuring a wide range of configurable settings, inference engines, and plugins.
Experiment with various cutting-edge audio generation models, such as Bark (Text-to-Speech), RVC (Voice Cloning), and MusicGen (Text-to-Music).
Open WebUI is an open-source, self-hosted web interface with a polished, ChatGPT-like user experience for interacting with LLMs. Integrates seamlessly with local Ollama installation.
Automatic1111's legendary web UI for Stable Diffusion, the most comprehensive and full-featured AI image generation application in existence.
The most full-featured web interface for experimenting with open source Large Language Models. Featuring a wide range of configurable settings, inference engines, and plugins.
Experiment with various cutting-edge audio generation models, such as Bark (Text-to-Speech), RVC (Voice Cloning), and MusicGen (Text-to-Music).
Open Source Moves Fast
Stay on the Cutting Edge
Explore the latest advances in AI research.
Run models and apps on a dedicated cloud GPU server.
Laboratory OS
The Linux Server for Open-Source AI
Cloud GPUs with the simplicity of a local workstation. Use the web desktop to install apps, download models, run advanced workflows, and deploy self-hosted APIs.




Model Library
Browse the latest open-weight models. Or bring your own.
Kimi K2 is an open-source mixture-of-experts language model developed by Moonshot AI, featuring 1 trillion total parameters with 32 billion activated per inference. The model utilizes a 128,000-token context window and specializes in agentic intelligence, tool use, and autonomous reasoning capabilities. Trained on 15.5 trillion tokens with reinforcement learning techniques, it demonstrates performance across coding, mathematical reasoning, and multi-step task execution benchmarks.
Gemma 3n E4B is a multimodal generative AI model developed by Google DeepMind with 8 billion raw parameters yielding 4 billion effective parameters. Built on the MatFormer architecture for mobile and edge deployment, it processes text, image, audio, and video inputs to generate text outputs. The model features elastic inference capabilities, allowing extraction of smaller sub-models for faster performance, and supports over 140 languages with demonstrated proficiency in reasoning, coding, and multilingual tasks.
DeepSeek R1 (0528) is a large language model developed by DeepSeek-AI featuring 671 billion total parameters with 37 billion activated during inference. Built on the DeepSeek-V3-Base architecture using Mixture-of-Experts design, it employs Group Relative Policy Optimization and multi-stage training with reinforcement learning to enhance reasoning capabilities. The model supports 128,000 token context length and demonstrates improved performance on mathematical, coding, and reasoning benchmarks compared to its predecessors.
Qwen3-0.6B is a dense language model with 0.6 billion parameters developed by Alibaba Cloud, featuring a 28-layer transformer architecture with Grouped Query Attention. The model supports dual thinking modes for adaptive reasoning and general dialogue, processes up to 32,768 tokens context length, and demonstrates multilingual capabilities across over 100 languages. It utilizes strong-to-weak distillation from larger Qwen3 models and is released under Apache 2.0 license.
Qwen3-4B is a 4.0 billion parameter transformer language model developed by Alibaba Cloud, featuring dual reasoning modes that allow users to toggle between detailed step-by-step thinking and rapid response generation. Released under Apache 2.0 license, the model supports 32,768 token contexts, demonstrates strong performance across mathematical reasoning and coding benchmarks, and incorporates advanced training techniques including strong-to-weak distillation from larger teacher models.
Qwen3-14B is a dense transformer language model developed by Alibaba Cloud with 14.8 billion parameters, featuring hybrid "thinking" and "non-thinking" reasoning modes that can be controlled via prompts. The model supports 119 languages, extends to 131k token contexts through YaRN scaling, and includes agent capabilities with tool-use functionality, all released under Apache 2.0 license.
Qwen3-30B-A3B is a Mixture-of-Experts language model developed by Alibaba Cloud featuring 30.5 billion total parameters with 3.3 billion activated per token. The model employs hybrid reasoning modes that allow dynamic switching between step-by-step thinking for complex tasks and rapid responses for simpler queries. It supports 119 languages, extends to 131,072 tokens context length, and utilizes strong-to-weak distillation from larger Qwen3 models for efficient deployment while maintaining competitive performance on reasoning, coding, and multilingual benchmarks.
HiDream I1 Full is an open-source image generation model developed by HiDream.ai featuring a 17 billion parameter sparse Diffusion Transformer architecture with Mixture-of-Experts design. The model employs hybrid text encoding combining Long-CLIP, T5-XXL, and Llama 3.1 8B components for precise text-to-image synthesis. It demonstrates strong performance on industry benchmarks and supports diverse visual styles through flow-matching in latent space.
Mistral Small 3.1 (2503) is a 24-billion parameter transformer-based model developed by Mistral AI and released under Apache 2.0 license. This multimodal and multilingual model processes both text and visual inputs with a context window of 128,000 tokens using the Tekken tokenizer. It demonstrates competitive performance on academic benchmarks including MMLU and GPQA while supporting function calling and structured output generation for automation workflows.
Gemma 3 4B is a multimodal instruction-tuned model developed by Google DeepMind that processes text and image inputs to generate text outputs. The model features a decoder-only transformer architecture with approximately 4.3 billion parameters, supports context windows up to 128,000 tokens, and operates across over 140 languages. It incorporates a SigLIP vision encoder for image processing and utilizes grouped-query attention with interleaved local and global attention layers for efficient long-context handling.
Gemma 3 27B is a multimodal generative AI model developed by Google DeepMind that processes both text and image inputs to produce text outputs. Built on a decoder-only transformer architecture with 27 billion parameters, it incorporates a SigLIP vision encoder and supports context lengths up to 128,000 tokens. The model was trained on over 14 trillion tokens and demonstrates competitive performance across language, coding, mathematical reasoning, and vision-language tasks.
QwQ 32B is a 32.5-billion parameter causal language model developed by Alibaba Cloud as part of the Qwen series. The model employs a transformer architecture with 64 layers and Grouped Query Attention, trained using supervised fine-tuning and reinforcement learning focused on mathematical reasoning and coding proficiency. Released under Apache 2.0 license, it demonstrates competitive performance on reasoning benchmarks despite its relatively compact size.
Wan 2.1 I2V 14B 480P is an image-to-video generation model developed by Wan-AI featuring 14 billion parameters and operating at 480P resolution. Built on a diffusion transformer architecture with T5-based text encoding and a 3D causal variational autoencoder, the model transforms static images into temporally coherent video sequences guided by textual prompts, supporting both Chinese and English text rendering within its generative capabilities.
Wan 2.1 T2V 14B is a 14-billion parameter video generation model developed by Wan-AI that creates videos from text descriptions or images. The model employs a spatio-temporal variational autoencoder and diffusion transformer architecture to generate content at 480P and 720P resolutions. It supports multiple languages including Chinese and English, handles various video generation tasks, and demonstrates computational efficiency across different hardware configurations when deployed for research applications.
Qwen2.5 VL 7B is a 7-billion parameter multimodal language model developed by Alibaba Cloud that processes text, images, and video inputs. The model features a Vision Transformer with dynamic resolution support and Multimodal Rotary Position Embedding for spatial-temporal understanding. It demonstrates capabilities in document analysis, OCR, object detection, video comprehension, and structured output generation across multiple languages, released under Apache-2.0 license.
Lumina Image 2.0 is a 2 billion parameter text-to-image generative model developed by Alpha-VLLM that utilizes a flow-based diffusion transformer architecture. The model generates high-fidelity images up to 1024x1024 pixels from textual descriptions, employs a Gemma-2-2B text encoder and FLUX-VAE-16CH variational autoencoder, and is released under the Apache-2.0 license with support for multiple inference solvers and fine-tuning capabilities.
MiniMax Text 01 is an open-source large language model developed by MiniMaxAI featuring 456 billion total parameters with 45.9 billion active per token. The model employs a hybrid attention mechanism combining Lightning Attention with periodic Softmax Attention layers across 80 transformer layers, utilizing a Mixture-of-Experts design with 32 experts and Top-2 routing. It supports context lengths up to 4 million tokens during inference and demonstrates competitive performance across text generation, reasoning, and coding benchmarks.
DeepSeek-VL2 is a series of Mixture-of-Experts vision-language models developed by DeepSeek-AI that integrates visual and textual understanding through a decoder-only architecture. The models utilize a SigLIP vision encoder with dynamic tiling for high-resolution image processing, coupled with DeepSeekMoE language components featuring Multi-head Latent Attention. Available in three variants with 1.0B, 2.8B, and 4.5B activated parameters, the models support multimodal tasks including visual question answering, optical character recognition, document analysis, and visual grounding capabilities.
DeepSeek VL2 Tiny is a vision-language model from Deepseek AI that activates 1.0 billion parameters using Mixture-of-Experts architecture. The model combines a SigLIP vision encoder with a DeepSeekMoE-based language component to handle multimodal tasks including visual question answering, optical character recognition, document analysis, and visual grounding across images and text.
Llama 3.3 70B is a 70-billion parameter transformer-based language model developed by Meta, featuring instruction tuning through supervised fine-tuning and reinforcement learning from human feedback. The model supports a 128,000-token context window, incorporates Grouped-Query Attention for enhanced inference efficiency, and demonstrates multilingual capabilities across eight validated languages including English, German, French, Italian, Portuguese, Hindi, Spanish, and Thai.
CogVideoX 1.5 5B is an open-source video generation model developed by THUDM that creates high-resolution videos up to 1360x768 resolution from text prompts and images. The model employs a 3D causal variational autoencoder with 8x8x4 compression and an expert transformer architecture featuring adaptive LayerNorm for multimodal alignment. It supports both text-to-video and image-to-video synthesis with durations of 5-10 seconds at 16 fps, released under Apache 2.0 license.
QwQ 32B Preview is an experimental large language model developed by Alibaba Cloud's Qwen Team, built on the Qwen 2 architecture with 32.5 billion parameters. The model specializes in mathematical and coding reasoning tasks, achieving 65.2% on GPQA, 50.0% on AIME, 90.6% on MATH-500, and 50.0% on LiveCodeBench benchmarks through curiosity-driven, reflective analysis approaches.
Stable Diffusion 3.5 Large is an 8.1-billion-parameter text-to-image model utilizing Multimodal Diffusion Transformer architecture with Query-Key Normalization for enhanced training stability. The model generates images up to 1-megapixel resolution across diverse styles including photorealism, illustration, and digital art. It employs three text encoders supporting up to 256 tokens and demonstrates strong prompt adherence capabilities.
CogVideoX-5B-I2V is an open-source image-to-video generative AI model developed by THUDM that produces 6-second videos at 720×480 resolution from input images and English text prompts. The model employs a diffusion transformer architecture with 3D Causal VAE compression and generates 49 frames at 8 fps, supporting various video synthesis applications through its controllable conditioning mechanism.
Qwen 2.5 Math 7B is a 7.62-billion parameter language model developed by Alibaba Cloud that specializes in mathematical reasoning tasks in English and Chinese. The model employs chain-of-thought reasoning and tool-integrated approaches using Python interpreters for computational tasks. It demonstrates improved performance over its predecessor on mathematical benchmarks including MATH, GSM8K, and Chinese mathematics evaluations, achieving 83.6 on MATH using chain-of-thought methods.
Qwen2.5-Coder-7B is a 7.61 billion parameter transformer-based language model developed by Alibaba Cloud's Qwen Team, specialized for code generation and reasoning across 92 programming languages. The model features a 128,000-token context window, supports fill-in-the-middle code completion, and was trained on 5.5 trillion tokens of code and text data, demonstrating competitive performance on coding benchmarks like HumanEval and mathematical reasoning tasks.
Qwen 2.5 14B is a 14.7 billion parameter transformer-based language model developed by Alibaba Cloud's Qwen Team, featuring a 128,000 token context window and support for over 29 languages. The model utilizes advanced architectural components including Grouped Query Attention, RoPE embeddings, and SwiGLU activation, and was pretrained on up to 18 trillion tokens of diverse multilingual data for applications in reasoning, coding, and mathematical tasks.
Qwen 2.5 72B is a 72.7 billion parameter transformer-based language model developed by Alibaba Cloud's Qwen Team, released in September 2024. The model features a 128,000-token context window, supports over 29 languages, and demonstrates strong performance on coding, mathematical reasoning, and knowledge benchmarks. Built with architectural improvements including RoPE and SwiGLU activation functions, it excels at structured data handling and serves as a foundation model for fine-tuning applications.
Command R (08-2024) is a 32-billion parameter generative language model developed by Cohere, featuring a 128,000-token context window and support for 23 languages. The model incorporates Grouped Query Attention for enhanced inference efficiency and specializes in retrieval-augmented generation with citation capabilities, tool use, and multilingual comprehension. It demonstrates improved throughput and reduced latency compared to previous versions while offering configurable safety modes for enterprise applications.
Phi-3.5 Mini Instruct is a 3.8 billion parameter decoder-only Transformer model developed by Microsoft that supports multilingual text generation with a 128,000-token context window. The model demonstrates competitive performance across 22 languages and excels in reasoning, code generation, and long-context tasks, achieving an average benchmark score of 61.4 while maintaining efficient resource utilization.
AuraFlow v0.3 is a 6.8 billion parameter, flow-based text-to-image generative model developed by fal.ai. Built on an optimized DiT architecture with Maximal Update Parametrization, it features enhanced prompt following capabilities through comprehensive recaptioning and prompt enhancement pipelines. The model supports multiple aspect ratios and achieved a GenEval score of 0.703, demonstrating effective text-to-image synthesis across diverse artistic styles and photorealistic outputs.
Stable Fast 3D is a transformer-based generative AI model developed by Stability AI that reconstructs textured 3D mesh assets from single input images in approximately 0.5 seconds. The model predicts comprehensive material properties including albedo, roughness, and metallicity, producing UV-unwrapped meshes suitable for integration into rendering pipelines and interactive applications across gaming, virtual reality, and design workflows.
FLUX.1 [schnell] is a 12-billion parameter text-to-image generation model developed by Black Forest Labs using hybrid diffusion transformer architecture with rectified flow and latent adversarial diffusion distillation. The model generates images from text descriptions in 1-4 diffusion steps, supporting variable resolutions and aspect ratios. Released under Apache 2.0 license, it employs flow matching techniques and parallel attention layers for efficient synthesis.
Mistral Large 2 is a dense transformer-based language model developed by Mistral AI with 123 billion parameters and a 128,000-token context window. The model demonstrates strong performance across multilingual tasks, code generation in 80+ programming languages, mathematical reasoning, and function calling capabilities. It achieves 84% on MMLU, 92% on HumanEval, and 93% on GSM8K benchmarks while maintaining concise output generation.
Mistral NeMo 12B is a transformer-based language model developed collaboratively by Mistral AI and NVIDIA, featuring 12 billion parameters and a 128,000-token context window. The model incorporates grouped query attention, quantization-aware training for FP8 inference, and utilizes the custom Tekken tokenizer for improved multilingual and code compression efficiency. Available in both base and instruction-tuned variants, it demonstrates competitive performance on standard benchmarks while supporting function calling and multilingual capabilities across numerous languages including English, Chinese, Arabic, and various European languages.
Llama 3.1 70B is a transformer-based decoder language model developed by Meta with 70 billion parameters, trained on approximately 15 trillion tokens with a 128K context window. The model supports eight languages and demonstrates competitive performance across benchmarks for reasoning, coding, mathematics, and multilingual tasks. It is available under the Llama 3.1 Community License Agreement for research and commercial applications.
Gemma 2 9B is an open-weights decoder-only transformer language model developed by Google as part of the Gemma family. Trained on 8 trillion tokens using TPUv5p infrastructure, the model supports English text generation, question answering, and summarization tasks. Available in both pre-trained and instruction-tuned versions with bfloat16 precision, it demonstrates competitive performance on benchmarks like MMLU and coding evaluations while incorporating safety filtering mechanisms.
DeepSeek Coder V2 Lite is an open-source Mixture-of-Experts code language model featuring 16 billion total parameters with 2.4 billion active parameters during inference. The model supports 338 programming languages, processes up to 128,000 tokens of context, and demonstrates competitive performance on code generation benchmarks including 81.1% accuracy on Python HumanEval tasks.
Qwen2-72B is a 72.71 billion parameter Transformer-based language model developed by Alibaba Cloud, featuring Group Query Attention and SwiGLU activation functions. The model demonstrates strong performance across diverse benchmarks including MMLU (84.2), HumanEval (64.6), and GSM8K (89.5), with multilingual capabilities spanning 27 languages and extended context handling up to 128,000 tokens for specialized applications.
Yi 1.5 34B is a 34.4 billion parameter decoder-only Transformer language model developed by 01.AI, featuring Grouped-Query Attention and SwiGLU activations. Trained on 3.1 trillion bilingual tokens, it demonstrates capabilities in reasoning, mathematics, and code generation, with variants supporting up to 200,000 token contexts and multimodal understanding through vision-language extensions.
DeepSeek V2 is a large-scale Mixture-of-Experts language model with 236 billion total parameters, activating only 21 billion per token. It features Multi-head Latent Attention for reduced memory usage and supports context lengths up to 128,000 tokens. Trained on 8.1 trillion tokens with emphasis on English and Chinese data, it demonstrates competitive performance across language understanding, code generation, and mathematical reasoning tasks while achieving significant efficiency improvements over dense models.
Phi-3 Mini Instruct is a 3.8 billion parameter instruction-tuned language model developed by Microsoft using a dense decoder-only Transformer architecture. The model supports a 128,000 token context window and was trained on 4.9 trillion tokens of high-quality data, followed by supervised fine-tuning and direct preference optimization. It demonstrates competitive performance in reasoning, mathematics, and code generation tasks among models under 13 billion parameters, with particular strengths in long-context understanding and structured output generation.
Llama 3 8B is an open-weights transformer-based language model developed by Meta, featuring 8 billion parameters and trained on over 15 trillion tokens. The model utilizes grouped-query attention and a 128,000-token vocabulary, supporting 8,192-token context lengths. Available in both pretrained and instruction-tuned variants, it demonstrates capabilities in text generation, code completion, and conversational tasks across multiple languages.
Llama 4 Scout (17Bx16E) is a multimodal large language model developed by Meta using a Mixture-of-Experts transformer architecture with 109 billion total parameters and 17 billion active parameters per token. The model features a 10 million token context window, supports text and image understanding across multiple languages, and was trained on approximately 40 trillion tokens with an August 2024 knowledge cutoff.
Command R+ v01 is a 104-billion parameter open-weights language model developed by Cohere, optimized for retrieval-augmented generation, tool use, and multilingual tasks. The model features a 128,000-token context window and specializes in generating outputs with inline citations from retrieved documents. It supports automated tool calling, demonstrates competitive performance across standard benchmarks, and includes efficient tokenization for non-English languages, making it suitable for enterprise applications requiring factual accuracy and transparency.
Command R v01 is a 35-billion-parameter transformer-based language model developed by Cohere, featuring retrieval-augmented generation with explicit citations, tool use capabilities, and multilingual support across ten languages. The model supports a 128,000-token context window and demonstrates performance in enterprise applications, multi-step reasoning tasks, and long-context evaluations, though it requires commercial licensing for enterprise use.
Playground v2.5 Aesthetic is a diffusion-based text-to-image model that generates images at 1024x1024 resolution across multiple aspect ratios. Developed by Playground and released in February 2024, it employs the EDM training framework and human preference alignment techniques to improve color vibrancy, contrast, and human feature rendering compared to its predecessor and other open-source models like Stable Diffusion XL.
Stable Cascade Stage B is an intermediate latent super-resolution component within Stability AI's three-stage text-to-image generation system built on the Würstchen architecture. It operates as a diffusion model that upscales compressed 16×24×24 latents from Stage C to 4×256×256 representations, preserving semantic content while restoring fine details. Available in 700M and 1.5B parameter versions, Stage B enables the system's efficient 42:1 compression ratio and supports extensions like ControlNet and LoRA for enhanced creative workflows.
Stable Video Diffusion XT 1.1 is a latent diffusion model developed by Stability AI that generates 25-frame video sequences at 1024x576 resolution from single input images. The model employs a three-stage training process including image pretraining, video training on curated datasets, and high-resolution finetuning, enabling motion synthesis with configurable camera controls and temporal consistency for image-to-video transformation applications.
Qwen 1.5 72B is a 72-billion parameter transformer-based language model developed by Alibaba Cloud's Qwen Team and released in February 2024. The model supports a 32,768-token context window and demonstrates strong multilingual capabilities across 12 languages, achieving competitive performance on benchmarks including MMLU (77.5), C-Eval (84.1), and GSM8K (79.5). It features alignment optimization through Direct Policy Optimization and Proximal Policy Optimization techniques, enabling effective instruction-following and integration with external systems for applications including retrieval-augmented generation and code interpretation.
The SDXL Motion Model is an AnimateDiff-based video generation framework that adds temporal animation capabilities to existing text-to-image diffusion models. Built for compatibility with SDXL at 1024×1024 resolution, it employs a plug-and-play motion module trained on video datasets to generate coherent animated sequences while preserving the visual style of the underlying image model.
Phi-2 is a 2.7 billion parameter Transformer-based language model developed by Microsoft Research and released in December 2023. The model was trained on approximately 1.4 trillion tokens using a "textbook-quality" data approach, incorporating synthetic data from GPT-3.5 and filtered web sources. Phi-2 demonstrates competitive performance in reasoning, language understanding, and code generation tasks compared to larger models in its parameter class.
Mixtral 8x7B is a sparse Mixture of Experts language model developed by Mistral AI and released under the Apache 2.0 license in December 2023. The model uses a decoder-only transformer architecture with eight expert networks per layer, activating only two experts per token, resulting in 12.9 billion active parameters from a total 46.7 billion. It demonstrates competitive performance on benchmarks including MMLU, achieving multilingual capabilities across English, French, German, Spanish, and Italian while maintaining efficient inference speeds.
Playground v2 Aesthetic is a latent diffusion text-to-image model developed by playgroundai that generates 1024x1024 pixel images using dual pre-trained text encoders (OpenCLIP-ViT/G and CLIP-ViT/L). The model achieved a 7.07 FID score on the MJHQ-30K benchmark and demonstrated a 2.5x preference rate over Stable Diffusion XL in user studies, focusing on high-aesthetic image synthesis with strong prompt alignment.
Stable Video Diffusion XT is a generative AI model developed by Stability AI that extends the Stable Diffusion architecture for video synthesis. The model supports image-to-video and text-to-video generation, producing up to 25 frames at resolutions supporting 3-30 fps. Built on a latent video diffusion architecture with over 1.5 billion parameters, SVD-XT incorporates temporal modeling layers and was trained using a three-stage methodology on curated video datasets.
Yi 1 34B is a bilingual transformer-based language model developed by 01.AI, trained on 3 trillion tokens with support for both English and Chinese. The model features a 4,096-token context window and demonstrates competitive performance on multilingual benchmarks including MMLU, CMMLU, and C-Eval, with variants available including extended 200K context and chat-optimized versions released under Apache 2.0 license.
MusicGen is a text-to-music generation model developed by Meta's FAIR team as part of the AudioCraft library. The model uses a two-stage architecture combining EnCodec neural audio compression with a transformer-based autoregressive language model to generate musical audio from textual descriptions or melody inputs. Trained on approximately 20,000 hours of licensed music, MusicGen supports both monophonic and stereophonic outputs and demonstrates competitive performance in objective and subjective evaluations against contemporary music generation models.
Vocos is a neural vocoder developed by GemeloAI that employs a Fourier-based architecture to generate Short-Time Fourier Transform spectral coefficients rather than directly modeling time-domain waveforms. The model supports both mel-spectrogram and neural audio codec token inputs, operates under the MIT license, and demonstrates computational efficiency through its use of inverse STFT for audio reconstruction while achieving competitive performance metrics on speech and music synthesis tasks.
CodeLlama 34B is a large language model developed by Meta that builds upon Llama 2's architecture and is optimized for code generation, understanding, and programming tasks. The model supports multiple programming languages including Python, C++, Java, and JavaScript, with an extended context window of up to 100,000 tokens for handling large codebases. Available in three variants (Base, Python-specialized, and Instruct), it achieved 53.7% accuracy on HumanEval and 56.2% on MBPP benchmarks, demonstrating capabilities in code completion, debugging, and natural language explanations.
Llama 2 7B is a transformer-based language model developed by Meta with 7 billion parameters, trained on 2 trillion tokens with a 4,096-token context length. The model supports text generation in English and 27 other languages, with chat-optimized variants fine-tuned using supervised learning and reinforcement learning from human feedback for dialogue applications.
Llama 2 70B is a 70-billion parameter transformer-based language model developed by Meta, featuring Grouped-Query Attention and a 4096-token context window. Trained on 2 trillion tokens with a September 2022 cutoff, it demonstrates strong performance across language benchmarks including 68.9 on MMLU and 37.5 pass@1 on code generation tasks, while offering both pretrained and chat-optimized variants under Meta's commercial license.
Bark is a transformer-based text-to-audio model that generates multilingual speech, music, and sound effects by converting text directly to audio tokens using EnCodec quantization. The model supports over 13 languages with 100+ speaker presets and can produce nonverbal sounds like laughter through special tokens, operating via a three-stage pipeline from semantic to fine audio tokens.
LLaMA 13B is a transformer-based language model developed by Meta as part of the LLaMA model family, featuring 13 billion parameters and trained on 1.4 trillion tokens from publicly available datasets. The model incorporates architectural optimizations including RMSNorm, SwiGLU activation functions, and rotary positional embeddings, achieving competitive performance with larger models while maintaining efficiency. Released under a noncommercial research license, it demonstrates capabilities across language understanding, reasoning, and code generation benchmarks.
LLaMA 65B is a 65.2 billion parameter transformer-based language model developed by Meta and released in February 2023. The model utilizes architectural optimizations including RMSNorm pre-normalization, SwiGLU activation functions, and rotary positional embeddings. Trained exclusively on 1.4 trillion tokens from publicly available datasets including CommonCrawl, Wikipedia, GitHub, and arXiv, it demonstrates competitive performance across natural language understanding benchmarks while being distributed under a non-commercial research license.
