Launch a dedicated cloud GPU server running Laboratory OS to download and run QwQ 32B using any compatible app or framework.
Direct Download
Must be used with a compatible app, notebook, or codebase. May run slowly, or not work at all, depending on local system resources, particularly GPU(s) and available VRAM.
Open WebUI is an open-source, self-hosted web interface with a polished, ChatGPT-like user experience for interacting with LLMs. Integrates seamlessly with local Ollama installation.
The most full-featured web interface for experimenting with open source Large Language Models. Featuring a wide range of configurable settings, inference engines, and plugins.
Model Report
Alibaba Cloud / QwQ 32B
QwQ 32B is a 32.5-billion parameter causal language model developed by Alibaba Cloud as part of the Qwen series. The model employs a transformer architecture with 64 layers and Grouped Query Attention, trained using supervised fine-tuning and reinforcement learning focused on mathematical reasoning and coding proficiency. Released under Apache 2.0 license, it demonstrates competitive performance on reasoning benchmarks despite its relatively compact size.
Explore the Future of AI
Your server, your data, under your control
QwQ-32B is a 32.5-billion parameter causal language model developed as part of the Qwen series. It is designed to support advanced reasoning and complex problem-solving capabilities. Built by the Qwen team, QwQ-32B draws on recent advancements in transformer architectures and reinforcement learning to enhance both mathematical reasoning and coding proficiency. The model was introduced in March 2025, as detailed in the QwenLM blog, and is freely available under the Apache 2.0 license.
A video introduction to QwQ-32B, outlining its core capabilities and areas of application. [Source]
Technical Architecture
At its core, QwQ-32B employs a transformer-based architecture, with a foundation in the design principles established by Qwen2.5. The architecture features 64 layers and a Grouped Query Attention (GQA) mechanism, allocating 40 attention heads for query vectors and 8 for key and value vectors per group. With a total of 32.5 billion parameters—31.0 billion of which are non-embedding—the model leverages several innovative components, including Rotary Position Embeddings (RoPE), the SwiGLU activation function, Root Mean Square Layer Normalization (RMSNorm), and Attention QKV bias.
This technical foundation supports efficient scaling to long contexts and contributes to its reasoning capabilities. Specifically, context length can be expanded beyond 8,192 tokens with the YaRN (Yet another RoPE extension) technique, configurable via model settings to adapt to tasks requiring long input sequences.
Training Methodology
QwQ-32B's training regimen combines supervised fine-tuning with outcome-driven reinforcement learning (RL), using extensive pretraining data for language understanding and world knowledge. During the initial RL stage, the model receives scaled feedback focused on math and code generation tasks: a mathematical verifier awards accuracy-based rewards for problem-solving, while a code execution server evaluates generated code by actual runtime results. This contrasts with conventional reward models and contributes to directly optimizing for high-precision outputs in specialized domains.
In a subsequent stage, the RL process broadens to general capabilities. Here, rewards are drawn from a mix of general-purpose reward models and rule-based verifiers, improving instruction-following, alignment with human preferences, and agentic behaviors. This two-stage RL strategy enhances both domain-specific competencies and general reasoning, enabling the model to remain competitive even compared to models with significantly larger parameter counts.