Stable Diffusion 2 is an open-source text-to-image diffusion model developed by Stability AI that generates images at resolutions up to 768×768 pixels using latent diffusion techniques. The model employs an OpenCLIP-ViT/H text encoder and was trained on filtered subsets of the LAION-5B dataset. It includes specialized variants for inpainting, depth-conditioned generation, and 4x upscaling, offering improved capabilities over earlier versions while maintaining open accessibility for research applications.
Stable Diffusion 1.5 is a latent text-to-image diffusion model that generates 512x512 images from text prompts using a U-Net architecture conditioned on CLIP text embeddings within a compressed latent space. Trained on LAION dataset subsets, the model supports text-to-image generation, image-to-image translation, and inpainting tasks, released under the CreativeML OpenRAIL-M license for research and commercial applications.
Stable Diffusion 1.1 is a latent text-to-image diffusion model developed by CompVis, Stability AI, and Runway that generates images from natural language prompts. The model uses a VAE to compress images into latent space, a U-Net for denoising, and a CLIP text encoder for conditioning. Trained on LAION dataset subsets at 512×512 resolution, it supports text-to-image generation, image-to-image translation, and inpainting applications while operating efficiently in compressed latent space.
Kimi K2 is an open-source mixture-of-experts language model developed by Moonshot AI, featuring 1 trillion total parameters with 32 billion activated per inference. The model utilizes a 128,000-token context window and specializes in agentic intelligence, tool use, and autonomous reasoning capabilities. Trained on 15.5 trillion tokens with reinforcement learning techniques, it demonstrates performance across coding, mathematical reasoning, and multi-step task execution benchmarks.
Gemma 3n E4B is a multimodal generative AI model developed by Google DeepMind with 8 billion raw parameters yielding 4 billion effective parameters. Built on the MatFormer architecture for mobile and edge deployment, it processes text, image, audio, and video inputs to generate text outputs. The model features elastic inference capabilities, allowing extraction of smaller sub-models for faster performance, and supports over 140 languages with demonstrated proficiency in reasoning, coding, and multilingual tasks.
DeepSeek R1 (0528) is a large language model developed by DeepSeek-AI featuring 671 billion total parameters with 37 billion activated during inference. Built on the DeepSeek-V3-Base architecture using Mixture-of-Experts design, it employs Group Relative Policy Optimization and multi-stage training with reinforcement learning to enhance reasoning capabilities. The model supports 128,000 token context length and demonstrates improved performance on mathematical, coding, and reasoning benchmarks compared to its predecessors.
Qwen3-0.6B is a dense language model with 0.6 billion parameters developed by Alibaba Cloud, featuring a 28-layer transformer architecture with Grouped Query Attention. The model supports dual thinking modes for adaptive reasoning and general dialogue, processes up to 32,768 tokens context length, and demonstrates multilingual capabilities across over 100 languages. It utilizes strong-to-weak distillation from larger Qwen3 models and is released under Apache 2.0 license.
Qwen3-4B is a 4.0 billion parameter transformer language model developed by Alibaba Cloud, featuring dual reasoning modes that allow users to toggle between detailed step-by-step thinking and rapid response generation. Released under Apache 2.0 license, the model supports 32,768 token contexts, demonstrates strong performance across mathematical reasoning and coding benchmarks, and incorporates advanced training techniques including strong-to-weak distillation from larger teacher models.
Qwen3-14B is a dense transformer language model developed by Alibaba Cloud with 14.8 billion parameters, featuring hybrid "thinking" and "non-thinking" reasoning modes that can be controlled via prompts. The model supports 119 languages, extends to 131k token contexts through YaRN scaling, and includes agent capabilities with tool-use functionality, all released under Apache 2.0 license.
Qwen3-30B-A3B is a Mixture-of-Experts language model developed by Alibaba Cloud featuring 30.5 billion total parameters with 3.3 billion activated per token. The model employs hybrid reasoning modes that allow dynamic switching between step-by-step thinking for complex tasks and rapid responses for simpler queries. It supports 119 languages, extends to 131,072 tokens context length, and utilizes strong-to-weak distillation from larger Qwen3 models for efficient deployment while maintaining competitive performance on reasoning, coding, and multilingual benchmarks.
HiDream I1 Full is an open-source image generation model developed by HiDream.ai featuring a 17 billion parameter sparse Diffusion Transformer architecture with Mixture-of-Experts design. The model employs hybrid text encoding combining Long-CLIP, T5-XXL, and Llama 3.1 8B components for precise text-to-image synthesis. It demonstrates strong performance on industry benchmarks and supports diverse visual styles through flow-matching in latent space.
Mistral Small 3.1 (2503) is a 24-billion parameter transformer-based model developed by Mistral AI and released under Apache 2.0 license. This multimodal and multilingual model processes both text and visual inputs with a context window of 128,000 tokens using the Tekken tokenizer. It demonstrates competitive performance on academic benchmarks including MMLU and GPQA while supporting function calling and structured output generation for automation workflows.
Gemma 3 4B is a multimodal instruction-tuned model developed by Google DeepMind that processes text and image inputs to generate text outputs. The model features a decoder-only transformer architecture with approximately 4.3 billion parameters, supports context windows up to 128,000 tokens, and operates across over 140 languages. It incorporates a SigLIP vision encoder for image processing and utilizes grouped-query attention with interleaved local and global attention layers for efficient long-context handling.
Gemma 3 27B is a multimodal generative AI model developed by Google DeepMind that processes both text and image inputs to produce text outputs. Built on a decoder-only transformer architecture with 27 billion parameters, it incorporates a SigLIP vision encoder and supports context lengths up to 128,000 tokens. The model was trained on over 14 trillion tokens and demonstrates competitive performance across language, coding, mathematical reasoning, and vision-language tasks.
QwQ 32B is a 32.5-billion parameter causal language model developed by Alibaba Cloud as part of the Qwen series. The model employs a transformer architecture with 64 layers and Grouped Query Attention, trained using supervised fine-tuning and reinforcement learning focused on mathematical reasoning and coding proficiency. Released under Apache 2.0 license, it demonstrates competitive performance on reasoning benchmarks despite its relatively compact size.
Wan 2.1 I2V 14B 480P is an image-to-video generation model developed by Wan-AI featuring 14 billion parameters and operating at 480P resolution. Built on a diffusion transformer architecture with T5-based text encoding and a 3D causal variational autoencoder, the model transforms static images into temporally coherent video sequences guided by textual prompts, supporting both Chinese and English text rendering within its generative capabilities.
Wan 2.1 T2V 14B is a 14-billion parameter video generation model developed by Wan-AI that creates videos from text descriptions or images. The model employs a spatio-temporal variational autoencoder and diffusion transformer architecture to generate content at 480P and 720P resolutions. It supports multiple languages including Chinese and English, handles various video generation tasks, and demonstrates computational efficiency across different hardware configurations when deployed for research applications.
Qwen2.5 VL 7B is a 7-billion parameter multimodal language model developed by Alibaba Cloud that processes text, images, and video inputs. The model features a Vision Transformer with dynamic resolution support and Multimodal Rotary Position Embedding for spatial-temporal understanding. It demonstrates capabilities in document analysis, OCR, object detection, video comprehension, and structured output generation across multiple languages, released under Apache-2.0 license.
Lumina Image 2.0 is a 2 billion parameter text-to-image generative model developed by Alpha-VLLM that utilizes a flow-based diffusion transformer architecture. The model generates high-fidelity images up to 1024x1024 pixels from textual descriptions, employs a Gemma-2-2B text encoder and FLUX-VAE-16CH variational autoencoder, and is released under the Apache-2.0 license with support for multiple inference solvers and fine-tuning capabilities.
MiniMax Text 01 is an open-source large language model developed by MiniMaxAI featuring 456 billion total parameters with 45.9 billion active per token. The model employs a hybrid attention mechanism combining Lightning Attention with periodic Softmax Attention layers across 80 transformer layers, utilizing a Mixture-of-Experts design with 32 experts and Top-2 routing. It supports context lengths up to 4 million tokens during inference and demonstrates competitive performance across text generation, reasoning, and coding benchmarks.
DeepSeek-VL2 is a series of Mixture-of-Experts vision-language models developed by DeepSeek-AI that integrates visual and textual understanding through a decoder-only architecture. The models utilize a SigLIP vision encoder with dynamic tiling for high-resolution image processing, coupled with DeepSeekMoE language components featuring Multi-head Latent Attention. Available in three variants with 1.0B, 2.8B, and 4.5B activated parameters, the models support multimodal tasks including visual question answering, optical character recognition, document analysis, and visual grounding capabilities.
DeepSeek VL2 Tiny is a vision-language model from Deepseek AI that activates 1.0 billion parameters using Mixture-of-Experts architecture. The model combines a SigLIP vision encoder with a DeepSeekMoE-based language component to handle multimodal tasks including visual question answering, optical character recognition, document analysis, and visual grounding across images and text.
Llama 3.3 70B is a 70-billion parameter transformer-based language model developed by Meta, featuring instruction tuning through supervised fine-tuning and reinforcement learning from human feedback. The model supports a 128,000-token context window, incorporates Grouped-Query Attention for enhanced inference efficiency, and demonstrates multilingual capabilities across eight validated languages including English, German, French, Italian, Portuguese, Hindi, Spanish, and Thai.
CogVideoX 1.5 5B is an open-source video generation model developed by THUDM that creates high-resolution videos up to 1360x768 resolution from text prompts and images. The model employs a 3D causal variational autoencoder with 8x8x4 compression and an expert transformer architecture featuring adaptive LayerNorm for multimodal alignment. It supports both text-to-video and image-to-video synthesis with durations of 5-10 seconds at 16 fps, released under Apache 2.0 license.
QwQ 32B Preview is an experimental large language model developed by Alibaba Cloud's Qwen Team, built on the Qwen 2 architecture with 32.5 billion parameters. The model specializes in mathematical and coding reasoning tasks, achieving 65.2% on GPQA, 50.0% on AIME, 90.6% on MATH-500, and 50.0% on LiveCodeBench benchmarks through curiosity-driven, reflective analysis approaches.
Stable Diffusion 3.5 Large is an 8.1-billion-parameter text-to-image model utilizing Multimodal Diffusion Transformer architecture with Query-Key Normalization for enhanced training stability. The model generates images up to 1-megapixel resolution across diverse styles including photorealism, illustration, and digital art. It employs three text encoders supporting up to 256 tokens and demonstrates strong prompt adherence capabilities.
CogVideoX-5B-I2V is an open-source image-to-video generative AI model developed by THUDM that produces 6-second videos at 720×480 resolution from input images and English text prompts. The model employs a diffusion transformer architecture with 3D Causal VAE compression and generates 49 frames at 8 fps, supporting various video synthesis applications through its controllable conditioning mechanism.
Qwen 2.5 Math 7B is a 7.62-billion parameter language model developed by Alibaba Cloud that specializes in mathematical reasoning tasks in English and Chinese. The model employs chain-of-thought reasoning and tool-integrated approaches using Python interpreters for computational tasks. It demonstrates improved performance over its predecessor on mathematical benchmarks including MATH, GSM8K, and Chinese mathematics evaluations, achieving 83.6 on MATH using chain-of-thought methods.
Qwen2.5-Coder-7B is a 7.61 billion parameter transformer-based language model developed by Alibaba Cloud's Qwen Team, specialized for code generation and reasoning across 92 programming languages. The model features a 128,000-token context window, supports fill-in-the-middle code completion, and was trained on 5.5 trillion tokens of code and text data, demonstrating competitive performance on coding benchmarks like HumanEval and mathematical reasoning tasks.
Qwen 2.5 14B is a 14.7 billion parameter transformer-based language model developed by Alibaba Cloud's Qwen Team, featuring a 128,000 token context window and support for over 29 languages. The model utilizes advanced architectural components including Grouped Query Attention, RoPE embeddings, and SwiGLU activation, and was pretrained on up to 18 trillion tokens of diverse multilingual data for applications in reasoning, coding, and mathematical tasks.
Qwen 2.5 72B is a 72.7 billion parameter transformer-based language model developed by Alibaba Cloud's Qwen Team, released in September 2024. The model features a 128,000-token context window, supports over 29 languages, and demonstrates strong performance on coding, mathematical reasoning, and knowledge benchmarks. Built with architectural improvements including RoPE and SwiGLU activation functions, it excels at structured data handling and serves as a foundation model for fine-tuning applications.
Command R (08-2024) is a 32-billion parameter generative language model developed by Cohere, featuring a 128,000-token context window and support for 23 languages. The model incorporates Grouped Query Attention for enhanced inference efficiency and specializes in retrieval-augmented generation with citation capabilities, tool use, and multilingual comprehension. It demonstrates improved throughput and reduced latency compared to previous versions while offering configurable safety modes for enterprise applications.
Phi-3.5 Mini Instruct is a 3.8 billion parameter decoder-only Transformer model developed by Microsoft that supports multilingual text generation with a 128,000-token context window. The model demonstrates competitive performance across 22 languages and excels in reasoning, code generation, and long-context tasks, achieving an average benchmark score of 61.4 while maintaining efficient resource utilization.
AuraFlow v0.3 is a 6.8 billion parameter, flow-based text-to-image generative model developed by fal.ai. Built on an optimized DiT architecture with Maximal Update Parametrization, it features enhanced prompt following capabilities through comprehensive recaptioning and prompt enhancement pipelines. The model supports multiple aspect ratios and achieved a GenEval score of 0.703, demonstrating effective text-to-image synthesis across diverse artistic styles and photorealistic outputs.
Stable Fast 3D is a transformer-based generative AI model developed by Stability AI that reconstructs textured 3D mesh assets from single input images in approximately 0.5 seconds. The model predicts comprehensive material properties including albedo, roughness, and metallicity, producing UV-unwrapped meshes suitable for integration into rendering pipelines and interactive applications across gaming, virtual reality, and design workflows.
FLUX.1 [schnell] is a 12-billion parameter text-to-image generation model developed by Black Forest Labs using hybrid diffusion transformer architecture with rectified flow and latent adversarial diffusion distillation. The model generates images from text descriptions in 1-4 diffusion steps, supporting variable resolutions and aspect ratios. Released under Apache 2.0 license, it employs flow matching techniques and parallel attention layers for efficient synthesis.
Mistral Large 2 is a dense transformer-based language model developed by Mistral AI with 123 billion parameters and a 128,000-token context window. The model demonstrates strong performance across multilingual tasks, code generation in 80+ programming languages, mathematical reasoning, and function calling capabilities. It achieves 84% on MMLU, 92% on HumanEval, and 93% on GSM8K benchmarks while maintaining concise output generation.
Mistral NeMo 12B is a transformer-based language model developed collaboratively by Mistral AI and NVIDIA, featuring 12 billion parameters and a 128,000-token context window. The model incorporates grouped query attention, quantization-aware training for FP8 inference, and utilizes the custom Tekken tokenizer for improved multilingual and code compression efficiency. Available in both base and instruction-tuned variants, it demonstrates competitive performance on standard benchmarks while supporting function calling and multilingual capabilities across numerous languages including English, Chinese, Arabic, and various European languages.
Llama 3.1 70B is a transformer-based decoder language model developed by Meta with 70 billion parameters, trained on approximately 15 trillion tokens with a 128K context window. The model supports eight languages and demonstrates competitive performance across benchmarks for reasoning, coding, mathematics, and multilingual tasks. It is available under the Llama 3.1 Community License Agreement for research and commercial applications.
Gemma 2 9B is an open-weights decoder-only transformer language model developed by Google as part of the Gemma family. Trained on 8 trillion tokens using TPUv5p infrastructure, the model supports English text generation, question answering, and summarization tasks. Available in both pre-trained and instruction-tuned versions with bfloat16 precision, it demonstrates competitive performance on benchmarks like MMLU and coding evaluations while incorporating safety filtering mechanisms.
DeepSeek Coder V2 Lite is an open-source Mixture-of-Experts code language model featuring 16 billion total parameters with 2.4 billion active parameters during inference. The model supports 338 programming languages, processes up to 128,000 tokens of context, and demonstrates competitive performance on code generation benchmarks including 81.1% accuracy on Python HumanEval tasks.
Qwen2-72B is a 72.71 billion parameter Transformer-based language model developed by Alibaba Cloud, featuring Group Query Attention and SwiGLU activation functions. The model demonstrates strong performance across diverse benchmarks including MMLU (84.2), HumanEval (64.6), and GSM8K (89.5), with multilingual capabilities spanning 27 languages and extended context handling up to 128,000 tokens for specialized applications.
Yi 1.5 34B is a 34.4 billion parameter decoder-only Transformer language model developed by 01.AI, featuring Grouped-Query Attention and SwiGLU activations. Trained on 3.1 trillion bilingual tokens, it demonstrates capabilities in reasoning, mathematics, and code generation, with variants supporting up to 200,000 token contexts and multimodal understanding through vision-language extensions.
DeepSeek V2 is a large-scale Mixture-of-Experts language model with 236 billion total parameters, activating only 21 billion per token. It features Multi-head Latent Attention for reduced memory usage and supports context lengths up to 128,000 tokens. Trained on 8.1 trillion tokens with emphasis on English and Chinese data, it demonstrates competitive performance across language understanding, code generation, and mathematical reasoning tasks while achieving significant efficiency improvements over dense models.
Phi-3 Mini Instruct is a 3.8 billion parameter instruction-tuned language model developed by Microsoft using a dense decoder-only Transformer architecture. The model supports a 128,000 token context window and was trained on 4.9 trillion tokens of high-quality data, followed by supervised fine-tuning and direct preference optimization. It demonstrates competitive performance in reasoning, mathematics, and code generation tasks among models under 13 billion parameters, with particular strengths in long-context understanding and structured output generation.
Llama 3 8B is an open-weights transformer-based language model developed by Meta, featuring 8 billion parameters and trained on over 15 trillion tokens. The model utilizes grouped-query attention and a 128,000-token vocabulary, supporting 8,192-token context lengths. Available in both pretrained and instruction-tuned variants, it demonstrates capabilities in text generation, code completion, and conversational tasks across multiple languages.
Llama 4 Scout (17Bx16E) is a multimodal large language model developed by Meta using a Mixture-of-Experts transformer architecture with 109 billion total parameters and 17 billion active parameters per token. The model features a 10 million token context window, supports text and image understanding across multiple languages, and was trained on approximately 40 trillion tokens with an August 2024 knowledge cutoff.
Command R+ v01 is a 104-billion parameter open-weights language model developed by Cohere, optimized for retrieval-augmented generation, tool use, and multilingual tasks. The model features a 128,000-token context window and specializes in generating outputs with inline citations from retrieved documents. It supports automated tool calling, demonstrates competitive performance across standard benchmarks, and includes efficient tokenization for non-English languages, making it suitable for enterprise applications requiring factual accuracy and transparency.
Command R v01 is a 35-billion-parameter transformer-based language model developed by Cohere, featuring retrieval-augmented generation with explicit citations, tool use capabilities, and multilingual support across ten languages. The model supports a 128,000-token context window and demonstrates performance in enterprise applications, multi-step reasoning tasks, and long-context evaluations, though it requires commercial licensing for enterprise use.
Playground v2.5 Aesthetic is a diffusion-based text-to-image model that generates images at 1024x1024 resolution across multiple aspect ratios. Developed by Playground and released in February 2024, it employs the EDM training framework and human preference alignment techniques to improve color vibrancy, contrast, and human feature rendering compared to its predecessor and other open-source models like Stable Diffusion XL.
Stable Cascade Stage B is an intermediate latent super-resolution component within Stability AI's three-stage text-to-image generation system built on the Würstchen architecture. It operates as a diffusion model that upscales compressed 16×24×24 latents from Stage C to 4×256×256 representations, preserving semantic content while restoring fine details. Available in 700M and 1.5B parameter versions, Stage B enables the system's efficient 42:1 compression ratio and supports extensions like ControlNet and LoRA for enhanced creative workflows.
Stable Video Diffusion XT 1.1 is a latent diffusion model developed by Stability AI that generates 25-frame video sequences at 1024x576 resolution from single input images. The model employs a three-stage training process including image pretraining, video training on curated datasets, and high-resolution finetuning, enabling motion synthesis with configurable camera controls and temporal consistency for image-to-video transformation applications.
Qwen 1.5 72B is a 72-billion parameter transformer-based language model developed by Alibaba Cloud's Qwen Team and released in February 2024. The model supports a 32,768-token context window and demonstrates strong multilingual capabilities across 12 languages, achieving competitive performance on benchmarks including MMLU (77.5), C-Eval (84.1), and GSM8K (79.5). It features alignment optimization through Direct Policy Optimization and Proximal Policy Optimization techniques, enabling effective instruction-following and integration with external systems for applications including retrieval-augmented generation and code interpretation.
The SDXL Motion Model is an AnimateDiff-based video generation framework that adds temporal animation capabilities to existing text-to-image diffusion models. Built for compatibility with SDXL at 1024×1024 resolution, it employs a plug-and-play motion module trained on video datasets to generate coherent animated sequences while preserving the visual style of the underlying image model.
Phi-2 is a 2.7 billion parameter Transformer-based language model developed by Microsoft Research and released in December 2023. The model was trained on approximately 1.4 trillion tokens using a "textbook-quality" data approach, incorporating synthetic data from GPT-3.5 and filtered web sources. Phi-2 demonstrates competitive performance in reasoning, language understanding, and code generation tasks compared to larger models in its parameter class.
Mixtral 8x7B is a sparse Mixture of Experts language model developed by Mistral AI and released under the Apache 2.0 license in December 2023. The model uses a decoder-only transformer architecture with eight expert networks per layer, activating only two experts per token, resulting in 12.9 billion active parameters from a total 46.7 billion. It demonstrates competitive performance on benchmarks including MMLU, achieving multilingual capabilities across English, French, German, Spanish, and Italian while maintaining efficient inference speeds.
Playground v2 Aesthetic is a latent diffusion text-to-image model developed by playgroundai that generates 1024x1024 pixel images using dual pre-trained text encoders (OpenCLIP-ViT/G and CLIP-ViT/L). The model achieved a 7.07 FID score on the MJHQ-30K benchmark and demonstrated a 2.5x preference rate over Stable Diffusion XL in user studies, focusing on high-aesthetic image synthesis with strong prompt alignment.
Stable Video Diffusion XT is a generative AI model developed by Stability AI that extends the Stable Diffusion architecture for video synthesis. The model supports image-to-video and text-to-video generation, producing up to 25 frames at resolutions supporting 3-30 fps. Built on a latent video diffusion architecture with over 1.5 billion parameters, SVD-XT incorporates temporal modeling layers and was trained using a three-stage methodology on curated video datasets.
Yi 1 34B is a bilingual transformer-based language model developed by 01.AI, trained on 3 trillion tokens with support for both English and Chinese. The model features a 4,096-token context window and demonstrates competitive performance on multilingual benchmarks including MMLU, CMMLU, and C-Eval, with variants available including extended 200K context and chat-optimized versions released under Apache 2.0 license.
MusicGen is a text-to-music generation model developed by Meta's FAIR team as part of the AudioCraft library. The model uses a two-stage architecture combining EnCodec neural audio compression with a transformer-based autoregressive language model to generate musical audio from textual descriptions or melody inputs. Trained on approximately 20,000 hours of licensed music, MusicGen supports both monophonic and stereophonic outputs and demonstrates competitive performance in objective and subjective evaluations against contemporary music generation models.
Vocos is a neural vocoder developed by GemeloAI that employs a Fourier-based architecture to generate Short-Time Fourier Transform spectral coefficients rather than directly modeling time-domain waveforms. The model supports both mel-spectrogram and neural audio codec token inputs, operates under the MIT license, and demonstrates computational efficiency through its use of inverse STFT for audio reconstruction while achieving competitive performance metrics on speech and music synthesis tasks.
CodeLlama 34B is a large language model developed by Meta that builds upon Llama 2's architecture and is optimized for code generation, understanding, and programming tasks. The model supports multiple programming languages including Python, C++, Java, and JavaScript, with an extended context window of up to 100,000 tokens for handling large codebases. Available in three variants (Base, Python-specialized, and Instruct), it achieved 53.7% accuracy on HumanEval and 56.2% on MBPP benchmarks, demonstrating capabilities in code completion, debugging, and natural language explanations.
Llama 2 7B is a transformer-based language model developed by Meta with 7 billion parameters, trained on 2 trillion tokens with a 4,096-token context length. The model supports text generation in English and 27 other languages, with chat-optimized variants fine-tuned using supervised learning and reinforcement learning from human feedback for dialogue applications.
Llama 2 70B is a 70-billion parameter transformer-based language model developed by Meta, featuring Grouped-Query Attention and a 4096-token context window. Trained on 2 trillion tokens with a September 2022 cutoff, it demonstrates strong performance across language benchmarks including 68.9 on MMLU and 37.5 pass@1 on code generation tasks, while offering both pretrained and chat-optimized variants under Meta's commercial license.
Bark is a transformer-based text-to-audio model that generates multilingual speech, music, and sound effects by converting text directly to audio tokens using EnCodec quantization. The model supports over 13 languages with 100+ speaker presets and can produce nonverbal sounds like laughter through special tokens, operating via a three-stage pipeline from semantic to fine audio tokens.
LLaMA 13B is a transformer-based language model developed by Meta as part of the LLaMA model family, featuring 13 billion parameters and trained on 1.4 trillion tokens from publicly available datasets. The model incorporates architectural optimizations including RMSNorm, SwiGLU activation functions, and rotary positional embeddings, achieving competitive performance with larger models while maintaining efficiency. Released under a noncommercial research license, it demonstrates capabilities across language understanding, reasoning, and code generation benchmarks.
LLaMA 65B is a 65.2 billion parameter transformer-based language model developed by Meta and released in February 2023. The model utilizes architectural optimizations including RMSNorm pre-normalization, SwiGLU activation functions, and rotary positional embeddings. Trained exclusively on 1.4 trillion tokens from publicly available datasets including CommonCrawl, Wikipedia, GitHub, and arXiv, it demonstrates competitive performance across natural language understanding benchmarks while being distributed under a non-commercial research license.
Stable Diffusion 2 is an open-source text-to-image diffusion model developed by Stability AI that generates images at resolutions up to 768×768 pixels using latent diffusion techniques. The model employs an OpenCLIP-ViT/H text encoder and was trained on filtered subsets of the LAION-5B dataset. It includes specialized variants for inpainting, depth-conditioned generation, and 4x upscaling, offering improved capabilities over earlier versions while maintaining open accessibility for research applications.
Stable Diffusion 1.5 is a latent text-to-image diffusion model that generates 512x512 images from text prompts using a U-Net architecture conditioned on CLIP text embeddings within a compressed latent space. Trained on LAION dataset subsets, the model supports text-to-image generation, image-to-image translation, and inpainting tasks, released under the CreativeML OpenRAIL-M license for research and commercial applications.
Stable Diffusion 1.1 is a latent text-to-image diffusion model developed by CompVis, Stability AI, and Runway that generates images from natural language prompts. The model uses a VAE to compress images into latent space, a U-Net for denoising, and a CLIP text encoder for conditioning. Trained on LAION dataset subsets at 512×512 resolution, it supports text-to-image generation, image-to-image translation, and inpainting applications while operating efficiently in compressed latent space.
Kimi K2 is an open-source mixture-of-experts language model developed by Moonshot AI, featuring 1 trillion total parameters with 32 billion activated per inference. The model utilizes a 128,000-token context window and specializes in agentic intelligence, tool use, and autonomous reasoning capabilities. Trained on 15.5 trillion tokens with reinforcement learning techniques, it demonstrates performance across coding, mathematical reasoning, and multi-step task execution benchmarks.
Gemma 3n E4B is a multimodal generative AI model developed by Google DeepMind with 8 billion raw parameters yielding 4 billion effective parameters. Built on the MatFormer architecture for mobile and edge deployment, it processes text, image, audio, and video inputs to generate text outputs. The model features elastic inference capabilities, allowing extraction of smaller sub-models for faster performance, and supports over 140 languages with demonstrated proficiency in reasoning, coding, and multilingual tasks.
DeepSeek R1 (0528) is a large language model developed by DeepSeek-AI featuring 671 billion total parameters with 37 billion activated during inference. Built on the DeepSeek-V3-Base architecture using Mixture-of-Experts design, it employs Group Relative Policy Optimization and multi-stage training with reinforcement learning to enhance reasoning capabilities. The model supports 128,000 token context length and demonstrates improved performance on mathematical, coding, and reasoning benchmarks compared to its predecessors.
Qwen3-0.6B is a dense language model with 0.6 billion parameters developed by Alibaba Cloud, featuring a 28-layer transformer architecture with Grouped Query Attention. The model supports dual thinking modes for adaptive reasoning and general dialogue, processes up to 32,768 tokens context length, and demonstrates multilingual capabilities across over 100 languages. It utilizes strong-to-weak distillation from larger Qwen3 models and is released under Apache 2.0 license.
Qwen3-4B is a 4.0 billion parameter transformer language model developed by Alibaba Cloud, featuring dual reasoning modes that allow users to toggle between detailed step-by-step thinking and rapid response generation. Released under Apache 2.0 license, the model supports 32,768 token contexts, demonstrates strong performance across mathematical reasoning and coding benchmarks, and incorporates advanced training techniques including strong-to-weak distillation from larger teacher models.
Qwen3-14B is a dense transformer language model developed by Alibaba Cloud with 14.8 billion parameters, featuring hybrid "thinking" and "non-thinking" reasoning modes that can be controlled via prompts. The model supports 119 languages, extends to 131k token contexts through YaRN scaling, and includes agent capabilities with tool-use functionality, all released under Apache 2.0 license.
Qwen3-30B-A3B is a Mixture-of-Experts language model developed by Alibaba Cloud featuring 30.5 billion total parameters with 3.3 billion activated per token. The model employs hybrid reasoning modes that allow dynamic switching between step-by-step thinking for complex tasks and rapid responses for simpler queries. It supports 119 languages, extends to 131,072 tokens context length, and utilizes strong-to-weak distillation from larger Qwen3 models for efficient deployment while maintaining competitive performance on reasoning, coding, and multilingual benchmarks.
HiDream I1 Full is an open-source image generation model developed by HiDream.ai featuring a 17 billion parameter sparse Diffusion Transformer architecture with Mixture-of-Experts design. The model employs hybrid text encoding combining Long-CLIP, T5-XXL, and Llama 3.1 8B components for precise text-to-image synthesis. It demonstrates strong performance on industry benchmarks and supports diverse visual styles through flow-matching in latent space.
Mistral Small 3.1 (2503) is a 24-billion parameter transformer-based model developed by Mistral AI and released under Apache 2.0 license. This multimodal and multilingual model processes both text and visual inputs with a context window of 128,000 tokens using the Tekken tokenizer. It demonstrates competitive performance on academic benchmarks including MMLU and GPQA while supporting function calling and structured output generation for automation workflows.
Gemma 3 4B is a multimodal instruction-tuned model developed by Google DeepMind that processes text and image inputs to generate text outputs. The model features a decoder-only transformer architecture with approximately 4.3 billion parameters, supports context windows up to 128,000 tokens, and operates across over 140 languages. It incorporates a SigLIP vision encoder for image processing and utilizes grouped-query attention with interleaved local and global attention layers for efficient long-context handling.
Gemma 3 27B is a multimodal generative AI model developed by Google DeepMind that processes both text and image inputs to produce text outputs. Built on a decoder-only transformer architecture with 27 billion parameters, it incorporates a SigLIP vision encoder and supports context lengths up to 128,000 tokens. The model was trained on over 14 trillion tokens and demonstrates competitive performance across language, coding, mathematical reasoning, and vision-language tasks.
QwQ 32B is a 32.5-billion parameter causal language model developed by Alibaba Cloud as part of the Qwen series. The model employs a transformer architecture with 64 layers and Grouped Query Attention, trained using supervised fine-tuning and reinforcement learning focused on mathematical reasoning and coding proficiency. Released under Apache 2.0 license, it demonstrates competitive performance on reasoning benchmarks despite its relatively compact size.
Wan 2.1 I2V 14B 480P is an image-to-video generation model developed by Wan-AI featuring 14 billion parameters and operating at 480P resolution. Built on a diffusion transformer architecture with T5-based text encoding and a 3D causal variational autoencoder, the model transforms static images into temporally coherent video sequences guided by textual prompts, supporting both Chinese and English text rendering within its generative capabilities.
Wan 2.1 T2V 14B is a 14-billion parameter video generation model developed by Wan-AI that creates videos from text descriptions or images. The model employs a spatio-temporal variational autoencoder and diffusion transformer architecture to generate content at 480P and 720P resolutions. It supports multiple languages including Chinese and English, handles various video generation tasks, and demonstrates computational efficiency across different hardware configurations when deployed for research applications.
Qwen2.5 VL 7B is a 7-billion parameter multimodal language model developed by Alibaba Cloud that processes text, images, and video inputs. The model features a Vision Transformer with dynamic resolution support and Multimodal Rotary Position Embedding for spatial-temporal understanding. It demonstrates capabilities in document analysis, OCR, object detection, video comprehension, and structured output generation across multiple languages, released under Apache-2.0 license.
Lumina Image 2.0 is a 2 billion parameter text-to-image generative model developed by Alpha-VLLM that utilizes a flow-based diffusion transformer architecture. The model generates high-fidelity images up to 1024x1024 pixels from textual descriptions, employs a Gemma-2-2B text encoder and FLUX-VAE-16CH variational autoencoder, and is released under the Apache-2.0 license with support for multiple inference solvers and fine-tuning capabilities.
MiniMax Text 01 is an open-source large language model developed by MiniMaxAI featuring 456 billion total parameters with 45.9 billion active per token. The model employs a hybrid attention mechanism combining Lightning Attention with periodic Softmax Attention layers across 80 transformer layers, utilizing a Mixture-of-Experts design with 32 experts and Top-2 routing. It supports context lengths up to 4 million tokens during inference and demonstrates competitive performance across text generation, reasoning, and coding benchmarks.
DeepSeek-VL2 is a series of Mixture-of-Experts vision-language models developed by DeepSeek-AI that integrates visual and textual understanding through a decoder-only architecture. The models utilize a SigLIP vision encoder with dynamic tiling for high-resolution image processing, coupled with DeepSeekMoE language components featuring Multi-head Latent Attention. Available in three variants with 1.0B, 2.8B, and 4.5B activated parameters, the models support multimodal tasks including visual question answering, optical character recognition, document analysis, and visual grounding capabilities.
DeepSeek VL2 Tiny is a vision-language model from Deepseek AI that activates 1.0 billion parameters using Mixture-of-Experts architecture. The model combines a SigLIP vision encoder with a DeepSeekMoE-based language component to handle multimodal tasks including visual question answering, optical character recognition, document analysis, and visual grounding across images and text.
Llama 3.3 70B is a 70-billion parameter transformer-based language model developed by Meta, featuring instruction tuning through supervised fine-tuning and reinforcement learning from human feedback. The model supports a 128,000-token context window, incorporates Grouped-Query Attention for enhanced inference efficiency, and demonstrates multilingual capabilities across eight validated languages including English, German, French, Italian, Portuguese, Hindi, Spanish, and Thai.
CogVideoX 1.5 5B is an open-source video generation model developed by THUDM that creates high-resolution videos up to 1360x768 resolution from text prompts and images. The model employs a 3D causal variational autoencoder with 8x8x4 compression and an expert transformer architecture featuring adaptive LayerNorm for multimodal alignment. It supports both text-to-video and image-to-video synthesis with durations of 5-10 seconds at 16 fps, released under Apache 2.0 license.
QwQ 32B Preview is an experimental large language model developed by Alibaba Cloud's Qwen Team, built on the Qwen 2 architecture with 32.5 billion parameters. The model specializes in mathematical and coding reasoning tasks, achieving 65.2% on GPQA, 50.0% on AIME, 90.6% on MATH-500, and 50.0% on LiveCodeBench benchmarks through curiosity-driven, reflective analysis approaches.
Stable Diffusion 3.5 Large is an 8.1-billion-parameter text-to-image model utilizing Multimodal Diffusion Transformer architecture with Query-Key Normalization for enhanced training stability. The model generates images up to 1-megapixel resolution across diverse styles including photorealism, illustration, and digital art. It employs three text encoders supporting up to 256 tokens and demonstrates strong prompt adherence capabilities.
CogVideoX-5B-I2V is an open-source image-to-video generative AI model developed by THUDM that produces 6-second videos at 720×480 resolution from input images and English text prompts. The model employs a diffusion transformer architecture with 3D Causal VAE compression and generates 49 frames at 8 fps, supporting various video synthesis applications through its controllable conditioning mechanism.
Qwen 2.5 Math 7B is a 7.62-billion parameter language model developed by Alibaba Cloud that specializes in mathematical reasoning tasks in English and Chinese. The model employs chain-of-thought reasoning and tool-integrated approaches using Python interpreters for computational tasks. It demonstrates improved performance over its predecessor on mathematical benchmarks including MATH, GSM8K, and Chinese mathematics evaluations, achieving 83.6 on MATH using chain-of-thought methods.
Qwen2.5-Coder-7B is a 7.61 billion parameter transformer-based language model developed by Alibaba Cloud's Qwen Team, specialized for code generation and reasoning across 92 programming languages. The model features a 128,000-token context window, supports fill-in-the-middle code completion, and was trained on 5.5 trillion tokens of code and text data, demonstrating competitive performance on coding benchmarks like HumanEval and mathematical reasoning tasks.
Qwen 2.5 14B is a 14.7 billion parameter transformer-based language model developed by Alibaba Cloud's Qwen Team, featuring a 128,000 token context window and support for over 29 languages. The model utilizes advanced architectural components including Grouped Query Attention, RoPE embeddings, and SwiGLU activation, and was pretrained on up to 18 trillion tokens of diverse multilingual data for applications in reasoning, coding, and mathematical tasks.
Qwen 2.5 72B is a 72.7 billion parameter transformer-based language model developed by Alibaba Cloud's Qwen Team, released in September 2024. The model features a 128,000-token context window, supports over 29 languages, and demonstrates strong performance on coding, mathematical reasoning, and knowledge benchmarks. Built with architectural improvements including RoPE and SwiGLU activation functions, it excels at structured data handling and serves as a foundation model for fine-tuning applications.
Command R (08-2024) is a 32-billion parameter generative language model developed by Cohere, featuring a 128,000-token context window and support for 23 languages. The model incorporates Grouped Query Attention for enhanced inference efficiency and specializes in retrieval-augmented generation with citation capabilities, tool use, and multilingual comprehension. It demonstrates improved throughput and reduced latency compared to previous versions while offering configurable safety modes for enterprise applications.
Phi-3.5 Mini Instruct is a 3.8 billion parameter decoder-only Transformer model developed by Microsoft that supports multilingual text generation with a 128,000-token context window. The model demonstrates competitive performance across 22 languages and excels in reasoning, code generation, and long-context tasks, achieving an average benchmark score of 61.4 while maintaining efficient resource utilization.
AuraFlow v0.3 is a 6.8 billion parameter, flow-based text-to-image generative model developed by fal.ai. Built on an optimized DiT architecture with Maximal Update Parametrization, it features enhanced prompt following capabilities through comprehensive recaptioning and prompt enhancement pipelines. The model supports multiple aspect ratios and achieved a GenEval score of 0.703, demonstrating effective text-to-image synthesis across diverse artistic styles and photorealistic outputs.
Stable Fast 3D is a transformer-based generative AI model developed by Stability AI that reconstructs textured 3D mesh assets from single input images in approximately 0.5 seconds. The model predicts comprehensive material properties including albedo, roughness, and metallicity, producing UV-unwrapped meshes suitable for integration into rendering pipelines and interactive applications across gaming, virtual reality, and design workflows.
FLUX.1 [schnell] is a 12-billion parameter text-to-image generation model developed by Black Forest Labs using hybrid diffusion transformer architecture with rectified flow and latent adversarial diffusion distillation. The model generates images from text descriptions in 1-4 diffusion steps, supporting variable resolutions and aspect ratios. Released under Apache 2.0 license, it employs flow matching techniques and parallel attention layers for efficient synthesis.
Mistral Large 2 is a dense transformer-based language model developed by Mistral AI with 123 billion parameters and a 128,000-token context window. The model demonstrates strong performance across multilingual tasks, code generation in 80+ programming languages, mathematical reasoning, and function calling capabilities. It achieves 84% on MMLU, 92% on HumanEval, and 93% on GSM8K benchmarks while maintaining concise output generation.
Mistral NeMo 12B is a transformer-based language model developed collaboratively by Mistral AI and NVIDIA, featuring 12 billion parameters and a 128,000-token context window. The model incorporates grouped query attention, quantization-aware training for FP8 inference, and utilizes the custom Tekken tokenizer for improved multilingual and code compression efficiency. Available in both base and instruction-tuned variants, it demonstrates competitive performance on standard benchmarks while supporting function calling and multilingual capabilities across numerous languages including English, Chinese, Arabic, and various European languages.
Llama 3.1 70B is a transformer-based decoder language model developed by Meta with 70 billion parameters, trained on approximately 15 trillion tokens with a 128K context window. The model supports eight languages and demonstrates competitive performance across benchmarks for reasoning, coding, mathematics, and multilingual tasks. It is available under the Llama 3.1 Community License Agreement for research and commercial applications.
Gemma 2 9B is an open-weights decoder-only transformer language model developed by Google as part of the Gemma family. Trained on 8 trillion tokens using TPUv5p infrastructure, the model supports English text generation, question answering, and summarization tasks. Available in both pre-trained and instruction-tuned versions with bfloat16 precision, it demonstrates competitive performance on benchmarks like MMLU and coding evaluations while incorporating safety filtering mechanisms.
DeepSeek Coder V2 Lite is an open-source Mixture-of-Experts code language model featuring 16 billion total parameters with 2.4 billion active parameters during inference. The model supports 338 programming languages, processes up to 128,000 tokens of context, and demonstrates competitive performance on code generation benchmarks including 81.1% accuracy on Python HumanEval tasks.
Qwen2-72B is a 72.71 billion parameter Transformer-based language model developed by Alibaba Cloud, featuring Group Query Attention and SwiGLU activation functions. The model demonstrates strong performance across diverse benchmarks including MMLU (84.2), HumanEval (64.6), and GSM8K (89.5), with multilingual capabilities spanning 27 languages and extended context handling up to 128,000 tokens for specialized applications.
Yi 1.5 34B is a 34.4 billion parameter decoder-only Transformer language model developed by 01.AI, featuring Grouped-Query Attention and SwiGLU activations. Trained on 3.1 trillion bilingual tokens, it demonstrates capabilities in reasoning, mathematics, and code generation, with variants supporting up to 200,000 token contexts and multimodal understanding through vision-language extensions.
DeepSeek V2 is a large-scale Mixture-of-Experts language model with 236 billion total parameters, activating only 21 billion per token. It features Multi-head Latent Attention for reduced memory usage and supports context lengths up to 128,000 tokens. Trained on 8.1 trillion tokens with emphasis on English and Chinese data, it demonstrates competitive performance across language understanding, code generation, and mathematical reasoning tasks while achieving significant efficiency improvements over dense models.
Phi-3 Mini Instruct is a 3.8 billion parameter instruction-tuned language model developed by Microsoft using a dense decoder-only Transformer architecture. The model supports a 128,000 token context window and was trained on 4.9 trillion tokens of high-quality data, followed by supervised fine-tuning and direct preference optimization. It demonstrates competitive performance in reasoning, mathematics, and code generation tasks among models under 13 billion parameters, with particular strengths in long-context understanding and structured output generation.
Llama 3 8B is an open-weights transformer-based language model developed by Meta, featuring 8 billion parameters and trained on over 15 trillion tokens. The model utilizes grouped-query attention and a 128,000-token vocabulary, supporting 8,192-token context lengths. Available in both pretrained and instruction-tuned variants, it demonstrates capabilities in text generation, code completion, and conversational tasks across multiple languages.
Llama 4 Scout (17Bx16E) is a multimodal large language model developed by Meta using a Mixture-of-Experts transformer architecture with 109 billion total parameters and 17 billion active parameters per token. The model features a 10 million token context window, supports text and image understanding across multiple languages, and was trained on approximately 40 trillion tokens with an August 2024 knowledge cutoff.
Command R+ v01 is a 104-billion parameter open-weights language model developed by Cohere, optimized for retrieval-augmented generation, tool use, and multilingual tasks. The model features a 128,000-token context window and specializes in generating outputs with inline citations from retrieved documents. It supports automated tool calling, demonstrates competitive performance across standard benchmarks, and includes efficient tokenization for non-English languages, making it suitable for enterprise applications requiring factual accuracy and transparency.
Command R v01 is a 35-billion-parameter transformer-based language model developed by Cohere, featuring retrieval-augmented generation with explicit citations, tool use capabilities, and multilingual support across ten languages. The model supports a 128,000-token context window and demonstrates performance in enterprise applications, multi-step reasoning tasks, and long-context evaluations, though it requires commercial licensing for enterprise use.
Playground v2.5 Aesthetic is a diffusion-based text-to-image model that generates images at 1024x1024 resolution across multiple aspect ratios. Developed by Playground and released in February 2024, it employs the EDM training framework and human preference alignment techniques to improve color vibrancy, contrast, and human feature rendering compared to its predecessor and other open-source models like Stable Diffusion XL.
Stable Cascade Stage B is an intermediate latent super-resolution component within Stability AI's three-stage text-to-image generation system built on the Würstchen architecture. It operates as a diffusion model that upscales compressed 16×24×24 latents from Stage C to 4×256×256 representations, preserving semantic content while restoring fine details. Available in 700M and 1.5B parameter versions, Stage B enables the system's efficient 42:1 compression ratio and supports extensions like ControlNet and LoRA for enhanced creative workflows.
Stable Video Diffusion XT 1.1 is a latent diffusion model developed by Stability AI that generates 25-frame video sequences at 1024x576 resolution from single input images. The model employs a three-stage training process including image pretraining, video training on curated datasets, and high-resolution finetuning, enabling motion synthesis with configurable camera controls and temporal consistency for image-to-video transformation applications.
Qwen 1.5 72B is a 72-billion parameter transformer-based language model developed by Alibaba Cloud's Qwen Team and released in February 2024. The model supports a 32,768-token context window and demonstrates strong multilingual capabilities across 12 languages, achieving competitive performance on benchmarks including MMLU (77.5), C-Eval (84.1), and GSM8K (79.5). It features alignment optimization through Direct Policy Optimization and Proximal Policy Optimization techniques, enabling effective instruction-following and integration with external systems for applications including retrieval-augmented generation and code interpretation.
The SDXL Motion Model is an AnimateDiff-based video generation framework that adds temporal animation capabilities to existing text-to-image diffusion models. Built for compatibility with SDXL at 1024×1024 resolution, it employs a plug-and-play motion module trained on video datasets to generate coherent animated sequences while preserving the visual style of the underlying image model.
Phi-2 is a 2.7 billion parameter Transformer-based language model developed by Microsoft Research and released in December 2023. The model was trained on approximately 1.4 trillion tokens using a "textbook-quality" data approach, incorporating synthetic data from GPT-3.5 and filtered web sources. Phi-2 demonstrates competitive performance in reasoning, language understanding, and code generation tasks compared to larger models in its parameter class.
Mixtral 8x7B is a sparse Mixture of Experts language model developed by Mistral AI and released under the Apache 2.0 license in December 2023. The model uses a decoder-only transformer architecture with eight expert networks per layer, activating only two experts per token, resulting in 12.9 billion active parameters from a total 46.7 billion. It demonstrates competitive performance on benchmarks including MMLU, achieving multilingual capabilities across English, French, German, Spanish, and Italian while maintaining efficient inference speeds.
Playground v2 Aesthetic is a latent diffusion text-to-image model developed by playgroundai that generates 1024x1024 pixel images using dual pre-trained text encoders (OpenCLIP-ViT/G and CLIP-ViT/L). The model achieved a 7.07 FID score on the MJHQ-30K benchmark and demonstrated a 2.5x preference rate over Stable Diffusion XL in user studies, focusing on high-aesthetic image synthesis with strong prompt alignment.
Stable Video Diffusion XT is a generative AI model developed by Stability AI that extends the Stable Diffusion architecture for video synthesis. The model supports image-to-video and text-to-video generation, producing up to 25 frames at resolutions supporting 3-30 fps. Built on a latent video diffusion architecture with over 1.5 billion parameters, SVD-XT incorporates temporal modeling layers and was trained using a three-stage methodology on curated video datasets.
Yi 1 34B is a bilingual transformer-based language model developed by 01.AI, trained on 3 trillion tokens with support for both English and Chinese. The model features a 4,096-token context window and demonstrates competitive performance on multilingual benchmarks including MMLU, CMMLU, and C-Eval, with variants available including extended 200K context and chat-optimized versions released under Apache 2.0 license.
MusicGen is a text-to-music generation model developed by Meta's FAIR team as part of the AudioCraft library. The model uses a two-stage architecture combining EnCodec neural audio compression with a transformer-based autoregressive language model to generate musical audio from textual descriptions or melody inputs. Trained on approximately 20,000 hours of licensed music, MusicGen supports both monophonic and stereophonic outputs and demonstrates competitive performance in objective and subjective evaluations against contemporary music generation models.
Vocos is a neural vocoder developed by GemeloAI that employs a Fourier-based architecture to generate Short-Time Fourier Transform spectral coefficients rather than directly modeling time-domain waveforms. The model supports both mel-spectrogram and neural audio codec token inputs, operates under the MIT license, and demonstrates computational efficiency through its use of inverse STFT for audio reconstruction while achieving competitive performance metrics on speech and music synthesis tasks.
CodeLlama 34B is a large language model developed by Meta that builds upon Llama 2's architecture and is optimized for code generation, understanding, and programming tasks. The model supports multiple programming languages including Python, C++, Java, and JavaScript, with an extended context window of up to 100,000 tokens for handling large codebases. Available in three variants (Base, Python-specialized, and Instruct), it achieved 53.7% accuracy on HumanEval and 56.2% on MBPP benchmarks, demonstrating capabilities in code completion, debugging, and natural language explanations.
Llama 2 7B is a transformer-based language model developed by Meta with 7 billion parameters, trained on 2 trillion tokens with a 4,096-token context length. The model supports text generation in English and 27 other languages, with chat-optimized variants fine-tuned using supervised learning and reinforcement learning from human feedback for dialogue applications.
Llama 2 70B is a 70-billion parameter transformer-based language model developed by Meta, featuring Grouped-Query Attention and a 4096-token context window. Trained on 2 trillion tokens with a September 2022 cutoff, it demonstrates strong performance across language benchmarks including 68.9 on MMLU and 37.5 pass@1 on code generation tasks, while offering both pretrained and chat-optimized variants under Meta's commercial license.
Bark is a transformer-based text-to-audio model that generates multilingual speech, music, and sound effects by converting text directly to audio tokens using EnCodec quantization. The model supports over 13 languages with 100+ speaker presets and can produce nonverbal sounds like laughter through special tokens, operating via a three-stage pipeline from semantic to fine audio tokens.
LLaMA 13B is a transformer-based language model developed by Meta as part of the LLaMA model family, featuring 13 billion parameters and trained on 1.4 trillion tokens from publicly available datasets. The model incorporates architectural optimizations including RMSNorm, SwiGLU activation functions, and rotary positional embeddings, achieving competitive performance with larger models while maintaining efficiency. Released under a noncommercial research license, it demonstrates capabilities across language understanding, reasoning, and code generation benchmarks.