Performance and Benchmarks
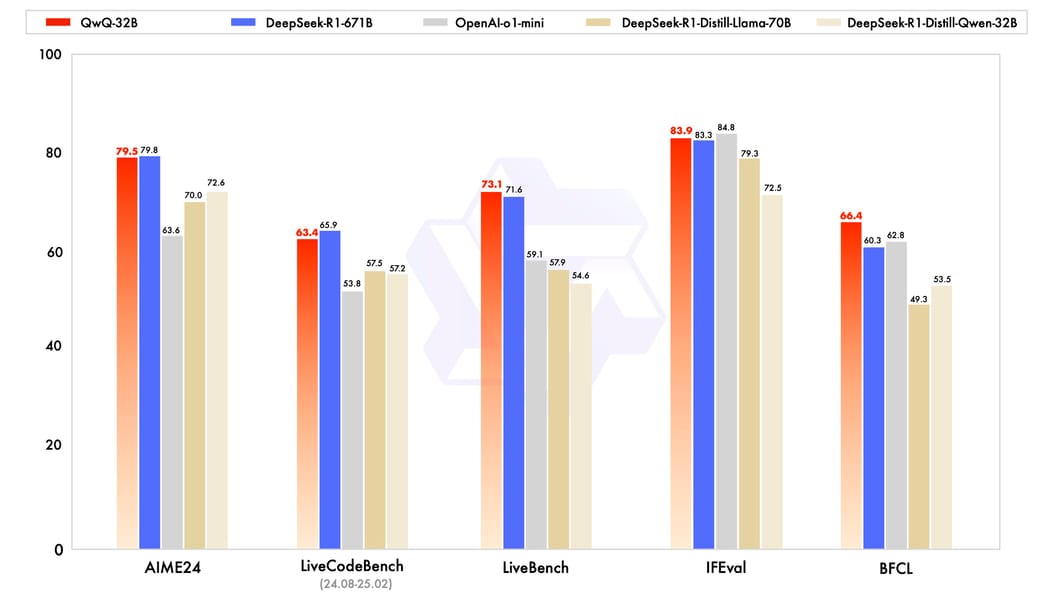
QwQ-32B performs competitively across a suite of standard benchmarks relevant to reasoning, coding, and mathematics. Its performance is frequently measured against models such as DeepSeek-R1 and OpenAI o1-mini. The model's relative standing is exemplified in metrics reported for AIME24, LiveCodeBench, LiveBench, IFEval, and BFCL, as detailed in the model's introduction materials.
Performance comparison of QwQ-32B (red) with DeepSeek-R1-671B, OpenAI-o1-mini, DeepSeek-R1-Distill-Llama-70B, and DeepSeek-R1-Distill-Qwen-32B across five benchmarks. Values above each bar indicate absolute scores. Benchmark data for QwQ-32B is shown, as reported in the Qwen model card.
Notably, QwQ-32B achieves scores of 79.5 in AIME24, 63.4 in LiveCodeBench, 73.1 in LiveBench, 83.9 in IFEval, and 66.4 in BFCL, illustrating efficient reasoning despite a smaller parameter footprint compared to some competitors. Performance evaluations on tasks such as mathematical problem-solving, coding accuracy, and general logic validate its design focus on complex reasoning.
Capabilities, Usage, and Applications
QwQ-32B is primarily designed for tasks demanding logical thought, multi-step reasoning, and adaptability. It can solve intricate mathematical problems (with prompts such as: "Please reason step by step, and put your final answer within \boxed{}."), accurately generate code, and follow nuanced instructions requiring alignment with human intentions. The model supports agentic use cases, where it "thinks critically"—evaluating its outputs, interacting with tools, and adjusting responses based on environmental feedback.
For deployment, it is recommended to use Hugging Face transformers version 4.37.0 or newer to ensure compatibility and facilitate intended performance. Users can customize prompt formatting and decoding settings to tune output for specific requirements, with options such as temperature, top-p, and top-k widely recognized for balancing diversity and repetition in generated sequences. When working with long sequences, YaRN can be enabled by adjusting the model configuration to improve context handling.
QwQ-32B is well suited for applications in mathematics, competitive programming, code generation, and more general natural language reasoning tasks. Its post-training processes and explicit integration of agent-like behaviors provide flexibility for research into long-horizon reasoning and interactive AI systems.
Model Family, License, and Limitations
QwQ-32B belongs to the broader Qwen model family, which comprises a variety of transformer architectures with differing focuses and scales. While QwQ-32B is considered a medium-sized model within this series, it demonstrates performance comparable to significantly larger models, such as DeepSeek-R1 with 671 billion parameters (37 billion activated), as well as several distilled variants, as described in recent technical reports.
The model is distributed as open-weight software under the terms of the Apache 2.0 license, supporting both academic research and further development.
Documented limitations include compatibility requirements on specific software libraries (notably, transformers version 4.37.0 or newer is required to avoid loading issues) and the use of vLLM for deployment, which currently only supports static YaRN scaling for long contexts—potentially impacting performance when input length varies significantly.