LLaMA 65B is a 65.2 billion parameter transformer-based language model developed by Meta and released in February 2023. The model utilizes architectural optimizations including RMSNorm pre-normalization, SwiGLU activation functions, and rotary positional embeddings. Trained exclusively on 1.4 trillion tokens from publicly available datasets including CommonCrawl, Wikipedia, GitHub, and arXiv, it demonstrates competitive performance across natural language understanding benchmarks while being distributed under a non-commercial research license.
Stable Diffusion 2 is an open-source text-to-image diffusion model developed by Stability AI that generates images at resolutions up to 768×768 pixels using latent diffusion techniques. The model employs an OpenCLIP-ViT/H text encoder and was trained on filtered subsets of the LAION-5B dataset. It includes specialized variants for inpainting, depth-conditioned generation, and 4x upscaling, offering improved capabilities over earlier versions while maintaining open accessibility for research applications.
Stable Diffusion 1.5 is a latent text-to-image diffusion model that generates 512x512 images from text prompts using a U-Net architecture conditioned on CLIP text embeddings within a compressed latent space. Trained on LAION dataset subsets, the model supports text-to-image generation, image-to-image translation, and inpainting tasks, released under the CreativeML OpenRAIL-M license for research and commercial applications.
Stable Diffusion 1.1 is a latent text-to-image diffusion model developed by CompVis, Stability AI, and Runway that generates images from natural language prompts. The model uses a VAE to compress images into latent space, a U-Net for denoising, and a CLIP text encoder for conditioning. Trained on LAION dataset subsets at 512×512 resolution, it supports text-to-image generation, image-to-image translation, and inpainting applications while operating efficiently in compressed latent space.
Kimi K2 is an open-source mixture-of-experts language model developed by Moonshot AI, featuring 1 trillion total parameters with 32 billion activated per inference. The model utilizes a 128,000-token context window and specializes in agentic intelligence, tool use, and autonomous reasoning capabilities. Trained on 15.5 trillion tokens with reinforcement learning techniques, it demonstrates performance across coding, mathematical reasoning, and multi-step task execution benchmarks.
Gemma 3n E4B is a multimodal generative AI model developed by Google DeepMind with 8 billion raw parameters yielding 4 billion effective parameters. Built on the MatFormer architecture for mobile and edge deployment, it processes text, image, audio, and video inputs to generate text outputs. The model features elastic inference capabilities, allowing extraction of smaller sub-models for faster performance, and supports over 140 languages with demonstrated proficiency in reasoning, coding, and multilingual tasks.
DeepSeek R1 (0528) is a large language model developed by DeepSeek-AI featuring 671 billion total parameters with 37 billion activated during inference. Built on the DeepSeek-V3-Base architecture using Mixture-of-Experts design, it employs Group Relative Policy Optimization and multi-stage training with reinforcement learning to enhance reasoning capabilities. The model supports 128,000 token context length and demonstrates improved performance on mathematical, coding, and reasoning benchmarks compared to its predecessors.
Qwen3-0.6B is a dense language model with 0.6 billion parameters developed by Alibaba Cloud, featuring a 28-layer transformer architecture with Grouped Query Attention. The model supports dual thinking modes for adaptive reasoning and general dialogue, processes up to 32,768 tokens context length, and demonstrates multilingual capabilities across over 100 languages. It utilizes strong-to-weak distillation from larger Qwen3 models and is released under Apache 2.0 license.
Qwen3-4B is a 4.0 billion parameter transformer language model developed by Alibaba Cloud, featuring dual reasoning modes that allow users to toggle between detailed step-by-step thinking and rapid response generation. Released under Apache 2.0 license, the model supports 32,768 token contexts, demonstrates strong performance across mathematical reasoning and coding benchmarks, and incorporates advanced training techniques including strong-to-weak distillation from larger teacher models.
Qwen3-14B is a dense transformer language model developed by Alibaba Cloud with 14.8 billion parameters, featuring hybrid "thinking" and "non-thinking" reasoning modes that can be controlled via prompts. The model supports 119 languages, extends to 131k token contexts through YaRN scaling, and includes agent capabilities with tool-use functionality, all released under Apache 2.0 license.
Qwen3-30B-A3B is a Mixture-of-Experts language model developed by Alibaba Cloud featuring 30.5 billion total parameters with 3.3 billion activated per token. The model employs hybrid reasoning modes that allow dynamic switching between step-by-step thinking for complex tasks and rapid responses for simpler queries. It supports 119 languages, extends to 131,072 tokens context length, and utilizes strong-to-weak distillation from larger Qwen3 models for efficient deployment while maintaining competitive performance on reasoning, coding, and multilingual benchmarks.
HiDream I1 Full is an open-source image generation model developed by HiDream.ai featuring a 17 billion parameter sparse Diffusion Transformer architecture with Mixture-of-Experts design. The model employs hybrid text encoding combining Long-CLIP, T5-XXL, and Llama 3.1 8B components for precise text-to-image synthesis. It demonstrates strong performance on industry benchmarks and supports diverse visual styles through flow-matching in latent space.
Mistral Small 3.1 (2503) is a 24-billion parameter transformer-based model developed by Mistral AI and released under Apache 2.0 license. This multimodal and multilingual model processes both text and visual inputs with a context window of 128,000 tokens using the Tekken tokenizer. It demonstrates competitive performance on academic benchmarks including MMLU and GPQA while supporting function calling and structured output generation for automation workflows.
Gemma 3 4B is a multimodal instruction-tuned model developed by Google DeepMind that processes text and image inputs to generate text outputs. The model features a decoder-only transformer architecture with approximately 4.3 billion parameters, supports context windows up to 128,000 tokens, and operates across over 140 languages. It incorporates a SigLIP vision encoder for image processing and utilizes grouped-query attention with interleaved local and global attention layers for efficient long-context handling.
Gemma 3 27B is a multimodal generative AI model developed by Google DeepMind that processes both text and image inputs to produce text outputs. Built on a decoder-only transformer architecture with 27 billion parameters, it incorporates a SigLIP vision encoder and supports context lengths up to 128,000 tokens. The model was trained on over 14 trillion tokens and demonstrates competitive performance across language, coding, mathematical reasoning, and vision-language tasks.
QwQ 32B is a 32.5-billion parameter causal language model developed by Alibaba Cloud as part of the Qwen series. The model employs a transformer architecture with 64 layers and Grouped Query Attention, trained using supervised fine-tuning and reinforcement learning focused on mathematical reasoning and coding proficiency. Released under Apache 2.0 license, it demonstrates competitive performance on reasoning benchmarks despite its relatively compact size.
Wan 2.1 I2V 14B 480P is an image-to-video generation model developed by Wan-AI featuring 14 billion parameters and operating at 480P resolution. Built on a diffusion transformer architecture with T5-based text encoding and a 3D causal variational autoencoder, the model transforms static images into temporally coherent video sequences guided by textual prompts, supporting both Chinese and English text rendering within its generative capabilities.
Wan 2.1 T2V 14B is a 14-billion parameter video generation model developed by Wan-AI that creates videos from text descriptions or images. The model employs a spatio-temporal variational autoencoder and diffusion transformer architecture to generate content at 480P and 720P resolutions. It supports multiple languages including Chinese and English, handles various video generation tasks, and demonstrates computational efficiency across different hardware configurations when deployed for research applications.
Qwen2.5 VL 7B is a 7-billion parameter multimodal language model developed by Alibaba Cloud that processes text, images, and video inputs. The model features a Vision Transformer with dynamic resolution support and Multimodal Rotary Position Embedding for spatial-temporal understanding. It demonstrates capabilities in document analysis, OCR, object detection, video comprehension, and structured output generation across multiple languages, released under Apache-2.0 license.
Lumina Image 2.0 is a 2 billion parameter text-to-image generative model developed by Alpha-VLLM that utilizes a flow-based diffusion transformer architecture. The model generates high-fidelity images up to 1024x1024 pixels from textual descriptions, employs a Gemma-2-2B text encoder and FLUX-VAE-16CH variational autoencoder, and is released under the Apache-2.0 license with support for multiple inference solvers and fine-tuning capabilities.
MiniMax Text 01 is an open-source large language model developed by MiniMaxAI featuring 456 billion total parameters with 45.9 billion active per token. The model employs a hybrid attention mechanism combining Lightning Attention with periodic Softmax Attention layers across 80 transformer layers, utilizing a Mixture-of-Experts design with 32 experts and Top-2 routing. It supports context lengths up to 4 million tokens during inference and demonstrates competitive performance across text generation, reasoning, and coding benchmarks.
DeepSeek-VL2 is a series of Mixture-of-Experts vision-language models developed by DeepSeek-AI that integrates visual and textual understanding through a decoder-only architecture. The models utilize a SigLIP vision encoder with dynamic tiling for high-resolution image processing, coupled with DeepSeekMoE language components featuring Multi-head Latent Attention. Available in three variants with 1.0B, 2.8B, and 4.5B activated parameters, the models support multimodal tasks including visual question answering, optical character recognition, document analysis, and visual grounding capabilities.
DeepSeek VL2 Tiny is a vision-language model from Deepseek AI that activates 1.0 billion parameters using Mixture-of-Experts architecture. The model combines a SigLIP vision encoder with a DeepSeekMoE-based language component to handle multimodal tasks including visual question answering, optical character recognition, document analysis, and visual grounding across images and text.
Llama 3.3 70B is a 70-billion parameter transformer-based language model developed by Meta, featuring instruction tuning through supervised fine-tuning and reinforcement learning from human feedback. The model supports a 128,000-token context window, incorporates Grouped-Query Attention for enhanced inference efficiency, and demonstrates multilingual capabilities across eight validated languages including English, German, French, Italian, Portuguese, Hindi, Spanish, and Thai.
CogVideoX 1.5 5B is an open-source video generation model developed by THUDM that creates high-resolution videos up to 1360x768 resolution from text prompts and images. The model employs a 3D causal variational autoencoder with 8x8x4 compression and an expert transformer architecture featuring adaptive LayerNorm for multimodal alignment. It supports both text-to-video and image-to-video synthesis with durations of 5-10 seconds at 16 fps, released under Apache 2.0 license.
QwQ 32B Preview is an experimental large language model developed by Alibaba Cloud's Qwen Team, built on the Qwen 2 architecture with 32.5 billion parameters. The model specializes in mathematical and coding reasoning tasks, achieving 65.2% on GPQA, 50.0% on AIME, 90.6% on MATH-500, and 50.0% on LiveCodeBench benchmarks through curiosity-driven, reflective analysis approaches.
Stable Diffusion 3.5 Large is an 8.1-billion-parameter text-to-image model utilizing Multimodal Diffusion Transformer architecture with Query-Key Normalization for enhanced training stability. The model generates images up to 1-megapixel resolution across diverse styles including photorealism, illustration, and digital art. It employs three text encoders supporting up to 256 tokens and demonstrates strong prompt adherence capabilities.
CogVideoX-5B-I2V is an open-source image-to-video generative AI model developed by THUDM that produces 6-second videos at 720×480 resolution from input images and English text prompts. The model employs a diffusion transformer architecture with 3D Causal VAE compression and generates 49 frames at 8 fps, supporting various video synthesis applications through its controllable conditioning mechanism.
Qwen 2.5 Math 7B is a 7.62-billion parameter language model developed by Alibaba Cloud that specializes in mathematical reasoning tasks in English and Chinese. The model employs chain-of-thought reasoning and tool-integrated approaches using Python interpreters for computational tasks. It demonstrates improved performance over its predecessor on mathematical benchmarks including MATH, GSM8K, and Chinese mathematics evaluations, achieving 83.6 on MATH using chain-of-thought methods.
Qwen2.5-Coder-7B is a 7.61 billion parameter transformer-based language model developed by Alibaba Cloud's Qwen Team, specialized for code generation and reasoning across 92 programming languages. The model features a 128,000-token context window, supports fill-in-the-middle code completion, and was trained on 5.5 trillion tokens of code and text data, demonstrating competitive performance on coding benchmarks like HumanEval and mathematical reasoning tasks.
Qwen 2.5 14B is a 14.7 billion parameter transformer-based language model developed by Alibaba Cloud's Qwen Team, featuring a 128,000 token context window and support for over 29 languages. The model utilizes advanced architectural components including Grouped Query Attention, RoPE embeddings, and SwiGLU activation, and was pretrained on up to 18 trillion tokens of diverse multilingual data for applications in reasoning, coding, and mathematical tasks.
Qwen 2.5 72B is a 72.7 billion parameter transformer-based language model developed by Alibaba Cloud's Qwen Team, released in September 2024. The model features a 128,000-token context window, supports over 29 languages, and demonstrates strong performance on coding, mathematical reasoning, and knowledge benchmarks. Built with architectural improvements including RoPE and SwiGLU activation functions, it excels at structured data handling and serves as a foundation model for fine-tuning applications.
Command R (08-2024) is a 32-billion parameter generative language model developed by Cohere, featuring a 128,000-token context window and support for 23 languages. The model incorporates Grouped Query Attention for enhanced inference efficiency and specializes in retrieval-augmented generation with citation capabilities, tool use, and multilingual comprehension. It demonstrates improved throughput and reduced latency compared to previous versions while offering configurable safety modes for enterprise applications.
Phi-3.5 Mini Instruct is a 3.8 billion parameter decoder-only Transformer model developed by Microsoft that supports multilingual text generation with a 128,000-token context window. The model demonstrates competitive performance across 22 languages and excels in reasoning, code generation, and long-context tasks, achieving an average benchmark score of 61.4 while maintaining efficient resource utilization.
AuraFlow v0.3 is a 6.8 billion parameter, flow-based text-to-image generative model developed by fal.ai. Built on an optimized DiT architecture with Maximal Update Parametrization, it features enhanced prompt following capabilities through comprehensive recaptioning and prompt enhancement pipelines. The model supports multiple aspect ratios and achieved a GenEval score of 0.703, demonstrating effective text-to-image synthesis across diverse artistic styles and photorealistic outputs.
Stable Fast 3D is a transformer-based generative AI model developed by Stability AI that reconstructs textured 3D mesh assets from single input images in approximately 0.5 seconds. The model predicts comprehensive material properties including albedo, roughness, and metallicity, producing UV-unwrapped meshes suitable for integration into rendering pipelines and interactive applications across gaming, virtual reality, and design workflows.
FLUX.1 [schnell] is a 12-billion parameter text-to-image generation model developed by Black Forest Labs using hybrid diffusion transformer architecture with rectified flow and latent adversarial diffusion distillation. The model generates images from text descriptions in 1-4 diffusion steps, supporting variable resolutions and aspect ratios. Released under Apache 2.0 license, it employs flow matching techniques and parallel attention layers for efficient synthesis.
Mistral Large 2 is a dense transformer-based language model developed by Mistral AI with 123 billion parameters and a 128,000-token context window. The model demonstrates strong performance across multilingual tasks, code generation in 80+ programming languages, mathematical reasoning, and function calling capabilities. It achieves 84% on MMLU, 92% on HumanEval, and 93% on GSM8K benchmarks while maintaining concise output generation.
Mistral NeMo 12B is a transformer-based language model developed collaboratively by Mistral AI and NVIDIA, featuring 12 billion parameters and a 128,000-token context window. The model incorporates grouped query attention, quantization-aware training for FP8 inference, and utilizes the custom Tekken tokenizer for improved multilingual and code compression efficiency. Available in both base and instruction-tuned variants, it demonstrates competitive performance on standard benchmarks while supporting function calling and multilingual capabilities across numerous languages including English, Chinese, Arabic, and various European languages.
Llama 3.1 70B is a transformer-based decoder language model developed by Meta with 70 billion parameters, trained on approximately 15 trillion tokens with a 128K context window. The model supports eight languages and demonstrates competitive performance across benchmarks for reasoning, coding, mathematics, and multilingual tasks. It is available under the Llama 3.1 Community License Agreement for research and commercial applications.
Gemma 2 9B is an open-weights decoder-only transformer language model developed by Google as part of the Gemma family. Trained on 8 trillion tokens using TPUv5p infrastructure, the model supports English text generation, question answering, and summarization tasks. Available in both pre-trained and instruction-tuned versions with bfloat16 precision, it demonstrates competitive performance on benchmarks like MMLU and coding evaluations while incorporating safety filtering mechanisms.
DeepSeek Coder V2 Lite is an open-source Mixture-of-Experts code language model featuring 16 billion total parameters with 2.4 billion active parameters during inference. The model supports 338 programming languages, processes up to 128,000 tokens of context, and demonstrates competitive performance on code generation benchmarks including 81.1% accuracy on Python HumanEval tasks.
Qwen2-72B is a 72.71 billion parameter Transformer-based language model developed by Alibaba Cloud, featuring Group Query Attention and SwiGLU activation functions. The model demonstrates strong performance across diverse benchmarks including MMLU (84.2), HumanEval (64.6), and GSM8K (89.5), with multilingual capabilities spanning 27 languages and extended context handling up to 128,000 tokens for specialized applications.
Yi 1.5 34B is a 34.4 billion parameter decoder-only Transformer language model developed by 01.AI, featuring Grouped-Query Attention and SwiGLU activations. Trained on 3.1 trillion bilingual tokens, it demonstrates capabilities in reasoning, mathematics, and code generation, with variants supporting up to 200,000 token contexts and multimodal understanding through vision-language extensions.
DeepSeek V2 is a large-scale Mixture-of-Experts language model with 236 billion total parameters, activating only 21 billion per token. It features Multi-head Latent Attention for reduced memory usage and supports context lengths up to 128,000 tokens. Trained on 8.1 trillion tokens with emphasis on English and Chinese data, it demonstrates competitive performance across language understanding, code generation, and mathematical reasoning tasks while achieving significant efficiency improvements over dense models.
Phi-3 Mini Instruct is a 3.8 billion parameter instruction-tuned language model developed by Microsoft using a dense decoder-only Transformer architecture. The model supports a 128,000 token context window and was trained on 4.9 trillion tokens of high-quality data, followed by supervised fine-tuning and direct preference optimization. It demonstrates competitive performance in reasoning, mathematics, and code generation tasks among models under 13 billion parameters, with particular strengths in long-context understanding and structured output generation.
Llama 3 8B is an open-weights transformer-based language model developed by Meta, featuring 8 billion parameters and trained on over 15 trillion tokens. The model utilizes grouped-query attention and a 128,000-token vocabulary, supporting 8,192-token context lengths. Available in both pretrained and instruction-tuned variants, it demonstrates capabilities in text generation, code completion, and conversational tasks across multiple languages.
Llama 4 Scout (17Bx16E) is a multimodal large language model developed by Meta using a Mixture-of-Experts transformer architecture with 109 billion total parameters and 17 billion active parameters per token. The model features a 10 million token context window, supports text and image understanding across multiple languages, and was trained on approximately 40 trillion tokens with an August 2024 knowledge cutoff.
Command R+ v01 is a 104-billion parameter open-weights language model developed by Cohere, optimized for retrieval-augmented generation, tool use, and multilingual tasks. The model features a 128,000-token context window and specializes in generating outputs with inline citations from retrieved documents. It supports automated tool calling, demonstrates competitive performance across standard benchmarks, and includes efficient tokenization for non-English languages, making it suitable for enterprise applications requiring factual accuracy and transparency.
Command R v01 is a 35-billion-parameter transformer-based language model developed by Cohere, featuring retrieval-augmented generation with explicit citations, tool use capabilities, and multilingual support across ten languages. The model supports a 128,000-token context window and demonstrates performance in enterprise applications, multi-step reasoning tasks, and long-context evaluations, though it requires commercial licensing for enterprise use.
Playground v2.5 Aesthetic is a diffusion-based text-to-image model that generates images at 1024x1024 resolution across multiple aspect ratios. Developed by Playground and released in February 2024, it employs the EDM training framework and human preference alignment techniques to improve color vibrancy, contrast, and human feature rendering compared to its predecessor and other open-source models like Stable Diffusion XL.
Stable Cascade Stage B is an intermediate latent super-resolution component within Stability AI's three-stage text-to-image generation system built on the Würstchen architecture. It operates as a diffusion model that upscales compressed 16×24×24 latents from Stage C to 4×256×256 representations, preserving semantic content while restoring fine details. Available in 700M and 1.5B parameter versions, Stage B enables the system's efficient 42:1 compression ratio and supports extensions like ControlNet and LoRA for enhanced creative workflows.
Stable Video Diffusion XT 1.1 is a latent diffusion model developed by Stability AI that generates 25-frame video sequences at 1024x576 resolution from single input images. The model employs a three-stage training process including image pretraining, video training on curated datasets, and high-resolution finetuning, enabling motion synthesis with configurable camera controls and temporal consistency for image-to-video transformation applications.
Qwen 1.5 72B is a 72-billion parameter transformer-based language model developed by Alibaba Cloud's Qwen Team and released in February 2024. The model supports a 32,768-token context window and demonstrates strong multilingual capabilities across 12 languages, achieving competitive performance on benchmarks including MMLU (77.5), C-Eval (84.1), and GSM8K (79.5). It features alignment optimization through Direct Policy Optimization and Proximal Policy Optimization techniques, enabling effective instruction-following and integration with external systems for applications including retrieval-augmented generation and code interpretation.
The SDXL Motion Model is an AnimateDiff-based video generation framework that adds temporal animation capabilities to existing text-to-image diffusion models. Built for compatibility with SDXL at 1024×1024 resolution, it employs a plug-and-play motion module trained on video datasets to generate coherent animated sequences while preserving the visual style of the underlying image model.
Phi-2 is a 2.7 billion parameter Transformer-based language model developed by Microsoft Research and released in December 2023. The model was trained on approximately 1.4 trillion tokens using a "textbook-quality" data approach, incorporating synthetic data from GPT-3.5 and filtered web sources. Phi-2 demonstrates competitive performance in reasoning, language understanding, and code generation tasks compared to larger models in its parameter class.
Mixtral 8x7B is a sparse Mixture of Experts language model developed by Mistral AI and released under the Apache 2.0 license in December 2023. The model uses a decoder-only transformer architecture with eight expert networks per layer, activating only two experts per token, resulting in 12.9 billion active parameters from a total 46.7 billion. It demonstrates competitive performance on benchmarks including MMLU, achieving multilingual capabilities across English, French, German, Spanish, and Italian while maintaining efficient inference speeds.
Playground v2 Aesthetic is a latent diffusion text-to-image model developed by playgroundai that generates 1024x1024 pixel images using dual pre-trained text encoders (OpenCLIP-ViT/G and CLIP-ViT/L). The model achieved a 7.07 FID score on the MJHQ-30K benchmark and demonstrated a 2.5x preference rate over Stable Diffusion XL in user studies, focusing on high-aesthetic image synthesis with strong prompt alignment.
Stable Video Diffusion XT is a generative AI model developed by Stability AI that extends the Stable Diffusion architecture for video synthesis. The model supports image-to-video and text-to-video generation, producing up to 25 frames at resolutions supporting 3-30 fps. Built on a latent video diffusion architecture with over 1.5 billion parameters, SVD-XT incorporates temporal modeling layers and was trained using a three-stage methodology on curated video datasets.
Yi 1 34B is a bilingual transformer-based language model developed by 01.AI, trained on 3 trillion tokens with support for both English and Chinese. The model features a 4,096-token context window and demonstrates competitive performance on multilingual benchmarks including MMLU, CMMLU, and C-Eval, with variants available including extended 200K context and chat-optimized versions released under Apache 2.0 license.
MusicGen is a text-to-music generation model developed by Meta's FAIR team as part of the AudioCraft library. The model uses a two-stage architecture combining EnCodec neural audio compression with a transformer-based autoregressive language model to generate musical audio from textual descriptions or melody inputs. Trained on approximately 20,000 hours of licensed music, MusicGen supports both monophonic and stereophonic outputs and demonstrates competitive performance in objective and subjective evaluations against contemporary music generation models.
Vocos is a neural vocoder developed by GemeloAI that employs a Fourier-based architecture to generate Short-Time Fourier Transform spectral coefficients rather than directly modeling time-domain waveforms. The model supports both mel-spectrogram and neural audio codec token inputs, operates under the MIT license, and demonstrates computational efficiency through its use of inverse STFT for audio reconstruction while achieving competitive performance metrics on speech and music synthesis tasks.
CodeLlama 34B is a large language model developed by Meta that builds upon Llama 2's architecture and is optimized for code generation, understanding, and programming tasks. The model supports multiple programming languages including Python, C++, Java, and JavaScript, with an extended context window of up to 100,000 tokens for handling large codebases. Available in three variants (Base, Python-specialized, and Instruct), it achieved 53.7% accuracy on HumanEval and 56.2% on MBPP benchmarks, demonstrating capabilities in code completion, debugging, and natural language explanations.
Llama 2 7B is a transformer-based language model developed by Meta with 7 billion parameters, trained on 2 trillion tokens with a 4,096-token context length. The model supports text generation in English and 27 other languages, with chat-optimized variants fine-tuned using supervised learning and reinforcement learning from human feedback for dialogue applications.
Llama 2 70B is a 70-billion parameter transformer-based language model developed by Meta, featuring Grouped-Query Attention and a 4096-token context window. Trained on 2 trillion tokens with a September 2022 cutoff, it demonstrates strong performance across language benchmarks including 68.9 on MMLU and 37.5 pass@1 on code generation tasks, while offering both pretrained and chat-optimized variants under Meta's commercial license.
Bark is a transformer-based text-to-audio model that generates multilingual speech, music, and sound effects by converting text directly to audio tokens using EnCodec quantization. The model supports over 13 languages with 100+ speaker presets and can produce nonverbal sounds like laughter through special tokens, operating via a three-stage pipeline from semantic to fine audio tokens.
LLaMA 13B is a transformer-based language model developed by Meta as part of the LLaMA model family, featuring 13 billion parameters and trained on 1.4 trillion tokens from publicly available datasets. The model incorporates architectural optimizations including RMSNorm, SwiGLU activation functions, and rotary positional embeddings, achieving competitive performance with larger models while maintaining efficiency. Released under a noncommercial research license, it demonstrates capabilities across language understanding, reasoning, and code generation benchmarks.
LLaMA 65B is a 65.2 billion parameter transformer-based language model developed by Meta and released in February 2023. The model utilizes architectural optimizations including RMSNorm pre-normalization, SwiGLU activation functions, and rotary positional embeddings. Trained exclusively on 1.4 trillion tokens from publicly available datasets including CommonCrawl, Wikipedia, GitHub, and arXiv, it demonstrates competitive performance across natural language understanding benchmarks while being distributed under a non-commercial research license.
Stable Diffusion 2 is an open-source text-to-image diffusion model developed by Stability AI that generates images at resolutions up to 768×768 pixels using latent diffusion techniques. The model employs an OpenCLIP-ViT/H text encoder and was trained on filtered subsets of the LAION-5B dataset. It includes specialized variants for inpainting, depth-conditioned generation, and 4x upscaling, offering improved capabilities over earlier versions while maintaining open accessibility for research applications.
Stable Diffusion 1.5 is a latent text-to-image diffusion model that generates 512x512 images from text prompts using a U-Net architecture conditioned on CLIP text embeddings within a compressed latent space. Trained on LAION dataset subsets, the model supports text-to-image generation, image-to-image translation, and inpainting tasks, released under the CreativeML OpenRAIL-M license for research and commercial applications.
Stable Diffusion 1.1 is a latent text-to-image diffusion model developed by CompVis, Stability AI, and Runway that generates images from natural language prompts. The model uses a VAE to compress images into latent space, a U-Net for denoising, and a CLIP text encoder for conditioning. Trained on LAION dataset subsets at 512×512 resolution, it supports text-to-image generation, image-to-image translation, and inpainting applications while operating efficiently in compressed latent space.
Gemma 3n E2B is a multimodal generative AI model developed by Google DeepMind that supports text, image, audio, and video inputs. Built on the MatFormer architecture with 6 billion raw parameters but 2 billion effective parameters, it employs Per-Layer Embeddings and KV Cache Sharing for efficient operation on resource-constrained devices. The model was trained on over 11 trillion tokens across 140+ languages with a June 2024 knowledge cutoff.
Mistral Small 3.2 (2506) is a 24-billion parameter text generation model developed by Mistral AI as an incremental update to Mistral Small 3.1. The model features improved instruction following, reduced repetition, enhanced function calling reliability, and maintained multimodal capabilities including vision processing. It supports up to 128,000 tokens context length and demonstrates performance improvements on benchmarks like Wildbench v2 and Arena Hard v2.
HiDream E1 Full is an instruction-based image editing model developed by HiDream-ai that enables natural language-guided modifications of existing images. Built upon the HiDream-I1 foundation model, it utilizes a 17-billion parameter sparse Diffusion Transformer architecture with Mixture-of-Experts components. The model supports various editing tasks including style transfer, object manipulation, and content addition or removal while preserving unmodified image regions through spatially weighted loss functions.
Qwen3-1.7B is a dense transformer language model with 1.7 billion parameters developed by Alibaba Cloud's Qwen Team. The model features dual-mode reasoning capabilities, operating in either "thinking" mode for step-by-step reasoning with intermediate computations or "non-thinking" mode for rapid direct responses. It supports 119 languages and utilizes a 32,768-token context window with grouped query attention architecture.
Qwen3-8B is a dense transformer-based language model developed by Alibaba Cloud featuring 8.2 billion parameters across 36 layers with Grouped Query Attention and 32,768-token native context length. The model supports hybrid thinking capabilities, enabling dynamic switching between systematic reasoning and rapid response modes, and was trained on 36 trillion tokens across 119 languages using multi-stage optimization including distillation from larger Qwen3 variants.
Qwen3-32B is a 32.8 billion parameter dense language model developed by Alibaba Cloud, featuring hybrid "thinking" modes that enable step-by-step reasoning for complex tasks or rapid responses for routine queries. The model supports 119 languages, extends to 32K token context length, and was trained on 36 trillion tokens using a four-stage post-training pipeline incorporating reinforcement learning and reasoning enhancement techniques.
Qwen3-235B-A22B is a Mixture-of-Experts language model developed by Alibaba Cloud's Qwen team, featuring 235 billion total parameters with 22 billion activated per inference step. The model offers dual operational modes—"thinking" for complex reasoning and "non-thinking" for rapid responses—enabling users to balance computational depth with inference speed. Trained on 36 trillion tokens across 119 languages, it supports advanced agentic workflows and demonstrates competitive performance on mathematical, coding, and multilingual benchmarks.
DeepSeek V3 (0324) is a Mixture-of-Experts language model with 671 billion total parameters and 37 billion activated per token, developed by DeepSeek AI. The model incorporates Multi-head Latent Attention, FP8 mixed-precision training, and Multi-Token Prediction techniques. It demonstrates strong performance in reasoning, code generation, and multilingual tasks, particularly Chinese, with support for 128K token contexts and availability under permissive open-source licensing.
Gemma 3 1B is a lightweight, multimodal generative AI model developed by Google DeepMind that processes both text and images to generate text outputs. Built on a decoder-only transformer architecture with local and global attention layers, the model supports a 32,000-token context window and was trained on 2 trillion tokens across 140+ languages. The model offers open-source pre-trained and instruction-tuned weights for research and practical applications.
Gemma 3 12B is a multimodal, instruction-tuned language model developed by Google DeepMind that processes both text and images to generate text outputs. The model features a decoder-only transformer architecture with a 400-million-parameter vision encoder and supports context windows up to 128,000 tokens. Trained on 12 trillion tokens across over 140 languages using knowledge distillation and reinforcement learning techniques, it demonstrates capabilities in mathematics, coding, and vision-language tasks while offering quantized variants for resource-efficient deployment.
Command A is a decoder-only transformer language model developed by Cohere for enterprise applications, featuring a 256,000-token context window and optimized for multilingual understanding, retrieval-augmented generation, code synthesis, and agentic workflows. The model employs grouped-query attention and architectural innovations for enhanced throughput, achieving competitive performance across academic benchmarks while demonstrating efficiency advantages in inference speed and memory usage compared to similar models.
Wan 2.1 T2V 1.3B is an open-source text-to-video generation model developed by Wan-AI, featuring 1.3 billion parameters and utilizing a Flow Matching framework with diffusion transformers. The model supports multilingual text-to-video synthesis in English and Chinese, operates efficiently on consumer GPUs requiring 8.19 GB VRAM, and generates 480P videos with capabilities for image-to-video conversion and text rendering within videos.
Wan 2.1 I2V 14B 720P is a 14-billion parameter image-to-video generation model developed by Wan-AI that converts single images into 720P videos. Built on a unified transformer-based diffusion architecture with a novel 3D causal VAE (Wan-VAE) for spatiotemporal compression, the model supports multilingual text prompts and demonstrates competitive performance in video generation benchmarks while maintaining computational efficiency across various GPU configurations.
Qwen2.5-VL-3B-Instruct is a multimodal large language model developed by Alibaba Cloud featuring 3 billion parameters. The model combines a Vision Transformer encoder with a Qwen2.5-series decoder to process images, videos, and text through dynamic resolution handling and temporal processing capabilities. It supports object detection, OCR, document analysis, video understanding, and computer interface automation, trained on approximately 1.4 trillion tokens across multiple modalities and released under Apache-2.0 license.
Qwen2.5-VL 72B is a 72-billion parameter multimodal generative AI model developed by Alibaba Cloud that integrates vision and language understanding. The model features dynamic resolution processing, temporal video alignment, and architectural enhancements over previous Qwen2-VL versions. It performs object detection, document parsing, video comprehension, OCR across multiple languages, and functions as a visual agent for interactive tasks, trained on over 1.4 trillion tokens.
DeepSeek R1 is a large language model developed by DeepSeek AI that employs a Mixture-of-Experts architecture with 671 billion total parameters and 37 billion activated during inference. The model utilizes reinforcement learning and supervised fine-tuning to enhance reasoning capabilities across mathematics, coding, and logic tasks, achieving competitive performance on benchmarks including 90.8 on MMLU and 97.3 on MATH-500.
DeepSeek V3 is a Mixture-of-Experts language model with 671 billion total parameters and 37 billion activated per token, developed by DeepSeek-AI. The model features Multi-head Latent Attention, auxiliary-loss-free load balancing, and FP8 mixed-precision training. Trained on 14.8 trillion tokens with a 128,000-token context window, it demonstrates competitive performance across reasoning, coding, and mathematical benchmarks while supporting multilingual capabilities and long-context processing.
DeepSeek VL2 Small is a 2.8 billion parameter multimodal vision-language model that uses a Mixture-of-Experts architecture with dynamic tiling for processing high-resolution images. Built on the DeepSeekMoE-16B framework with SigLIP vision encoding, it handles tasks including visual question answering, OCR, document analysis, and visual grounding across multiple languages, achieving competitive performance on benchmarks like DocVQA while maintaining computational efficiency through sparse expert routing.
Phi-4 is a 14-billion parameter decoder-only Transformer language model developed by Microsoft Research that focuses on mathematical reasoning and code generation through curated synthetic data training. The model supports a 16,000-token context window and achieves competitive performance on benchmarks like MMLU (84.8) and HumanEval (82.6) despite its relatively compact size, utilizing supervised fine-tuning and direct preference optimization for alignment.
HunyuanVideo is an open-source video generation model developed by Tencent that supports text-to-video, image-to-video, and controllable video synthesis. The model employs a Transformer-based architecture with a 3D Variational Autoencoder and utilizes flow matching for generating videos at variable resolutions and durations. It features 13 billion parameters and includes capabilities for avatar animation, audio synchronization, and multi-aspect ratio output generation.
CogVideoX 1.5 5B I2V is an image-to-video generation model developed by THUDM using a diffusion transformer architecture with 3D causal variational autoencoder. The model generates temporally coherent videos from input images and text prompts, supporting resolutions up to 1360 pixels and video lengths of 5-10 seconds at 16 fps, trained on 35 million curated video clips.
Qwen2.5-Coder-32B is a 32.5-billion parameter transformer-based language model developed by Alibaba Cloud, specifically designed for programming and code intelligence tasks. The model supports over 92 programming languages and features capabilities in code generation, completion, repair, and reasoning with a 128,000-token context window. Trained on approximately 5.5 trillion tokens of code and instructional data, it demonstrates performance across various coding benchmarks including HumanEval, MBPP, and multilingual programming evaluations.
Llama 3.2 3B is a multilingual instruction-tuned language model developed by Meta with 3 billion parameters and a 128,000-token context window. The model utilizes knowledge distillation from larger Llama variants, Grouped-Query Attention for efficient inference, and advanced quantization techniques optimized for PyTorch's ExecuTorch framework. Supporting eight languages, it targets assistant and agentic applications while enabling deployment in resource-constrained environments.
Qwen 2.5 Math 1.5B is a specialized language model developed by Alibaba Cloud for mathematical reasoning in English and Chinese. Built on the Qwen2.5 architecture with 4,096 token context length, it was trained on the Qwen Math Corpus v2 containing over one trillion tokens. The model supports chain-of-thought reasoning and tool-integrated reasoning with Python code execution for solving complex mathematical problems.
Qwen 2.5 Math 72B is a specialized large language model developed by Alibaba Cloud with 72.7 billion parameters, designed for solving advanced mathematical problems in English and Chinese. The model incorporates chain-of-thought reasoning and tool-integrated reasoning capabilities, enabling step-by-step problem solving and code execution for complex mathematical tasks, and demonstrates performance improvements over previous versions on standardized mathematical benchmarks.
Qwen 2.5 7B is a transformer-based language model developed by Alibaba Cloud with 7.61 billion parameters, trained on up to 18 trillion tokens from multilingual datasets. The model features grouped query attention, 128,000 token context length, and supports over 29 languages. As a base model requiring further fine-tuning, it provides capabilities for text generation, structured data processing, and multilingual applications under Apache 2.0 licensing.
Qwen2.5-32B is a 32.5 billion parameter decoder-only transformer language model developed by Alibaba Cloud's Qwen Team, featuring 64 layers with grouped query attention and supporting a 128,000 token context window. Trained on 18 trillion tokens across 29+ languages, the model demonstrates strong performance in coding, mathematics, and multilingual tasks. Released under Apache 2.0 license in September 2024, it serves as a base model intended for further post-training development rather than direct deployment.
Mistral Small (2409) is an instruction-tuned language model developed by Mistral AI with approximately 22 billion parameters and released in September 2024. The model supports function calling capabilities and processes input sequences up to 32,000 tokens. It features improvements in reasoning, alignment, and code generation compared to its predecessor, while being restricted to research and non-commercial use under Mistral AI's Research License.
CogVideoX-5B is a diffusion transformer model developed by THUDM for text-to-video and image-to-video synthesis, generating 10-second videos at 768x1360 resolution and 8 frames per second. The model employs a 3D causal VAE, 3D rotary position embeddings, and hybrid attention mechanisms to maintain temporal consistency across video sequences, trained on 35 million video clips and 2 billion images with comprehensive filtering and captioning processes.
Phi-3.5 Vision Instruct is a 4.2-billion-parameter multimodal model developed by Microsoft that processes both text and images within a 128,000-token context window. The model excels at multi-frame image analysis, visual question answering, document understanding, and video summarization tasks. Built on the Phi-3 Mini architecture with an integrated image encoder, it demonstrates strong performance on vision-language benchmarks while maintaining computational efficiency for deployment in resource-constrained environments.
CogVideoX-2B is an open-source text-to-video diffusion model developed by THUDM that generates videos up to 720×480 resolution and six seconds in length. The model employs a 3D causal variational autoencoder and Expert Transformer architecture with 3D rotary position embeddings for temporal coherence. Trained on 35 million video clips and 2 billion images using progressive training techniques, it supports INT8 quantization and is released under Apache 2.0 license.
FLUX.1 [dev] is a 12-billion-parameter text-to-image generation model developed by Black Forest Labs, utilizing a hybrid architecture with parallel diffusion transformer blocks and flow matching training. The model employs guidance distillation from FLUX.1 [pro] and supports variable aspect ratios with outputs ranging from 0.1 to 2.0 megapixels, released under a non-commercial license for research and personal use.
Stable Video 4D (SV4D) is a generative video-to-video diffusion model that produces consistent multi-view video sequences of dynamic objects from a single input video. The model synthesizes temporally and spatially coherent outputs from arbitrary viewpoints using a latent video diffusion architecture with spatial, view, and frame attention mechanisms, enabling efficient 4D asset generation for applications in design, game development, and research.
Stable Audio Open 1.0 is an open-weight text-to-audio synthesis model developed by Stability AI with approximately 1.21 billion parameters. Built on latent diffusion architecture with transformer components and T5-based text conditioning, the model generates up to 47 seconds of stereo audio at 44.1 kHz. Trained exclusively on Creative Commons-licensed data totaling 7,300 hours, it demonstrates strong performance for sound effects and field recordings while showing modest capabilities for instrumental music generation.
DeepSeek Coder V2 is an open-source Mixture-of-Experts code language model developed by DeepSeek AI, featuring 236 billion total parameters with 21 billion active parameters. The model supports 338 programming languages and extends up to 128,000 token context length. Trained on 10.2 trillion tokens of code, mathematics, and natural language data, it demonstrates competitive performance on code generation benchmarks like HumanEval and mathematical reasoning tasks.
Llama 3.1 8B is a multilingual large language model developed by Meta using a decoder-only transformer architecture with Grouped-Query Attention and a 128,000-token context window. The model is pretrained on 15 trillion tokens and undergoes supervised fine-tuning and reinforcement learning from human feedback. It supports eight languages and demonstrates competitive performance across benchmarks in reasoning, coding, mathematics, and multilingual tasks, distributed under the Llama 3.1 Community License.
Gemma 2 27B is a decoder-only transformer language model developed by Google, trained on 13 trillion tokens using JAX and ML Pathways on TPU hardware. The model achieves 75.2% accuracy on MMLU benchmarks and 51.8% on HumanEval programming tasks. It supports various text generation applications including content creation, dialogue systems, and code assistance, with openly accessible weights distributed under Google's responsible use policies.
Qwen2-7B is a 7.6 billion parameter decoder-only Transformer language model developed by Alibaba Cloud as part of the Qwen2 series. The model features Group Query Attention, SwiGLU activations, and supports a 32,000-token context length with extrapolation capabilities up to 128,000 tokens. Trained on a multilingual dataset covering 29 languages, it demonstrates competitive performance in coding, mathematics, and multilingual tasks compared to similarly-sized models like Mistral-7B and Llama-3-8B.
Codestral 22B v0.1 is an open-weight code generation model developed by Mistral AI with 22.2 billion parameters and support for over 80 programming languages. The model features a 32k token context window and operates in both "Instruct" and "Fill-in-the-Middle" modes, enabling natural language code queries and token prediction between code segments for IDE integration and repository-level tasks.
DeepSeek V2.5 is a 236 billion parameter Mixture-of-Experts language model that activates 21 billion parameters per token during inference. The architecture incorporates Multi-head Latent Attention for reduced memory usage and supports both English and Chinese with an extended context window of 128,000 tokens. Training utilized 8.1 trillion tokens with subsequent supervised fine-tuning and reinforcement learning alignment phases.
CodeGemma 1.1 7B is an open-weights language model developed by Google that specializes in code generation, completion, and understanding across multiple programming languages. Built on the Gemma architecture, it employs Fill-in-the-Middle training objectives and was trained on over 500 billion tokens comprising approximately 80% code and 20% natural language data, enabling both programming tasks and mathematical reasoning capabilities.
Llama 3 70B is a 70-billion-parameter decoder-only transformer language model developed by Meta and released in April 2024. The model employs grouped query attention, an 8,192-token context length, and a 128,000-token vocabulary, trained on over 15 trillion tokens from publicly available data. It demonstrates strong performance on benchmarks including MMLU, HumanEval, and GSM-8K, with specialized instruction tuning for dialogue and assistant applications.
Mixtral 8x22B is a Sparse Mixture of Experts language model developed by Mistral AI with 141 billion total parameters and 39 billion active parameters per token. The model supports multilingual text generation across English, French, German, Spanish, and Italian, with a 64,000-token context window. It demonstrates capabilities in reasoning, mathematics, and coding tasks, released under Apache 2.0 license.
Llama 4 Maverick (17Bx128E) is a multimodal large language model developed by Meta featuring a Mixture-of-Experts architecture with 17 billion active parameters from 400 billion total, distributed across 128 experts. The model integrates text and visual information through early fusion and was trained on approximately 22 trillion tokens across 200+ languages, demonstrating strong performance on multimodal reasoning, coding, and multilingual tasks while supporting context lengths up to 1 million tokens.
Stable Video 3D is a generative model developed by Stability AI that creates orbital videos from single static images, generating 21-frame sequences at 576x576 resolution that simulate a camera rotating around objects. Built on Stable Video Diffusion architecture and trained on Objaverse 3D renderings, it offers two variants: SV3D_u for autonomous camera paths and SV3D_p for user-specified trajectories.
Gemma 7B is a 7-billion-parameter open-source transformer-based language model developed by Google and released in February 2024. Trained on approximately 6 trillion tokens of primarily English text, code, and mathematical content, the model utilizes a decoder-only architecture and demonstrates competitive performance across natural language understanding, reasoning, and code generation benchmarks, achieving scores such as 64.3 on MMLU and 81.2 on HellaSwag evaluations.
Stable Cascade Stage A is a vector quantized generative adversarial network encoder that compresses 1024×1024 pixel images into 256×256 discrete tokens using a learned codebook. With 20 million parameters and fixed weights, this component serves as the decoder in Stable Cascade's three-stage hierarchical pipeline, reconstructing high-resolution images from compressed latent representations generated by the upstream stages.
Stable Cascade Stage C is a text-conditional latent diffusion model that operates as the third stage in Stable Cascade's hierarchical image generation architecture. It translates text prompts into compressed representations within a 24x24 spatial latent space for 1024x1024 images, utilizing CLIP-H embeddings for text conditioning. The stage supports fine-tuning adaptations including LoRA and ControlNet integration for various creative workflows.
Mistral Small 3 (2501) is a 24-billion-parameter instruction-fine-tuned language model developed by Mistral AI and released under an Apache 2.0 license. The model features a 32,000-token context window, multilingual capabilities across eleven languages, and demonstrates competitive performance on benchmarks including MMLU Pro, HumanEval, and instruction-following tasks while maintaining efficient inference speeds.
Qwen1.5-32B is a 32-billion parameter generative language model developed by Alibaba Cloud's Qwen Team and released in February 2024. The model supports up to 32,768 tokens of context length and demonstrates multilingual capabilities across European, East Asian, and Southeast Asian languages. It achieves competitive performance on language understanding and reasoning benchmarks, with an MMLU score of 73.4, and includes features for retrieval-augmented generation and external system integration.
The SD 1.5 Motion Model is a core component of the AnimateDiff framework that enables animation generation from Stable Diffusion 1.5-based text-to-image models. This motion module uses a temporal transformer architecture to add motion dynamics to existing image generation models without requiring retraining of the base model. Trained on the WebVid-10M dataset, it supports plug-and-play compatibility with personalized T2I models and enables controllable video synthesis through text prompts or sparse input controls.
SOLAR 10.7B is a large language model developed by Upstage AI using 10.7 billion parameters and a transformer architecture based on Llama 2. The model employs Depth Up-Scaling (DUS), which increases network depth by duplicating and concatenating layers from Mistral 7B initialization, resulting in a 48-layer architecture. Released in both pretrained and instruction-tuned variants under open-source licensing, it demonstrates competitive performance on standard benchmarks through multi-stage training including continued pretraining, instruction fine-tuning, and alignment optimization.
Seamless is a family of multilingual translation models developed by Meta that performs speech-to-speech, speech-to-text, text-to-speech, and text-to-text translation across 100 languages. The system comprises four integrated models: SeamlessM4T v2 (2.3 billion parameters), SeamlessExpressive for preserving vocal style and prosody, SeamlessStreaming for real-time low-latency translation, and a unified model combining expressivity with streaming capabilities for natural cross-lingual communication.
Stable Video Diffusion is a latent diffusion model developed by Stability AI that generates short video clips from single still images. Built upon Stable Diffusion 2.1 with added temporal convolution and attention layers, the model comprises 1.52 billion parameters and supports up to 25 frames at customizable frame rates. Trained on curated video datasets, SVD demonstrates competitive performance in image-to-video synthesis and multi-view generation tasks.
Yi 1.5 6B is a bilingual Transformer-based language model developed by 01.AI, trained on 3 trillion words of multilingual data. The model supports both English and Chinese for tasks including language understanding, commonsense reasoning, and reading comprehension. Available in base and chat variants with quantized versions, it is distributed under Apache 2.0 license for research and commercial use.
Whisper is a transformer-based automatic speech recognition model developed by OpenAI that performs multilingual transcription, speech translation, and language identification. Trained on 680,000 hours of diverse audio data across 98 languages, it uses an encoder-decoder architecture with special control tokens to handle multiple tasks. The model demonstrates robust performance across accents and noisy environments, with variants ranging from lightweight to high-accuracy configurations.
MAGNeT is a non-autoregressive Transformer model developed by Meta AI for generating music and sound effects from text descriptions. The model uses EnCodec tokenization and parallel codebook generation to achieve faster inference than autoregressive approaches while maintaining competitive quality metrics. MAGNeT is available in multiple variants with 300M to 1.5B parameters for research applications.
Mistral 7B is a 7.3 billion parameter transformer language model developed by Mistral AI and released under Apache 2.0 license. The model incorporates Grouped-Query Attention and Sliding-Window Attention to improve inference efficiency and handle longer sequences up to 8,192 tokens. It demonstrates competitive performance against larger models on reasoning, mathematics, and code generation benchmarks while maintaining a compact architecture suitable for various natural language processing applications.
Stable Diffusion XL is a text-to-image diffusion model developed by Stability AI featuring a two-stage architecture with a 3.5 billion parameter base model and a 6.6 billion parameter refiner. The model utilizes dual text encoders and generates images at 1024x1024 resolution with improved prompt adherence and compositional control compared to previous Stable Diffusion versions, while supporting fine-tuning and multi-aspect ratio training.
Llama 2 13B is a 13-billion parameter auto-regressive transformer language model developed by Meta for text generation and dialogue tasks. The model features a 4096-token context length and was pretrained on 2 trillion tokens across multiple languages. Available in both base and chat-optimized versions, it incorporates reinforcement learning from human feedback for improved safety and helpfulness in conversational applications.
MPT-7B is a 6.7 billion parameter decoder-only transformer model developed by MosaicML, trained on 1 trillion tokens of English text and code. The model features FlashAttention and ALiBi for efficient attention computation and extended context handling, enabling variants like StoryWriter-65k+ to process up to 65,000 tokens. Released under Apache 2.0 license, it serves as a foundation for further fine-tuning across various applications.
LLaMA 7B is a 7-billion parameter transformer-based language model developed by Meta AI and released in February 2023. Built using architectural improvements including RMSNorm, SwiGLU activation, and rotary positional embeddings, the model was trained on approximately one trillion tokens from publicly available datasets. It demonstrates capabilities in text generation, reasoning, and code generation across various benchmarks, though with limitations including potential biases and factual inaccuracies.
LLaMA 33B is a 32.5 billion parameter transformer-based language model developed by Meta AI as part of the LLaMA family. The model employs architectural enhancements including RMSNorm pre-normalization, SwiGLU activation functions, and rotary positional embeddings. It was trained on over 1.4 trillion tokens from publicly available datasets and demonstrates competitive performance across various language modeling and reasoning benchmarks while being released under a noncommercial research license.
AudioLDM is a text-to-audio generative model that creates speech, sound effects, and music from textual descriptions using latent diffusion techniques. The model employs Contrastive Language-Audio Pretraining (CLAP) embeddings and a variational autoencoder operating on mel-spectrogram representations. Trained on diverse datasets including AudioSet and AudioCaps, AudioLDM supports audio-to-audio generation, style transfer, super-resolution, and inpainting capabilities for creative and technical applications.
Demucs is an audio source separation model that decomposes music tracks into constituent stems such as vocals, drums, and bass. The latest version (v4) features Hybrid Transformer Demucs architecture, combining dual U-Nets operating in time and frequency domains with cross-domain transformer attention mechanisms. Released under MIT license, it achieves competitive performance on MUSDB HQ benchmarks for music production and research applications.
Tortoise TTS is an open-source text-to-speech system that combines autoregressive and diffusion-based architectures to generate realistic speech from text. The model supports voice cloning through reference audio clips and can produce multi-voice synthesis with controllable prosody and emotion through prompt engineering techniques. Trained on approximately 50,000 hours of speech data using a combination of transformer and diffusion models, Tortoise employs a contrastive language-voice model for output ranking and includes a neural vocoder for final waveform synthesis.
Gemma 3n E2B is a multimodal generative AI model developed by Google DeepMind that supports text, image, audio, and video inputs. Built on the MatFormer architecture with 6 billion raw parameters but 2 billion effective parameters, it employs Per-Layer Embeddings and KV Cache Sharing for efficient operation on resource-constrained devices. The model was trained on over 11 trillion tokens across 140+ languages with a June 2024 knowledge cutoff.
Mistral Small 3.2 (2506) is a 24-billion parameter text generation model developed by Mistral AI as an incremental update to Mistral Small 3.1. The model features improved instruction following, reduced repetition, enhanced function calling reliability, and maintained multimodal capabilities including vision processing. It supports up to 128,000 tokens context length and demonstrates performance improvements on benchmarks like Wildbench v2 and Arena Hard v2.
HiDream E1 Full is an instruction-based image editing model developed by HiDream-ai that enables natural language-guided modifications of existing images. Built upon the HiDream-I1 foundation model, it utilizes a 17-billion parameter sparse Diffusion Transformer architecture with Mixture-of-Experts components. The model supports various editing tasks including style transfer, object manipulation, and content addition or removal while preserving unmodified image regions through spatially weighted loss functions.
Qwen3-1.7B is a dense transformer language model with 1.7 billion parameters developed by Alibaba Cloud's Qwen Team. The model features dual-mode reasoning capabilities, operating in either "thinking" mode for step-by-step reasoning with intermediate computations or "non-thinking" mode for rapid direct responses. It supports 119 languages and utilizes a 32,768-token context window with grouped query attention architecture.
Qwen3-8B is a dense transformer-based language model developed by Alibaba Cloud featuring 8.2 billion parameters across 36 layers with Grouped Query Attention and 32,768-token native context length. The model supports hybrid thinking capabilities, enabling dynamic switching between systematic reasoning and rapid response modes, and was trained on 36 trillion tokens across 119 languages using multi-stage optimization including distillation from larger Qwen3 variants.
Qwen3-32B is a 32.8 billion parameter dense language model developed by Alibaba Cloud, featuring hybrid "thinking" modes that enable step-by-step reasoning for complex tasks or rapid responses for routine queries. The model supports 119 languages, extends to 32K token context length, and was trained on 36 trillion tokens using a four-stage post-training pipeline incorporating reinforcement learning and reasoning enhancement techniques.
Qwen3-235B-A22B is a Mixture-of-Experts language model developed by Alibaba Cloud's Qwen team, featuring 235 billion total parameters with 22 billion activated per inference step. The model offers dual operational modes—"thinking" for complex reasoning and "non-thinking" for rapid responses—enabling users to balance computational depth with inference speed. Trained on 36 trillion tokens across 119 languages, it supports advanced agentic workflows and demonstrates competitive performance on mathematical, coding, and multilingual benchmarks.
DeepSeek V3 (0324) is a Mixture-of-Experts language model with 671 billion total parameters and 37 billion activated per token, developed by DeepSeek AI. The model incorporates Multi-head Latent Attention, FP8 mixed-precision training, and Multi-Token Prediction techniques. It demonstrates strong performance in reasoning, code generation, and multilingual tasks, particularly Chinese, with support for 128K token contexts and availability under permissive open-source licensing.
Gemma 3 1B is a lightweight, multimodal generative AI model developed by Google DeepMind that processes both text and images to generate text outputs. Built on a decoder-only transformer architecture with local and global attention layers, the model supports a 32,000-token context window and was trained on 2 trillion tokens across 140+ languages. The model offers open-source pre-trained and instruction-tuned weights for research and practical applications.
Gemma 3 12B is a multimodal, instruction-tuned language model developed by Google DeepMind that processes both text and images to generate text outputs. The model features a decoder-only transformer architecture with a 400-million-parameter vision encoder and supports context windows up to 128,000 tokens. Trained on 12 trillion tokens across over 140 languages using knowledge distillation and reinforcement learning techniques, it demonstrates capabilities in mathematics, coding, and vision-language tasks while offering quantized variants for resource-efficient deployment.
Command A is a decoder-only transformer language model developed by Cohere for enterprise applications, featuring a 256,000-token context window and optimized for multilingual understanding, retrieval-augmented generation, code synthesis, and agentic workflows. The model employs grouped-query attention and architectural innovations for enhanced throughput, achieving competitive performance across academic benchmarks while demonstrating efficiency advantages in inference speed and memory usage compared to similar models.
Wan 2.1 T2V 1.3B is an open-source text-to-video generation model developed by Wan-AI, featuring 1.3 billion parameters and utilizing a Flow Matching framework with diffusion transformers. The model supports multilingual text-to-video synthesis in English and Chinese, operates efficiently on consumer GPUs requiring 8.19 GB VRAM, and generates 480P videos with capabilities for image-to-video conversion and text rendering within videos.
Wan 2.1 I2V 14B 720P is a 14-billion parameter image-to-video generation model developed by Wan-AI that converts single images into 720P videos. Built on a unified transformer-based diffusion architecture with a novel 3D causal VAE (Wan-VAE) for spatiotemporal compression, the model supports multilingual text prompts and demonstrates competitive performance in video generation benchmarks while maintaining computational efficiency across various GPU configurations.
Qwen2.5-VL-3B-Instruct is a multimodal large language model developed by Alibaba Cloud featuring 3 billion parameters. The model combines a Vision Transformer encoder with a Qwen2.5-series decoder to process images, videos, and text through dynamic resolution handling and temporal processing capabilities. It supports object detection, OCR, document analysis, video understanding, and computer interface automation, trained on approximately 1.4 trillion tokens across multiple modalities and released under Apache-2.0 license.
Qwen2.5-VL 72B is a 72-billion parameter multimodal generative AI model developed by Alibaba Cloud that integrates vision and language understanding. The model features dynamic resolution processing, temporal video alignment, and architectural enhancements over previous Qwen2-VL versions. It performs object detection, document parsing, video comprehension, OCR across multiple languages, and functions as a visual agent for interactive tasks, trained on over 1.4 trillion tokens.
DeepSeek R1 is a large language model developed by DeepSeek AI that employs a Mixture-of-Experts architecture with 671 billion total parameters and 37 billion activated during inference. The model utilizes reinforcement learning and supervised fine-tuning to enhance reasoning capabilities across mathematics, coding, and logic tasks, achieving competitive performance on benchmarks including 90.8 on MMLU and 97.3 on MATH-500.
DeepSeek V3 is a Mixture-of-Experts language model with 671 billion total parameters and 37 billion activated per token, developed by DeepSeek-AI. The model features Multi-head Latent Attention, auxiliary-loss-free load balancing, and FP8 mixed-precision training. Trained on 14.8 trillion tokens with a 128,000-token context window, it demonstrates competitive performance across reasoning, coding, and mathematical benchmarks while supporting multilingual capabilities and long-context processing.
DeepSeek VL2 Small is a 2.8 billion parameter multimodal vision-language model that uses a Mixture-of-Experts architecture with dynamic tiling for processing high-resolution images. Built on the DeepSeekMoE-16B framework with SigLIP vision encoding, it handles tasks including visual question answering, OCR, document analysis, and visual grounding across multiple languages, achieving competitive performance on benchmarks like DocVQA while maintaining computational efficiency through sparse expert routing.
Phi-4 is a 14-billion parameter decoder-only Transformer language model developed by Microsoft Research that focuses on mathematical reasoning and code generation through curated synthetic data training. The model supports a 16,000-token context window and achieves competitive performance on benchmarks like MMLU (84.8) and HumanEval (82.6) despite its relatively compact size, utilizing supervised fine-tuning and direct preference optimization for alignment.
HunyuanVideo is an open-source video generation model developed by Tencent that supports text-to-video, image-to-video, and controllable video synthesis. The model employs a Transformer-based architecture with a 3D Variational Autoencoder and utilizes flow matching for generating videos at variable resolutions and durations. It features 13 billion parameters and includes capabilities for avatar animation, audio synchronization, and multi-aspect ratio output generation.
CogVideoX 1.5 5B I2V is an image-to-video generation model developed by THUDM using a diffusion transformer architecture with 3D causal variational autoencoder. The model generates temporally coherent videos from input images and text prompts, supporting resolutions up to 1360 pixels and video lengths of 5-10 seconds at 16 fps, trained on 35 million curated video clips.
Qwen2.5-Coder-32B is a 32.5-billion parameter transformer-based language model developed by Alibaba Cloud, specifically designed for programming and code intelligence tasks. The model supports over 92 programming languages and features capabilities in code generation, completion, repair, and reasoning with a 128,000-token context window. Trained on approximately 5.5 trillion tokens of code and instructional data, it demonstrates performance across various coding benchmarks including HumanEval, MBPP, and multilingual programming evaluations.
Llama 3.2 3B is a multilingual instruction-tuned language model developed by Meta with 3 billion parameters and a 128,000-token context window. The model utilizes knowledge distillation from larger Llama variants, Grouped-Query Attention for efficient inference, and advanced quantization techniques optimized for PyTorch's ExecuTorch framework. Supporting eight languages, it targets assistant and agentic applications while enabling deployment in resource-constrained environments.
Qwen 2.5 Math 1.5B is a specialized language model developed by Alibaba Cloud for mathematical reasoning in English and Chinese. Built on the Qwen2.5 architecture with 4,096 token context length, it was trained on the Qwen Math Corpus v2 containing over one trillion tokens. The model supports chain-of-thought reasoning and tool-integrated reasoning with Python code execution for solving complex mathematical problems.
Qwen 2.5 Math 72B is a specialized large language model developed by Alibaba Cloud with 72.7 billion parameters, designed for solving advanced mathematical problems in English and Chinese. The model incorporates chain-of-thought reasoning and tool-integrated reasoning capabilities, enabling step-by-step problem solving and code execution for complex mathematical tasks, and demonstrates performance improvements over previous versions on standardized mathematical benchmarks.
Qwen 2.5 7B is a transformer-based language model developed by Alibaba Cloud with 7.61 billion parameters, trained on up to 18 trillion tokens from multilingual datasets. The model features grouped query attention, 128,000 token context length, and supports over 29 languages. As a base model requiring further fine-tuning, it provides capabilities for text generation, structured data processing, and multilingual applications under Apache 2.0 licensing.
Qwen2.5-32B is a 32.5 billion parameter decoder-only transformer language model developed by Alibaba Cloud's Qwen Team, featuring 64 layers with grouped query attention and supporting a 128,000 token context window. Trained on 18 trillion tokens across 29+ languages, the model demonstrates strong performance in coding, mathematics, and multilingual tasks. Released under Apache 2.0 license in September 2024, it serves as a base model intended for further post-training development rather than direct deployment.
Mistral Small (2409) is an instruction-tuned language model developed by Mistral AI with approximately 22 billion parameters and released in September 2024. The model supports function calling capabilities and processes input sequences up to 32,000 tokens. It features improvements in reasoning, alignment, and code generation compared to its predecessor, while being restricted to research and non-commercial use under Mistral AI's Research License.
CogVideoX-5B is a diffusion transformer model developed by THUDM for text-to-video and image-to-video synthesis, generating 10-second videos at 768x1360 resolution and 8 frames per second. The model employs a 3D causal VAE, 3D rotary position embeddings, and hybrid attention mechanisms to maintain temporal consistency across video sequences, trained on 35 million video clips and 2 billion images with comprehensive filtering and captioning processes.
Phi-3.5 Vision Instruct is a 4.2-billion-parameter multimodal model developed by Microsoft that processes both text and images within a 128,000-token context window. The model excels at multi-frame image analysis, visual question answering, document understanding, and video summarization tasks. Built on the Phi-3 Mini architecture with an integrated image encoder, it demonstrates strong performance on vision-language benchmarks while maintaining computational efficiency for deployment in resource-constrained environments.
CogVideoX-2B is an open-source text-to-video diffusion model developed by THUDM that generates videos up to 720×480 resolution and six seconds in length. The model employs a 3D causal variational autoencoder and Expert Transformer architecture with 3D rotary position embeddings for temporal coherence. Trained on 35 million video clips and 2 billion images using progressive training techniques, it supports INT8 quantization and is released under Apache 2.0 license.
FLUX.1 [dev] is a 12-billion-parameter text-to-image generation model developed by Black Forest Labs, utilizing a hybrid architecture with parallel diffusion transformer blocks and flow matching training. The model employs guidance distillation from FLUX.1 [pro] and supports variable aspect ratios with outputs ranging from 0.1 to 2.0 megapixels, released under a non-commercial license for research and personal use.
Stable Video 4D (SV4D) is a generative video-to-video diffusion model that produces consistent multi-view video sequences of dynamic objects from a single input video. The model synthesizes temporally and spatially coherent outputs from arbitrary viewpoints using a latent video diffusion architecture with spatial, view, and frame attention mechanisms, enabling efficient 4D asset generation for applications in design, game development, and research.
Stable Audio Open 1.0 is an open-weight text-to-audio synthesis model developed by Stability AI with approximately 1.21 billion parameters. Built on latent diffusion architecture with transformer components and T5-based text conditioning, the model generates up to 47 seconds of stereo audio at 44.1 kHz. Trained exclusively on Creative Commons-licensed data totaling 7,300 hours, it demonstrates strong performance for sound effects and field recordings while showing modest capabilities for instrumental music generation.
DeepSeek Coder V2 is an open-source Mixture-of-Experts code language model developed by DeepSeek AI, featuring 236 billion total parameters with 21 billion active parameters. The model supports 338 programming languages and extends up to 128,000 token context length. Trained on 10.2 trillion tokens of code, mathematics, and natural language data, it demonstrates competitive performance on code generation benchmarks like HumanEval and mathematical reasoning tasks.
Llama 3.1 8B is a multilingual large language model developed by Meta using a decoder-only transformer architecture with Grouped-Query Attention and a 128,000-token context window. The model is pretrained on 15 trillion tokens and undergoes supervised fine-tuning and reinforcement learning from human feedback. It supports eight languages and demonstrates competitive performance across benchmarks in reasoning, coding, mathematics, and multilingual tasks, distributed under the Llama 3.1 Community License.
Gemma 2 27B is a decoder-only transformer language model developed by Google, trained on 13 trillion tokens using JAX and ML Pathways on TPU hardware. The model achieves 75.2% accuracy on MMLU benchmarks and 51.8% on HumanEval programming tasks. It supports various text generation applications including content creation, dialogue systems, and code assistance, with openly accessible weights distributed under Google's responsible use policies.
Qwen2-7B is a 7.6 billion parameter decoder-only Transformer language model developed by Alibaba Cloud as part of the Qwen2 series. The model features Group Query Attention, SwiGLU activations, and supports a 32,000-token context length with extrapolation capabilities up to 128,000 tokens. Trained on a multilingual dataset covering 29 languages, it demonstrates competitive performance in coding, mathematics, and multilingual tasks compared to similarly-sized models like Mistral-7B and Llama-3-8B.
Codestral 22B v0.1 is an open-weight code generation model developed by Mistral AI with 22.2 billion parameters and support for over 80 programming languages. The model features a 32k token context window and operates in both "Instruct" and "Fill-in-the-Middle" modes, enabling natural language code queries and token prediction between code segments for IDE integration and repository-level tasks.
DeepSeek V2.5 is a 236 billion parameter Mixture-of-Experts language model that activates 21 billion parameters per token during inference. The architecture incorporates Multi-head Latent Attention for reduced memory usage and supports both English and Chinese with an extended context window of 128,000 tokens. Training utilized 8.1 trillion tokens with subsequent supervised fine-tuning and reinforcement learning alignment phases.
CodeGemma 1.1 7B is an open-weights language model developed by Google that specializes in code generation, completion, and understanding across multiple programming languages. Built on the Gemma architecture, it employs Fill-in-the-Middle training objectives and was trained on over 500 billion tokens comprising approximately 80% code and 20% natural language data, enabling both programming tasks and mathematical reasoning capabilities.
Llama 3 70B is a 70-billion-parameter decoder-only transformer language model developed by Meta and released in April 2024. The model employs grouped query attention, an 8,192-token context length, and a 128,000-token vocabulary, trained on over 15 trillion tokens from publicly available data. It demonstrates strong performance on benchmarks including MMLU, HumanEval, and GSM-8K, with specialized instruction tuning for dialogue and assistant applications.
Mixtral 8x22B is a Sparse Mixture of Experts language model developed by Mistral AI with 141 billion total parameters and 39 billion active parameters per token. The model supports multilingual text generation across English, French, German, Spanish, and Italian, with a 64,000-token context window. It demonstrates capabilities in reasoning, mathematics, and coding tasks, released under Apache 2.0 license.
Llama 4 Maverick (17Bx128E) is a multimodal large language model developed by Meta featuring a Mixture-of-Experts architecture with 17 billion active parameters from 400 billion total, distributed across 128 experts. The model integrates text and visual information through early fusion and was trained on approximately 22 trillion tokens across 200+ languages, demonstrating strong performance on multimodal reasoning, coding, and multilingual tasks while supporting context lengths up to 1 million tokens.
Stable Video 3D is a generative model developed by Stability AI that creates orbital videos from single static images, generating 21-frame sequences at 576x576 resolution that simulate a camera rotating around objects. Built on Stable Video Diffusion architecture and trained on Objaverse 3D renderings, it offers two variants: SV3D_u for autonomous camera paths and SV3D_p for user-specified trajectories.
Gemma 7B is a 7-billion-parameter open-source transformer-based language model developed by Google and released in February 2024. Trained on approximately 6 trillion tokens of primarily English text, code, and mathematical content, the model utilizes a decoder-only architecture and demonstrates competitive performance across natural language understanding, reasoning, and code generation benchmarks, achieving scores such as 64.3 on MMLU and 81.2 on HellaSwag evaluations.
Stable Cascade Stage A is a vector quantized generative adversarial network encoder that compresses 1024×1024 pixel images into 256×256 discrete tokens using a learned codebook. With 20 million parameters and fixed weights, this component serves as the decoder in Stable Cascade's three-stage hierarchical pipeline, reconstructing high-resolution images from compressed latent representations generated by the upstream stages.
Stable Cascade Stage C is a text-conditional latent diffusion model that operates as the third stage in Stable Cascade's hierarchical image generation architecture. It translates text prompts into compressed representations within a 24x24 spatial latent space for 1024x1024 images, utilizing CLIP-H embeddings for text conditioning. The stage supports fine-tuning adaptations including LoRA and ControlNet integration for various creative workflows.
Mistral Small 3 (2501) is a 24-billion-parameter instruction-fine-tuned language model developed by Mistral AI and released under an Apache 2.0 license. The model features a 32,000-token context window, multilingual capabilities across eleven languages, and demonstrates competitive performance on benchmarks including MMLU Pro, HumanEval, and instruction-following tasks while maintaining efficient inference speeds.
Qwen1.5-32B is a 32-billion parameter generative language model developed by Alibaba Cloud's Qwen Team and released in February 2024. The model supports up to 32,768 tokens of context length and demonstrates multilingual capabilities across European, East Asian, and Southeast Asian languages. It achieves competitive performance on language understanding and reasoning benchmarks, with an MMLU score of 73.4, and includes features for retrieval-augmented generation and external system integration.
The SD 1.5 Motion Model is a core component of the AnimateDiff framework that enables animation generation from Stable Diffusion 1.5-based text-to-image models. This motion module uses a temporal transformer architecture to add motion dynamics to existing image generation models without requiring retraining of the base model. Trained on the WebVid-10M dataset, it supports plug-and-play compatibility with personalized T2I models and enables controllable video synthesis through text prompts or sparse input controls.
SOLAR 10.7B is a large language model developed by Upstage AI using 10.7 billion parameters and a transformer architecture based on Llama 2. The model employs Depth Up-Scaling (DUS), which increases network depth by duplicating and concatenating layers from Mistral 7B initialization, resulting in a 48-layer architecture. Released in both pretrained and instruction-tuned variants under open-source licensing, it demonstrates competitive performance on standard benchmarks through multi-stage training including continued pretraining, instruction fine-tuning, and alignment optimization.
Seamless is a family of multilingual translation models developed by Meta that performs speech-to-speech, speech-to-text, text-to-speech, and text-to-text translation across 100 languages. The system comprises four integrated models: SeamlessM4T v2 (2.3 billion parameters), SeamlessExpressive for preserving vocal style and prosody, SeamlessStreaming for real-time low-latency translation, and a unified model combining expressivity with streaming capabilities for natural cross-lingual communication.
Stable Video Diffusion is a latent diffusion model developed by Stability AI that generates short video clips from single still images. Built upon Stable Diffusion 2.1 with added temporal convolution and attention layers, the model comprises 1.52 billion parameters and supports up to 25 frames at customizable frame rates. Trained on curated video datasets, SVD demonstrates competitive performance in image-to-video synthesis and multi-view generation tasks.
Yi 1.5 6B is a bilingual Transformer-based language model developed by 01.AI, trained on 3 trillion words of multilingual data. The model supports both English and Chinese for tasks including language understanding, commonsense reasoning, and reading comprehension. Available in base and chat variants with quantized versions, it is distributed under Apache 2.0 license for research and commercial use.
Whisper is a transformer-based automatic speech recognition model developed by OpenAI that performs multilingual transcription, speech translation, and language identification. Trained on 680,000 hours of diverse audio data across 98 languages, it uses an encoder-decoder architecture with special control tokens to handle multiple tasks. The model demonstrates robust performance across accents and noisy environments, with variants ranging from lightweight to high-accuracy configurations.
MAGNeT is a non-autoregressive Transformer model developed by Meta AI for generating music and sound effects from text descriptions. The model uses EnCodec tokenization and parallel codebook generation to achieve faster inference than autoregressive approaches while maintaining competitive quality metrics. MAGNeT is available in multiple variants with 300M to 1.5B parameters for research applications.
Mistral 7B is a 7.3 billion parameter transformer language model developed by Mistral AI and released under Apache 2.0 license. The model incorporates Grouped-Query Attention and Sliding-Window Attention to improve inference efficiency and handle longer sequences up to 8,192 tokens. It demonstrates competitive performance against larger models on reasoning, mathematics, and code generation benchmarks while maintaining a compact architecture suitable for various natural language processing applications.
Stable Diffusion XL is a text-to-image diffusion model developed by Stability AI featuring a two-stage architecture with a 3.5 billion parameter base model and a 6.6 billion parameter refiner. The model utilizes dual text encoders and generates images at 1024x1024 resolution with improved prompt adherence and compositional control compared to previous Stable Diffusion versions, while supporting fine-tuning and multi-aspect ratio training.
Llama 2 13B is a 13-billion parameter auto-regressive transformer language model developed by Meta for text generation and dialogue tasks. The model features a 4096-token context length and was pretrained on 2 trillion tokens across multiple languages. Available in both base and chat-optimized versions, it incorporates reinforcement learning from human feedback for improved safety and helpfulness in conversational applications.
MPT-7B is a 6.7 billion parameter decoder-only transformer model developed by MosaicML, trained on 1 trillion tokens of English text and code. The model features FlashAttention and ALiBi for efficient attention computation and extended context handling, enabling variants like StoryWriter-65k+ to process up to 65,000 tokens. Released under Apache 2.0 license, it serves as a foundation for further fine-tuning across various applications.
LLaMA 7B is a 7-billion parameter transformer-based language model developed by Meta AI and released in February 2023. Built using architectural improvements including RMSNorm, SwiGLU activation, and rotary positional embeddings, the model was trained on approximately one trillion tokens from publicly available datasets. It demonstrates capabilities in text generation, reasoning, and code generation across various benchmarks, though with limitations including potential biases and factual inaccuracies.
LLaMA 33B is a 32.5 billion parameter transformer-based language model developed by Meta AI as part of the LLaMA family. The model employs architectural enhancements including RMSNorm pre-normalization, SwiGLU activation functions, and rotary positional embeddings. It was trained on over 1.4 trillion tokens from publicly available datasets and demonstrates competitive performance across various language modeling and reasoning benchmarks while being released under a noncommercial research license.
AudioLDM is a text-to-audio generative model that creates speech, sound effects, and music from textual descriptions using latent diffusion techniques. The model employs Contrastive Language-Audio Pretraining (CLAP) embeddings and a variational autoencoder operating on mel-spectrogram representations. Trained on diverse datasets including AudioSet and AudioCaps, AudioLDM supports audio-to-audio generation, style transfer, super-resolution, and inpainting capabilities for creative and technical applications.
Demucs is an audio source separation model that decomposes music tracks into constituent stems such as vocals, drums, and bass. The latest version (v4) features Hybrid Transformer Demucs architecture, combining dual U-Nets operating in time and frequency domains with cross-domain transformer attention mechanisms. Released under MIT license, it achieves competitive performance on MUSDB HQ benchmarks for music production and research applications.
Tortoise TTS is an open-source text-to-speech system that combines autoregressive and diffusion-based architectures to generate realistic speech from text. The model supports voice cloning through reference audio clips and can produce multi-voice synthesis with controllable prosody and emotion through prompt engineering techniques. Trained on approximately 50,000 hours of speech data using a combination of transformer and diffusion models, Tortoise employs a contrastive language-voice model for output ranking and includes a neural vocoder for final waveform synthesis.
Gemma 3n E2B is a multimodal generative AI model developed by Google DeepMind that supports text, image, audio, and video inputs. Built on the MatFormer architecture with 6 billion raw parameters but 2 billion effective parameters, it employs Per-Layer Embeddings and KV Cache Sharing for efficient operation on resource-constrained devices. The model was trained on over 11 trillion tokens across 140+ languages with a June 2024 knowledge cutoff.
Mistral Small 3.2 (2506) is a 24-billion parameter text generation model developed by Mistral AI as an incremental update to Mistral Small 3.1. The model features improved instruction following, reduced repetition, enhanced function calling reliability, and maintained multimodal capabilities including vision processing. It supports up to 128,000 tokens context length and demonstrates performance improvements on benchmarks like Wildbench v2 and Arena Hard v2.
HiDream E1 Full is an instruction-based image editing model developed by HiDream-ai that enables natural language-guided modifications of existing images. Built upon the HiDream-I1 foundation model, it utilizes a 17-billion parameter sparse Diffusion Transformer architecture with Mixture-of-Experts components. The model supports various editing tasks including style transfer, object manipulation, and content addition or removal while preserving unmodified image regions through spatially weighted loss functions.
Qwen3-1.7B is a dense transformer language model with 1.7 billion parameters developed by Alibaba Cloud's Qwen Team. The model features dual-mode reasoning capabilities, operating in either "thinking" mode for step-by-step reasoning with intermediate computations or "non-thinking" mode for rapid direct responses. It supports 119 languages and utilizes a 32,768-token context window with grouped query attention architecture.
Qwen3-8B is a dense transformer-based language model developed by Alibaba Cloud featuring 8.2 billion parameters across 36 layers with Grouped Query Attention and 32,768-token native context length. The model supports hybrid thinking capabilities, enabling dynamic switching between systematic reasoning and rapid response modes, and was trained on 36 trillion tokens across 119 languages using multi-stage optimization including distillation from larger Qwen3 variants.
Qwen3-32B is a 32.8 billion parameter dense language model developed by Alibaba Cloud, featuring hybrid "thinking" modes that enable step-by-step reasoning for complex tasks or rapid responses for routine queries. The model supports 119 languages, extends to 32K token context length, and was trained on 36 trillion tokens using a four-stage post-training pipeline incorporating reinforcement learning and reasoning enhancement techniques.
Qwen3-235B-A22B is a Mixture-of-Experts language model developed by Alibaba Cloud's Qwen team, featuring 235 billion total parameters with 22 billion activated per inference step. The model offers dual operational modes—"thinking" for complex reasoning and "non-thinking" for rapid responses—enabling users to balance computational depth with inference speed. Trained on 36 trillion tokens across 119 languages, it supports advanced agentic workflows and demonstrates competitive performance on mathematical, coding, and multilingual benchmarks.
DeepSeek V3 (0324) is a Mixture-of-Experts language model with 671 billion total parameters and 37 billion activated per token, developed by DeepSeek AI. The model incorporates Multi-head Latent Attention, FP8 mixed-precision training, and Multi-Token Prediction techniques. It demonstrates strong performance in reasoning, code generation, and multilingual tasks, particularly Chinese, with support for 128K token contexts and availability under permissive open-source licensing.
Gemma 3 1B is a lightweight, multimodal generative AI model developed by Google DeepMind that processes both text and images to generate text outputs. Built on a decoder-only transformer architecture with local and global attention layers, the model supports a 32,000-token context window and was trained on 2 trillion tokens across 140+ languages. The model offers open-source pre-trained and instruction-tuned weights for research and practical applications.
Gemma 3 12B is a multimodal, instruction-tuned language model developed by Google DeepMind that processes both text and images to generate text outputs. The model features a decoder-only transformer architecture with a 400-million-parameter vision encoder and supports context windows up to 128,000 tokens. Trained on 12 trillion tokens across over 140 languages using knowledge distillation and reinforcement learning techniques, it demonstrates capabilities in mathematics, coding, and vision-language tasks while offering quantized variants for resource-efficient deployment.
Command A is a decoder-only transformer language model developed by Cohere for enterprise applications, featuring a 256,000-token context window and optimized for multilingual understanding, retrieval-augmented generation, code synthesis, and agentic workflows. The model employs grouped-query attention and architectural innovations for enhanced throughput, achieving competitive performance across academic benchmarks while demonstrating efficiency advantages in inference speed and memory usage compared to similar models.
Wan 2.1 T2V 1.3B is an open-source text-to-video generation model developed by Wan-AI, featuring 1.3 billion parameters and utilizing a Flow Matching framework with diffusion transformers. The model supports multilingual text-to-video synthesis in English and Chinese, operates efficiently on consumer GPUs requiring 8.19 GB VRAM, and generates 480P videos with capabilities for image-to-video conversion and text rendering within videos.
Wan 2.1 I2V 14B 720P is a 14-billion parameter image-to-video generation model developed by Wan-AI that converts single images into 720P videos. Built on a unified transformer-based diffusion architecture with a novel 3D causal VAE (Wan-VAE) for spatiotemporal compression, the model supports multilingual text prompts and demonstrates competitive performance in video generation benchmarks while maintaining computational efficiency across various GPU configurations.
Qwen2.5-VL-3B-Instruct is a multimodal large language model developed by Alibaba Cloud featuring 3 billion parameters. The model combines a Vision Transformer encoder with a Qwen2.5-series decoder to process images, videos, and text through dynamic resolution handling and temporal processing capabilities. It supports object detection, OCR, document analysis, video understanding, and computer interface automation, trained on approximately 1.4 trillion tokens across multiple modalities and released under Apache-2.0 license.
Qwen2.5-VL 72B is a 72-billion parameter multimodal generative AI model developed by Alibaba Cloud that integrates vision and language understanding. The model features dynamic resolution processing, temporal video alignment, and architectural enhancements over previous Qwen2-VL versions. It performs object detection, document parsing, video comprehension, OCR across multiple languages, and functions as a visual agent for interactive tasks, trained on over 1.4 trillion tokens.
DeepSeek R1 is a large language model developed by DeepSeek AI that employs a Mixture-of-Experts architecture with 671 billion total parameters and 37 billion activated during inference. The model utilizes reinforcement learning and supervised fine-tuning to enhance reasoning capabilities across mathematics, coding, and logic tasks, achieving competitive performance on benchmarks including 90.8 on MMLU and 97.3 on MATH-500.
DeepSeek V3 is a Mixture-of-Experts language model with 671 billion total parameters and 37 billion activated per token, developed by DeepSeek-AI. The model features Multi-head Latent Attention, auxiliary-loss-free load balancing, and FP8 mixed-precision training. Trained on 14.8 trillion tokens with a 128,000-token context window, it demonstrates competitive performance across reasoning, coding, and mathematical benchmarks while supporting multilingual capabilities and long-context processing.
DeepSeek VL2 Small is a 2.8 billion parameter multimodal vision-language model that uses a Mixture-of-Experts architecture with dynamic tiling for processing high-resolution images. Built on the DeepSeekMoE-16B framework with SigLIP vision encoding, it handles tasks including visual question answering, OCR, document analysis, and visual grounding across multiple languages, achieving competitive performance on benchmarks like DocVQA while maintaining computational efficiency through sparse expert routing.
Phi-4 is a 14-billion parameter decoder-only Transformer language model developed by Microsoft Research that focuses on mathematical reasoning and code generation through curated synthetic data training. The model supports a 16,000-token context window and achieves competitive performance on benchmarks like MMLU (84.8) and HumanEval (82.6) despite its relatively compact size, utilizing supervised fine-tuning and direct preference optimization for alignment.
HunyuanVideo is an open-source video generation model developed by Tencent that supports text-to-video, image-to-video, and controllable video synthesis. The model employs a Transformer-based architecture with a 3D Variational Autoencoder and utilizes flow matching for generating videos at variable resolutions and durations. It features 13 billion parameters and includes capabilities for avatar animation, audio synchronization, and multi-aspect ratio output generation.
CogVideoX 1.5 5B I2V is an image-to-video generation model developed by THUDM using a diffusion transformer architecture with 3D causal variational autoencoder. The model generates temporally coherent videos from input images and text prompts, supporting resolutions up to 1360 pixels and video lengths of 5-10 seconds at 16 fps, trained on 35 million curated video clips.
Qwen2.5-Coder-32B is a 32.5-billion parameter transformer-based language model developed by Alibaba Cloud, specifically designed for programming and code intelligence tasks. The model supports over 92 programming languages and features capabilities in code generation, completion, repair, and reasoning with a 128,000-token context window. Trained on approximately 5.5 trillion tokens of code and instructional data, it demonstrates performance across various coding benchmarks including HumanEval, MBPP, and multilingual programming evaluations.
Llama 3.2 3B is a multilingual instruction-tuned language model developed by Meta with 3 billion parameters and a 128,000-token context window. The model utilizes knowledge distillation from larger Llama variants, Grouped-Query Attention for efficient inference, and advanced quantization techniques optimized for PyTorch's ExecuTorch framework. Supporting eight languages, it targets assistant and agentic applications while enabling deployment in resource-constrained environments.
Qwen 2.5 Math 1.5B is a specialized language model developed by Alibaba Cloud for mathematical reasoning in English and Chinese. Built on the Qwen2.5 architecture with 4,096 token context length, it was trained on the Qwen Math Corpus v2 containing over one trillion tokens. The model supports chain-of-thought reasoning and tool-integrated reasoning with Python code execution for solving complex mathematical problems.
Qwen 2.5 Math 72B is a specialized large language model developed by Alibaba Cloud with 72.7 billion parameters, designed for solving advanced mathematical problems in English and Chinese. The model incorporates chain-of-thought reasoning and tool-integrated reasoning capabilities, enabling step-by-step problem solving and code execution for complex mathematical tasks, and demonstrates performance improvements over previous versions on standardized mathematical benchmarks.
Qwen 2.5 7B is a transformer-based language model developed by Alibaba Cloud with 7.61 billion parameters, trained on up to 18 trillion tokens from multilingual datasets. The model features grouped query attention, 128,000 token context length, and supports over 29 languages. As a base model requiring further fine-tuning, it provides capabilities for text generation, structured data processing, and multilingual applications under Apache 2.0 licensing.
Qwen2.5-32B is a 32.5 billion parameter decoder-only transformer language model developed by Alibaba Cloud's Qwen Team, featuring 64 layers with grouped query attention and supporting a 128,000 token context window. Trained on 18 trillion tokens across 29+ languages, the model demonstrates strong performance in coding, mathematics, and multilingual tasks. Released under Apache 2.0 license in September 2024, it serves as a base model intended for further post-training development rather than direct deployment.
Mistral Small (2409) is an instruction-tuned language model developed by Mistral AI with approximately 22 billion parameters and released in September 2024. The model supports function calling capabilities and processes input sequences up to 32,000 tokens. It features improvements in reasoning, alignment, and code generation compared to its predecessor, while being restricted to research and non-commercial use under Mistral AI's Research License.
CogVideoX-5B is a diffusion transformer model developed by THUDM for text-to-video and image-to-video synthesis, generating 10-second videos at 768x1360 resolution and 8 frames per second. The model employs a 3D causal VAE, 3D rotary position embeddings, and hybrid attention mechanisms to maintain temporal consistency across video sequences, trained on 35 million video clips and 2 billion images with comprehensive filtering and captioning processes.
Phi-3.5 Vision Instruct is a 4.2-billion-parameter multimodal model developed by Microsoft that processes both text and images within a 128,000-token context window. The model excels at multi-frame image analysis, visual question answering, document understanding, and video summarization tasks. Built on the Phi-3 Mini architecture with an integrated image encoder, it demonstrates strong performance on vision-language benchmarks while maintaining computational efficiency for deployment in resource-constrained environments.
CogVideoX-2B is an open-source text-to-video diffusion model developed by THUDM that generates videos up to 720×480 resolution and six seconds in length. The model employs a 3D causal variational autoencoder and Expert Transformer architecture with 3D rotary position embeddings for temporal coherence. Trained on 35 million video clips and 2 billion images using progressive training techniques, it supports INT8 quantization and is released under Apache 2.0 license.
FLUX.1 [dev] is a 12-billion-parameter text-to-image generation model developed by Black Forest Labs, utilizing a hybrid architecture with parallel diffusion transformer blocks and flow matching training. The model employs guidance distillation from FLUX.1 [pro] and supports variable aspect ratios with outputs ranging from 0.1 to 2.0 megapixels, released under a non-commercial license for research and personal use.
Stable Video 4D (SV4D) is a generative video-to-video diffusion model that produces consistent multi-view video sequences of dynamic objects from a single input video. The model synthesizes temporally and spatially coherent outputs from arbitrary viewpoints using a latent video diffusion architecture with spatial, view, and frame attention mechanisms, enabling efficient 4D asset generation for applications in design, game development, and research.
Stable Audio Open 1.0 is an open-weight text-to-audio synthesis model developed by Stability AI with approximately 1.21 billion parameters. Built on latent diffusion architecture with transformer components and T5-based text conditioning, the model generates up to 47 seconds of stereo audio at 44.1 kHz. Trained exclusively on Creative Commons-licensed data totaling 7,300 hours, it demonstrates strong performance for sound effects and field recordings while showing modest capabilities for instrumental music generation.
DeepSeek Coder V2 is an open-source Mixture-of-Experts code language model developed by DeepSeek AI, featuring 236 billion total parameters with 21 billion active parameters. The model supports 338 programming languages and extends up to 128,000 token context length. Trained on 10.2 trillion tokens of code, mathematics, and natural language data, it demonstrates competitive performance on code generation benchmarks like HumanEval and mathematical reasoning tasks.
Llama 3.1 8B is a multilingual large language model developed by Meta using a decoder-only transformer architecture with Grouped-Query Attention and a 128,000-token context window. The model is pretrained on 15 trillion tokens and undergoes supervised fine-tuning and reinforcement learning from human feedback. It supports eight languages and demonstrates competitive performance across benchmarks in reasoning, coding, mathematics, and multilingual tasks, distributed under the Llama 3.1 Community License.
Gemma 2 27B is a decoder-only transformer language model developed by Google, trained on 13 trillion tokens using JAX and ML Pathways on TPU hardware. The model achieves 75.2% accuracy on MMLU benchmarks and 51.8% on HumanEval programming tasks. It supports various text generation applications including content creation, dialogue systems, and code assistance, with openly accessible weights distributed under Google's responsible use policies.
Qwen2-7B is a 7.6 billion parameter decoder-only Transformer language model developed by Alibaba Cloud as part of the Qwen2 series. The model features Group Query Attention, SwiGLU activations, and supports a 32,000-token context length with extrapolation capabilities up to 128,000 tokens. Trained on a multilingual dataset covering 29 languages, it demonstrates competitive performance in coding, mathematics, and multilingual tasks compared to similarly-sized models like Mistral-7B and Llama-3-8B.
Codestral 22B v0.1 is an open-weight code generation model developed by Mistral AI with 22.2 billion parameters and support for over 80 programming languages. The model features a 32k token context window and operates in both "Instruct" and "Fill-in-the-Middle" modes, enabling natural language code queries and token prediction between code segments for IDE integration and repository-level tasks.
DeepSeek V2.5 is a 236 billion parameter Mixture-of-Experts language model that activates 21 billion parameters per token during inference. The architecture incorporates Multi-head Latent Attention for reduced memory usage and supports both English and Chinese with an extended context window of 128,000 tokens. Training utilized 8.1 trillion tokens with subsequent supervised fine-tuning and reinforcement learning alignment phases.
CodeGemma 1.1 7B is an open-weights language model developed by Google that specializes in code generation, completion, and understanding across multiple programming languages. Built on the Gemma architecture, it employs Fill-in-the-Middle training objectives and was trained on over 500 billion tokens comprising approximately 80% code and 20% natural language data, enabling both programming tasks and mathematical reasoning capabilities.
Llama 3 70B is a 70-billion-parameter decoder-only transformer language model developed by Meta and released in April 2024. The model employs grouped query attention, an 8,192-token context length, and a 128,000-token vocabulary, trained on over 15 trillion tokens from publicly available data. It demonstrates strong performance on benchmarks including MMLU, HumanEval, and GSM-8K, with specialized instruction tuning for dialogue and assistant applications.
Mixtral 8x22B is a Sparse Mixture of Experts language model developed by Mistral AI with 141 billion total parameters and 39 billion active parameters per token. The model supports multilingual text generation across English, French, German, Spanish, and Italian, with a 64,000-token context window. It demonstrates capabilities in reasoning, mathematics, and coding tasks, released under Apache 2.0 license.
Llama 4 Maverick (17Bx128E) is a multimodal large language model developed by Meta featuring a Mixture-of-Experts architecture with 17 billion active parameters from 400 billion total, distributed across 128 experts. The model integrates text and visual information through early fusion and was trained on approximately 22 trillion tokens across 200+ languages, demonstrating strong performance on multimodal reasoning, coding, and multilingual tasks while supporting context lengths up to 1 million tokens.
Stable Video 3D is a generative model developed by Stability AI that creates orbital videos from single static images, generating 21-frame sequences at 576x576 resolution that simulate a camera rotating around objects. Built on Stable Video Diffusion architecture and trained on Objaverse 3D renderings, it offers two variants: SV3D_u for autonomous camera paths and SV3D_p for user-specified trajectories.
Gemma 7B is a 7-billion-parameter open-source transformer-based language model developed by Google and released in February 2024. Trained on approximately 6 trillion tokens of primarily English text, code, and mathematical content, the model utilizes a decoder-only architecture and demonstrates competitive performance across natural language understanding, reasoning, and code generation benchmarks, achieving scores such as 64.3 on MMLU and 81.2 on HellaSwag evaluations.
Stable Cascade Stage A is a vector quantized generative adversarial network encoder that compresses 1024×1024 pixel images into 256×256 discrete tokens using a learned codebook. With 20 million parameters and fixed weights, this component serves as the decoder in Stable Cascade's three-stage hierarchical pipeline, reconstructing high-resolution images from compressed latent representations generated by the upstream stages.
Stable Cascade Stage C is a text-conditional latent diffusion model that operates as the third stage in Stable Cascade's hierarchical image generation architecture. It translates text prompts into compressed representations within a 24x24 spatial latent space for 1024x1024 images, utilizing CLIP-H embeddings for text conditioning. The stage supports fine-tuning adaptations including LoRA and ControlNet integration for various creative workflows.
Mistral Small 3 (2501) is a 24-billion-parameter instruction-fine-tuned language model developed by Mistral AI and released under an Apache 2.0 license. The model features a 32,000-token context window, multilingual capabilities across eleven languages, and demonstrates competitive performance on benchmarks including MMLU Pro, HumanEval, and instruction-following tasks while maintaining efficient inference speeds.
Qwen1.5-32B is a 32-billion parameter generative language model developed by Alibaba Cloud's Qwen Team and released in February 2024. The model supports up to 32,768 tokens of context length and demonstrates multilingual capabilities across European, East Asian, and Southeast Asian languages. It achieves competitive performance on language understanding and reasoning benchmarks, with an MMLU score of 73.4, and includes features for retrieval-augmented generation and external system integration.
The SD 1.5 Motion Model is a core component of the AnimateDiff framework that enables animation generation from Stable Diffusion 1.5-based text-to-image models. This motion module uses a temporal transformer architecture to add motion dynamics to existing image generation models without requiring retraining of the base model. Trained on the WebVid-10M dataset, it supports plug-and-play compatibility with personalized T2I models and enables controllable video synthesis through text prompts or sparse input controls.
SOLAR 10.7B is a large language model developed by Upstage AI using 10.7 billion parameters and a transformer architecture based on Llama 2. The model employs Depth Up-Scaling (DUS), which increases network depth by duplicating and concatenating layers from Mistral 7B initialization, resulting in a 48-layer architecture. Released in both pretrained and instruction-tuned variants under open-source licensing, it demonstrates competitive performance on standard benchmarks through multi-stage training including continued pretraining, instruction fine-tuning, and alignment optimization.
Seamless is a family of multilingual translation models developed by Meta that performs speech-to-speech, speech-to-text, text-to-speech, and text-to-text translation across 100 languages. The system comprises four integrated models: SeamlessM4T v2 (2.3 billion parameters), SeamlessExpressive for preserving vocal style and prosody, SeamlessStreaming for real-time low-latency translation, and a unified model combining expressivity with streaming capabilities for natural cross-lingual communication.
Stable Video Diffusion is a latent diffusion model developed by Stability AI that generates short video clips from single still images. Built upon Stable Diffusion 2.1 with added temporal convolution and attention layers, the model comprises 1.52 billion parameters and supports up to 25 frames at customizable frame rates. Trained on curated video datasets, SVD demonstrates competitive performance in image-to-video synthesis and multi-view generation tasks.
Yi 1.5 6B is a bilingual Transformer-based language model developed by 01.AI, trained on 3 trillion words of multilingual data. The model supports both English and Chinese for tasks including language understanding, commonsense reasoning, and reading comprehension. Available in base and chat variants with quantized versions, it is distributed under Apache 2.0 license for research and commercial use.
Whisper is a transformer-based automatic speech recognition model developed by OpenAI that performs multilingual transcription, speech translation, and language identification. Trained on 680,000 hours of diverse audio data across 98 languages, it uses an encoder-decoder architecture with special control tokens to handle multiple tasks. The model demonstrates robust performance across accents and noisy environments, with variants ranging from lightweight to high-accuracy configurations.
MAGNeT is a non-autoregressive Transformer model developed by Meta AI for generating music and sound effects from text descriptions. The model uses EnCodec tokenization and parallel codebook generation to achieve faster inference than autoregressive approaches while maintaining competitive quality metrics. MAGNeT is available in multiple variants with 300M to 1.5B parameters for research applications.
Mistral 7B is a 7.3 billion parameter transformer language model developed by Mistral AI and released under Apache 2.0 license. The model incorporates Grouped-Query Attention and Sliding-Window Attention to improve inference efficiency and handle longer sequences up to 8,192 tokens. It demonstrates competitive performance against larger models on reasoning, mathematics, and code generation benchmarks while maintaining a compact architecture suitable for various natural language processing applications.
Stable Diffusion XL is a text-to-image diffusion model developed by Stability AI featuring a two-stage architecture with a 3.5 billion parameter base model and a 6.6 billion parameter refiner. The model utilizes dual text encoders and generates images at 1024x1024 resolution with improved prompt adherence and compositional control compared to previous Stable Diffusion versions, while supporting fine-tuning and multi-aspect ratio training.
Llama 2 13B is a 13-billion parameter auto-regressive transformer language model developed by Meta for text generation and dialogue tasks. The model features a 4096-token context length and was pretrained on 2 trillion tokens across multiple languages. Available in both base and chat-optimized versions, it incorporates reinforcement learning from human feedback for improved safety and helpfulness in conversational applications.
MPT-7B is a 6.7 billion parameter decoder-only transformer model developed by MosaicML, trained on 1 trillion tokens of English text and code. The model features FlashAttention and ALiBi for efficient attention computation and extended context handling, enabling variants like StoryWriter-65k+ to process up to 65,000 tokens. Released under Apache 2.0 license, it serves as a foundation for further fine-tuning across various applications.
LLaMA 7B is a 7-billion parameter transformer-based language model developed by Meta AI and released in February 2023. Built using architectural improvements including RMSNorm, SwiGLU activation, and rotary positional embeddings, the model was trained on approximately one trillion tokens from publicly available datasets. It demonstrates capabilities in text generation, reasoning, and code generation across various benchmarks, though with limitations including potential biases and factual inaccuracies.
LLaMA 33B is a 32.5 billion parameter transformer-based language model developed by Meta AI as part of the LLaMA family. The model employs architectural enhancements including RMSNorm pre-normalization, SwiGLU activation functions, and rotary positional embeddings. It was trained on over 1.4 trillion tokens from publicly available datasets and demonstrates competitive performance across various language modeling and reasoning benchmarks while being released under a noncommercial research license.
AudioLDM is a text-to-audio generative model that creates speech, sound effects, and music from textual descriptions using latent diffusion techniques. The model employs Contrastive Language-Audio Pretraining (CLAP) embeddings and a variational autoencoder operating on mel-spectrogram representations. Trained on diverse datasets including AudioSet and AudioCaps, AudioLDM supports audio-to-audio generation, style transfer, super-resolution, and inpainting capabilities for creative and technical applications.
Demucs is an audio source separation model that decomposes music tracks into constituent stems such as vocals, drums, and bass. The latest version (v4) features Hybrid Transformer Demucs architecture, combining dual U-Nets operating in time and frequency domains with cross-domain transformer attention mechanisms. Released under MIT license, it achieves competitive performance on MUSDB HQ benchmarks for music production and research applications.
Tortoise TTS is an open-source text-to-speech system that combines autoregressive and diffusion-based architectures to generate realistic speech from text. The model supports voice cloning through reference audio clips and can produce multi-voice synthesis with controllable prosody and emotion through prompt engineering techniques. Trained on approximately 50,000 hours of speech data using a combination of transformer and diffusion models, Tortoise employs a contrastive language-voice model for output ranking and includes a neural vocoder for final waveform synthesis.
Gemma 3n E2B is a multimodal generative AI model developed by Google DeepMind that supports text, image, audio, and video inputs. Built on the MatFormer architecture with 6 billion raw parameters but 2 billion effective parameters, it employs Per-Layer Embeddings and KV Cache Sharing for efficient operation on resource-constrained devices. The model was trained on over 11 trillion tokens across 140+ languages with a June 2024 knowledge cutoff.
Mistral Small 3.2 (2506) is a 24-billion parameter text generation model developed by Mistral AI as an incremental update to Mistral Small 3.1. The model features improved instruction following, reduced repetition, enhanced function calling reliability, and maintained multimodal capabilities including vision processing. It supports up to 128,000 tokens context length and demonstrates performance improvements on benchmarks like Wildbench v2 and Arena Hard v2.
HiDream E1 Full is an instruction-based image editing model developed by HiDream-ai that enables natural language-guided modifications of existing images. Built upon the HiDream-I1 foundation model, it utilizes a 17-billion parameter sparse Diffusion Transformer architecture with Mixture-of-Experts components. The model supports various editing tasks including style transfer, object manipulation, and content addition or removal while preserving unmodified image regions through spatially weighted loss functions.
Qwen3-1.7B is a dense transformer language model with 1.7 billion parameters developed by Alibaba Cloud's Qwen Team. The model features dual-mode reasoning capabilities, operating in either "thinking" mode for step-by-step reasoning with intermediate computations or "non-thinking" mode for rapid direct responses. It supports 119 languages and utilizes a 32,768-token context window with grouped query attention architecture.
Qwen3-8B is a dense transformer-based language model developed by Alibaba Cloud featuring 8.2 billion parameters across 36 layers with Grouped Query Attention and 32,768-token native context length. The model supports hybrid thinking capabilities, enabling dynamic switching between systematic reasoning and rapid response modes, and was trained on 36 trillion tokens across 119 languages using multi-stage optimization including distillation from larger Qwen3 variants.
Qwen3-32B is a 32.8 billion parameter dense language model developed by Alibaba Cloud, featuring hybrid "thinking" modes that enable step-by-step reasoning for complex tasks or rapid responses for routine queries. The model supports 119 languages, extends to 32K token context length, and was trained on 36 trillion tokens using a four-stage post-training pipeline incorporating reinforcement learning and reasoning enhancement techniques.
Qwen3-235B-A22B is a Mixture-of-Experts language model developed by Alibaba Cloud's Qwen team, featuring 235 billion total parameters with 22 billion activated per inference step. The model offers dual operational modes—"thinking" for complex reasoning and "non-thinking" for rapid responses—enabling users to balance computational depth with inference speed. Trained on 36 trillion tokens across 119 languages, it supports advanced agentic workflows and demonstrates competitive performance on mathematical, coding, and multilingual benchmarks.
DeepSeek V3 (0324) is a Mixture-of-Experts language model with 671 billion total parameters and 37 billion activated per token, developed by DeepSeek AI. The model incorporates Multi-head Latent Attention, FP8 mixed-precision training, and Multi-Token Prediction techniques. It demonstrates strong performance in reasoning, code generation, and multilingual tasks, particularly Chinese, with support for 128K token contexts and availability under permissive open-source licensing.
Gemma 3 1B is a lightweight, multimodal generative AI model developed by Google DeepMind that processes both text and images to generate text outputs. Built on a decoder-only transformer architecture with local and global attention layers, the model supports a 32,000-token context window and was trained on 2 trillion tokens across 140+ languages. The model offers open-source pre-trained and instruction-tuned weights for research and practical applications.
Gemma 3 12B is a multimodal, instruction-tuned language model developed by Google DeepMind that processes both text and images to generate text outputs. The model features a decoder-only transformer architecture with a 400-million-parameter vision encoder and supports context windows up to 128,000 tokens. Trained on 12 trillion tokens across over 140 languages using knowledge distillation and reinforcement learning techniques, it demonstrates capabilities in mathematics, coding, and vision-language tasks while offering quantized variants for resource-efficient deployment.
Command A is a decoder-only transformer language model developed by Cohere for enterprise applications, featuring a 256,000-token context window and optimized for multilingual understanding, retrieval-augmented generation, code synthesis, and agentic workflows. The model employs grouped-query attention and architectural innovations for enhanced throughput, achieving competitive performance across academic benchmarks while demonstrating efficiency advantages in inference speed and memory usage compared to similar models.
Wan 2.1 T2V 1.3B is an open-source text-to-video generation model developed by Wan-AI, featuring 1.3 billion parameters and utilizing a Flow Matching framework with diffusion transformers. The model supports multilingual text-to-video synthesis in English and Chinese, operates efficiently on consumer GPUs requiring 8.19 GB VRAM, and generates 480P videos with capabilities for image-to-video conversion and text rendering within videos.
Wan 2.1 I2V 14B 720P is a 14-billion parameter image-to-video generation model developed by Wan-AI that converts single images into 720P videos. Built on a unified transformer-based diffusion architecture with a novel 3D causal VAE (Wan-VAE) for spatiotemporal compression, the model supports multilingual text prompts and demonstrates competitive performance in video generation benchmarks while maintaining computational efficiency across various GPU configurations.
Qwen2.5-VL-3B-Instruct is a multimodal large language model developed by Alibaba Cloud featuring 3 billion parameters. The model combines a Vision Transformer encoder with a Qwen2.5-series decoder to process images, videos, and text through dynamic resolution handling and temporal processing capabilities. It supports object detection, OCR, document analysis, video understanding, and computer interface automation, trained on approximately 1.4 trillion tokens across multiple modalities and released under Apache-2.0 license.
Qwen2.5-VL 72B is a 72-billion parameter multimodal generative AI model developed by Alibaba Cloud that integrates vision and language understanding. The model features dynamic resolution processing, temporal video alignment, and architectural enhancements over previous Qwen2-VL versions. It performs object detection, document parsing, video comprehension, OCR across multiple languages, and functions as a visual agent for interactive tasks, trained on over 1.4 trillion tokens.
DeepSeek R1 is a large language model developed by DeepSeek AI that employs a Mixture-of-Experts architecture with 671 billion total parameters and 37 billion activated during inference. The model utilizes reinforcement learning and supervised fine-tuning to enhance reasoning capabilities across mathematics, coding, and logic tasks, achieving competitive performance on benchmarks including 90.8 on MMLU and 97.3 on MATH-500.
DeepSeek V3 is a Mixture-of-Experts language model with 671 billion total parameters and 37 billion activated per token, developed by DeepSeek-AI. The model features Multi-head Latent Attention, auxiliary-loss-free load balancing, and FP8 mixed-precision training. Trained on 14.8 trillion tokens with a 128,000-token context window, it demonstrates competitive performance across reasoning, coding, and mathematical benchmarks while supporting multilingual capabilities and long-context processing.
DeepSeek VL2 Small is a 2.8 billion parameter multimodal vision-language model that uses a Mixture-of-Experts architecture with dynamic tiling for processing high-resolution images. Built on the DeepSeekMoE-16B framework with SigLIP vision encoding, it handles tasks including visual question answering, OCR, document analysis, and visual grounding across multiple languages, achieving competitive performance on benchmarks like DocVQA while maintaining computational efficiency through sparse expert routing.
Phi-4 is a 14-billion parameter decoder-only Transformer language model developed by Microsoft Research that focuses on mathematical reasoning and code generation through curated synthetic data training. The model supports a 16,000-token context window and achieves competitive performance on benchmarks like MMLU (84.8) and HumanEval (82.6) despite its relatively compact size, utilizing supervised fine-tuning and direct preference optimization for alignment.
HunyuanVideo is an open-source video generation model developed by Tencent that supports text-to-video, image-to-video, and controllable video synthesis. The model employs a Transformer-based architecture with a 3D Variational Autoencoder and utilizes flow matching for generating videos at variable resolutions and durations. It features 13 billion parameters and includes capabilities for avatar animation, audio synchronization, and multi-aspect ratio output generation.
CogVideoX 1.5 5B I2V is an image-to-video generation model developed by THUDM using a diffusion transformer architecture with 3D causal variational autoencoder. The model generates temporally coherent videos from input images and text prompts, supporting resolutions up to 1360 pixels and video lengths of 5-10 seconds at 16 fps, trained on 35 million curated video clips.
Qwen2.5-Coder-32B is a 32.5-billion parameter transformer-based language model developed by Alibaba Cloud, specifically designed for programming and code intelligence tasks. The model supports over 92 programming languages and features capabilities in code generation, completion, repair, and reasoning with a 128,000-token context window. Trained on approximately 5.5 trillion tokens of code and instructional data, it demonstrates performance across various coding benchmarks including HumanEval, MBPP, and multilingual programming evaluations.
Llama 3.2 3B is a multilingual instruction-tuned language model developed by Meta with 3 billion parameters and a 128,000-token context window. The model utilizes knowledge distillation from larger Llama variants, Grouped-Query Attention for efficient inference, and advanced quantization techniques optimized for PyTorch's ExecuTorch framework. Supporting eight languages, it targets assistant and agentic applications while enabling deployment in resource-constrained environments.
Qwen 2.5 Math 1.5B is a specialized language model developed by Alibaba Cloud for mathematical reasoning in English and Chinese. Built on the Qwen2.5 architecture with 4,096 token context length, it was trained on the Qwen Math Corpus v2 containing over one trillion tokens. The model supports chain-of-thought reasoning and tool-integrated reasoning with Python code execution for solving complex mathematical problems.
Qwen 2.5 Math 72B is a specialized large language model developed by Alibaba Cloud with 72.7 billion parameters, designed for solving advanced mathematical problems in English and Chinese. The model incorporates chain-of-thought reasoning and tool-integrated reasoning capabilities, enabling step-by-step problem solving and code execution for complex mathematical tasks, and demonstrates performance improvements over previous versions on standardized mathematical benchmarks.
Qwen 2.5 7B is a transformer-based language model developed by Alibaba Cloud with 7.61 billion parameters, trained on up to 18 trillion tokens from multilingual datasets. The model features grouped query attention, 128,000 token context length, and supports over 29 languages. As a base model requiring further fine-tuning, it provides capabilities for text generation, structured data processing, and multilingual applications under Apache 2.0 licensing.
Qwen2.5-32B is a 32.5 billion parameter decoder-only transformer language model developed by Alibaba Cloud's Qwen Team, featuring 64 layers with grouped query attention and supporting a 128,000 token context window. Trained on 18 trillion tokens across 29+ languages, the model demonstrates strong performance in coding, mathematics, and multilingual tasks. Released under Apache 2.0 license in September 2024, it serves as a base model intended for further post-training development rather than direct deployment.
Mistral Small (2409) is an instruction-tuned language model developed by Mistral AI with approximately 22 billion parameters and released in September 2024. The model supports function calling capabilities and processes input sequences up to 32,000 tokens. It features improvements in reasoning, alignment, and code generation compared to its predecessor, while being restricted to research and non-commercial use under Mistral AI's Research License.
CogVideoX-5B is a diffusion transformer model developed by THUDM for text-to-video and image-to-video synthesis, generating 10-second videos at 768x1360 resolution and 8 frames per second. The model employs a 3D causal VAE, 3D rotary position embeddings, and hybrid attention mechanisms to maintain temporal consistency across video sequences, trained on 35 million video clips and 2 billion images with comprehensive filtering and captioning processes.
Phi-3.5 Vision Instruct is a 4.2-billion-parameter multimodal model developed by Microsoft that processes both text and images within a 128,000-token context window. The model excels at multi-frame image analysis, visual question answering, document understanding, and video summarization tasks. Built on the Phi-3 Mini architecture with an integrated image encoder, it demonstrates strong performance on vision-language benchmarks while maintaining computational efficiency for deployment in resource-constrained environments.
CogVideoX-2B is an open-source text-to-video diffusion model developed by THUDM that generates videos up to 720×480 resolution and six seconds in length. The model employs a 3D causal variational autoencoder and Expert Transformer architecture with 3D rotary position embeddings for temporal coherence. Trained on 35 million video clips and 2 billion images using progressive training techniques, it supports INT8 quantization and is released under Apache 2.0 license.
FLUX.1 [dev] is a 12-billion-parameter text-to-image generation model developed by Black Forest Labs, utilizing a hybrid architecture with parallel diffusion transformer blocks and flow matching training. The model employs guidance distillation from FLUX.1 [pro] and supports variable aspect ratios with outputs ranging from 0.1 to 2.0 megapixels, released under a non-commercial license for research and personal use.
Stable Video 4D (SV4D) is a generative video-to-video diffusion model that produces consistent multi-view video sequences of dynamic objects from a single input video. The model synthesizes temporally and spatially coherent outputs from arbitrary viewpoints using a latent video diffusion architecture with spatial, view, and frame attention mechanisms, enabling efficient 4D asset generation for applications in design, game development, and research.
Stable Audio Open 1.0 is an open-weight text-to-audio synthesis model developed by Stability AI with approximately 1.21 billion parameters. Built on latent diffusion architecture with transformer components and T5-based text conditioning, the model generates up to 47 seconds of stereo audio at 44.1 kHz. Trained exclusively on Creative Commons-licensed data totaling 7,300 hours, it demonstrates strong performance for sound effects and field recordings while showing modest capabilities for instrumental music generation.
DeepSeek Coder V2 is an open-source Mixture-of-Experts code language model developed by DeepSeek AI, featuring 236 billion total parameters with 21 billion active parameters. The model supports 338 programming languages and extends up to 128,000 token context length. Trained on 10.2 trillion tokens of code, mathematics, and natural language data, it demonstrates competitive performance on code generation benchmarks like HumanEval and mathematical reasoning tasks.
Llama 3.1 8B is a multilingual large language model developed by Meta using a decoder-only transformer architecture with Grouped-Query Attention and a 128,000-token context window. The model is pretrained on 15 trillion tokens and undergoes supervised fine-tuning and reinforcement learning from human feedback. It supports eight languages and demonstrates competitive performance across benchmarks in reasoning, coding, mathematics, and multilingual tasks, distributed under the Llama 3.1 Community License.
Gemma 2 27B is a decoder-only transformer language model developed by Google, trained on 13 trillion tokens using JAX and ML Pathways on TPU hardware. The model achieves 75.2% accuracy on MMLU benchmarks and 51.8% on HumanEval programming tasks. It supports various text generation applications including content creation, dialogue systems, and code assistance, with openly accessible weights distributed under Google's responsible use policies.
Qwen2-7B is a 7.6 billion parameter decoder-only Transformer language model developed by Alibaba Cloud as part of the Qwen2 series. The model features Group Query Attention, SwiGLU activations, and supports a 32,000-token context length with extrapolation capabilities up to 128,000 tokens. Trained on a multilingual dataset covering 29 languages, it demonstrates competitive performance in coding, mathematics, and multilingual tasks compared to similarly-sized models like Mistral-7B and Llama-3-8B.
Codestral 22B v0.1 is an open-weight code generation model developed by Mistral AI with 22.2 billion parameters and support for over 80 programming languages. The model features a 32k token context window and operates in both "Instruct" and "Fill-in-the-Middle" modes, enabling natural language code queries and token prediction between code segments for IDE integration and repository-level tasks.
DeepSeek V2.5 is a 236 billion parameter Mixture-of-Experts language model that activates 21 billion parameters per token during inference. The architecture incorporates Multi-head Latent Attention for reduced memory usage and supports both English and Chinese with an extended context window of 128,000 tokens. Training utilized 8.1 trillion tokens with subsequent supervised fine-tuning and reinforcement learning alignment phases.
CodeGemma 1.1 7B is an open-weights language model developed by Google that specializes in code generation, completion, and understanding across multiple programming languages. Built on the Gemma architecture, it employs Fill-in-the-Middle training objectives and was trained on over 500 billion tokens comprising approximately 80% code and 20% natural language data, enabling both programming tasks and mathematical reasoning capabilities.
Llama 3 70B is a 70-billion-parameter decoder-only transformer language model developed by Meta and released in April 2024. The model employs grouped query attention, an 8,192-token context length, and a 128,000-token vocabulary, trained on over 15 trillion tokens from publicly available data. It demonstrates strong performance on benchmarks including MMLU, HumanEval, and GSM-8K, with specialized instruction tuning for dialogue and assistant applications.
Mixtral 8x22B is a Sparse Mixture of Experts language model developed by Mistral AI with 141 billion total parameters and 39 billion active parameters per token. The model supports multilingual text generation across English, French, German, Spanish, and Italian, with a 64,000-token context window. It demonstrates capabilities in reasoning, mathematics, and coding tasks, released under Apache 2.0 license.
Llama 4 Maverick (17Bx128E) is a multimodal large language model developed by Meta featuring a Mixture-of-Experts architecture with 17 billion active parameters from 400 billion total, distributed across 128 experts. The model integrates text and visual information through early fusion and was trained on approximately 22 trillion tokens across 200+ languages, demonstrating strong performance on multimodal reasoning, coding, and multilingual tasks while supporting context lengths up to 1 million tokens.
Stable Video 3D is a generative model developed by Stability AI that creates orbital videos from single static images, generating 21-frame sequences at 576x576 resolution that simulate a camera rotating around objects. Built on Stable Video Diffusion architecture and trained on Objaverse 3D renderings, it offers two variants: SV3D_u for autonomous camera paths and SV3D_p for user-specified trajectories.
Gemma 7B is a 7-billion-parameter open-source transformer-based language model developed by Google and released in February 2024. Trained on approximately 6 trillion tokens of primarily English text, code, and mathematical content, the model utilizes a decoder-only architecture and demonstrates competitive performance across natural language understanding, reasoning, and code generation benchmarks, achieving scores such as 64.3 on MMLU and 81.2 on HellaSwag evaluations.
Stable Cascade Stage A is a vector quantized generative adversarial network encoder that compresses 1024×1024 pixel images into 256×256 discrete tokens using a learned codebook. With 20 million parameters and fixed weights, this component serves as the decoder in Stable Cascade's three-stage hierarchical pipeline, reconstructing high-resolution images from compressed latent representations generated by the upstream stages.
Stable Cascade Stage C is a text-conditional latent diffusion model that operates as the third stage in Stable Cascade's hierarchical image generation architecture. It translates text prompts into compressed representations within a 24x24 spatial latent space for 1024x1024 images, utilizing CLIP-H embeddings for text conditioning. The stage supports fine-tuning adaptations including LoRA and ControlNet integration for various creative workflows.
Mistral Small 3 (2501) is a 24-billion-parameter instruction-fine-tuned language model developed by Mistral AI and released under an Apache 2.0 license. The model features a 32,000-token context window, multilingual capabilities across eleven languages, and demonstrates competitive performance on benchmarks including MMLU Pro, HumanEval, and instruction-following tasks while maintaining efficient inference speeds.
Qwen1.5-32B is a 32-billion parameter generative language model developed by Alibaba Cloud's Qwen Team and released in February 2024. The model supports up to 32,768 tokens of context length and demonstrates multilingual capabilities across European, East Asian, and Southeast Asian languages. It achieves competitive performance on language understanding and reasoning benchmarks, with an MMLU score of 73.4, and includes features for retrieval-augmented generation and external system integration.
The SD 1.5 Motion Model is a core component of the AnimateDiff framework that enables animation generation from Stable Diffusion 1.5-based text-to-image models. This motion module uses a temporal transformer architecture to add motion dynamics to existing image generation models without requiring retraining of the base model. Trained on the WebVid-10M dataset, it supports plug-and-play compatibility with personalized T2I models and enables controllable video synthesis through text prompts or sparse input controls.
SOLAR 10.7B is a large language model developed by Upstage AI using 10.7 billion parameters and a transformer architecture based on Llama 2. The model employs Depth Up-Scaling (DUS), which increases network depth by duplicating and concatenating layers from Mistral 7B initialization, resulting in a 48-layer architecture. Released in both pretrained and instruction-tuned variants under open-source licensing, it demonstrates competitive performance on standard benchmarks through multi-stage training including continued pretraining, instruction fine-tuning, and alignment optimization.
Seamless is a family of multilingual translation models developed by Meta that performs speech-to-speech, speech-to-text, text-to-speech, and text-to-text translation across 100 languages. The system comprises four integrated models: SeamlessM4T v2 (2.3 billion parameters), SeamlessExpressive for preserving vocal style and prosody, SeamlessStreaming for real-time low-latency translation, and a unified model combining expressivity with streaming capabilities for natural cross-lingual communication.
Stable Video Diffusion is a latent diffusion model developed by Stability AI that generates short video clips from single still images. Built upon Stable Diffusion 2.1 with added temporal convolution and attention layers, the model comprises 1.52 billion parameters and supports up to 25 frames at customizable frame rates. Trained on curated video datasets, SVD demonstrates competitive performance in image-to-video synthesis and multi-view generation tasks.
Yi 1.5 6B is a bilingual Transformer-based language model developed by 01.AI, trained on 3 trillion words of multilingual data. The model supports both English and Chinese for tasks including language understanding, commonsense reasoning, and reading comprehension. Available in base and chat variants with quantized versions, it is distributed under Apache 2.0 license for research and commercial use.
Whisper is a transformer-based automatic speech recognition model developed by OpenAI that performs multilingual transcription, speech translation, and language identification. Trained on 680,000 hours of diverse audio data across 98 languages, it uses an encoder-decoder architecture with special control tokens to handle multiple tasks. The model demonstrates robust performance across accents and noisy environments, with variants ranging from lightweight to high-accuracy configurations.
MAGNeT is a non-autoregressive Transformer model developed by Meta AI for generating music and sound effects from text descriptions. The model uses EnCodec tokenization and parallel codebook generation to achieve faster inference than autoregressive approaches while maintaining competitive quality metrics. MAGNeT is available in multiple variants with 300M to 1.5B parameters for research applications.
Mistral 7B is a 7.3 billion parameter transformer language model developed by Mistral AI and released under Apache 2.0 license. The model incorporates Grouped-Query Attention and Sliding-Window Attention to improve inference efficiency and handle longer sequences up to 8,192 tokens. It demonstrates competitive performance against larger models on reasoning, mathematics, and code generation benchmarks while maintaining a compact architecture suitable for various natural language processing applications.
Stable Diffusion XL is a text-to-image diffusion model developed by Stability AI featuring a two-stage architecture with a 3.5 billion parameter base model and a 6.6 billion parameter refiner. The model utilizes dual text encoders and generates images at 1024x1024 resolution with improved prompt adherence and compositional control compared to previous Stable Diffusion versions, while supporting fine-tuning and multi-aspect ratio training.
Llama 2 13B is a 13-billion parameter auto-regressive transformer language model developed by Meta for text generation and dialogue tasks. The model features a 4096-token context length and was pretrained on 2 trillion tokens across multiple languages. Available in both base and chat-optimized versions, it incorporates reinforcement learning from human feedback for improved safety and helpfulness in conversational applications.
MPT-7B is a 6.7 billion parameter decoder-only transformer model developed by MosaicML, trained on 1 trillion tokens of English text and code. The model features FlashAttention and ALiBi for efficient attention computation and extended context handling, enabling variants like StoryWriter-65k+ to process up to 65,000 tokens. Released under Apache 2.0 license, it serves as a foundation for further fine-tuning across various applications.
LLaMA 7B is a 7-billion parameter transformer-based language model developed by Meta AI and released in February 2023. Built using architectural improvements including RMSNorm, SwiGLU activation, and rotary positional embeddings, the model was trained on approximately one trillion tokens from publicly available datasets. It demonstrates capabilities in text generation, reasoning, and code generation across various benchmarks, though with limitations including potential biases and factual inaccuracies.
LLaMA 33B is a 32.5 billion parameter transformer-based language model developed by Meta AI as part of the LLaMA family. The model employs architectural enhancements including RMSNorm pre-normalization, SwiGLU activation functions, and rotary positional embeddings. It was trained on over 1.4 trillion tokens from publicly available datasets and demonstrates competitive performance across various language modeling and reasoning benchmarks while being released under a noncommercial research license.
AudioLDM is a text-to-audio generative model that creates speech, sound effects, and music from textual descriptions using latent diffusion techniques. The model employs Contrastive Language-Audio Pretraining (CLAP) embeddings and a variational autoencoder operating on mel-spectrogram representations. Trained on diverse datasets including AudioSet and AudioCaps, AudioLDM supports audio-to-audio generation, style transfer, super-resolution, and inpainting capabilities for creative and technical applications.
Demucs is an audio source separation model that decomposes music tracks into constituent stems such as vocals, drums, and bass. The latest version (v4) features Hybrid Transformer Demucs architecture, combining dual U-Nets operating in time and frequency domains with cross-domain transformer attention mechanisms. Released under MIT license, it achieves competitive performance on MUSDB HQ benchmarks for music production and research applications.
Tortoise TTS is an open-source text-to-speech system that combines autoregressive and diffusion-based architectures to generate realistic speech from text. The model supports voice cloning through reference audio clips and can produce multi-voice synthesis with controllable prosody and emotion through prompt engineering techniques. Trained on approximately 50,000 hours of speech data using a combination of transformer and diffusion models, Tortoise employs a contrastive language-voice model for output ranking and includes a neural vocoder for final waveform synthesis.

Powerful Tools
For Researchers and Engineers
Laboratory OS is pre-configured for the latest Nvidia hardware and AI frameworks. Stop spending your time on GPU drivers, CUDA libraries, and Python environments.



Secure, Private, Powerful
Your Server, Under Your Control
Dedicated Linux VMs with Nvidia GPUs.
Your data never leaves your private server.
Powerful GPU Servers
ready to deploy
One-click deploy Laboratory OS onto high-performance datacenter servers with the latest Nvidia GPUs and enterprise-grade security.
On-Demand
Pay for what you use, prorated to the second - no mandatory commitments or subscriptions.
Fast Networking
Ultra-fast datacenter fiber optic network speeds - download large models onto the Laboratory in seconds.
Enterprise GPU Servers
Utilize the latest cutting-edge Nvidia hardware, run your workloads on the most powerful AI accelerators.
Competitive Pricing
Savings of 40%+ compared to deploying the same GPUs on public clouds such as AWS, GCP, and Azure.
Nvidia
A5000
Laboratory OS Server
Nvidia
A40
Laboratory OS Server
Nvidia
L40S
Laboratory OS Server
Nvidia
A100
Laboratory OS Server
Nvidia
H100
Laboratory OS Server
Persistent Laboratories
Save Time, Reduce Costs
Laboratories can be paused whenever you need to step away. The full system state is saved so that you can pick up where you left off.
Unlimitted Pause/Resume
Setup once, use whenever - the convenience of a local workstation with the power and flexibility of the cloud.
Persistent System State
Not just a mounted volume, the full boot disk is saved.
Equivalent to turning off a local workstation computer.
Fast NVMe Storage
Physically connected storage with low I/O latency.
Efficiently manage massive datasets and model weights.
Cost Savings
Reduce costs by pausing your server when not in use.
You do not pay for the GPU when the system is paused.
Storage Cost
Persistent Laboratories
Save Time, Reduce Costs
Laboratories can be paused whenever you need to step away - the full system state is saved, including the boot disk, so that you can pick up where you left off.