Launch a dedicated cloud GPU server running Laboratory OS to download and run Qwen 2.5 32B using any compatible app or framework.
Direct Download
Must be used with a compatible app, notebook, or codebase. May run slowly, or not work at all, depending on local system resources, particularly GPU(s) and available VRAM.
Open WebUI is an open-source, self-hosted web interface with a polished, ChatGPT-like user experience for interacting with LLMs. Integrates seamlessly with local Ollama installation.
The most full-featured web interface for experimenting with open source Large Language Models. Featuring a wide range of configurable settings, inference engines, and plugins.
Model Report
Alibaba Cloud / Qwen 2.5 32B
Qwen2.5-32B is a 32.5 billion parameter decoder-only transformer language model developed by Alibaba Cloud's Qwen Team, featuring 64 layers with grouped query attention and supporting a 128,000 token context window. Trained on 18 trillion tokens across 29+ languages, the model demonstrates strong performance in coding, mathematics, and multilingual tasks. Released under Apache 2.0 license in September 2024, it serves as a base model intended for further post-training development rather than direct deployment.
Explore the Future of AI
Your server, your data, under your control
Qwen2.5-32B is a large-scale, 32.5 billion parameter generative language model developed by the Qwen Team at Alibaba Group as part of the broader Qwen2.5 family. The model exemplifies advances in natural language processing, supporting broad multilingual capabilities, robust instruction following, and specialized performance in coding and mathematics. Qwen2.5-32B is positioned as a base model within its series and is primarily intended for continued development through post-training techniques. The Qwen2.5 series, released in September 2024, expanded upon earlier generations of Qwen models to support a variety of research and industrial use cases, maintaining an open-source ethos under the Apache 2.0 license for most variants.
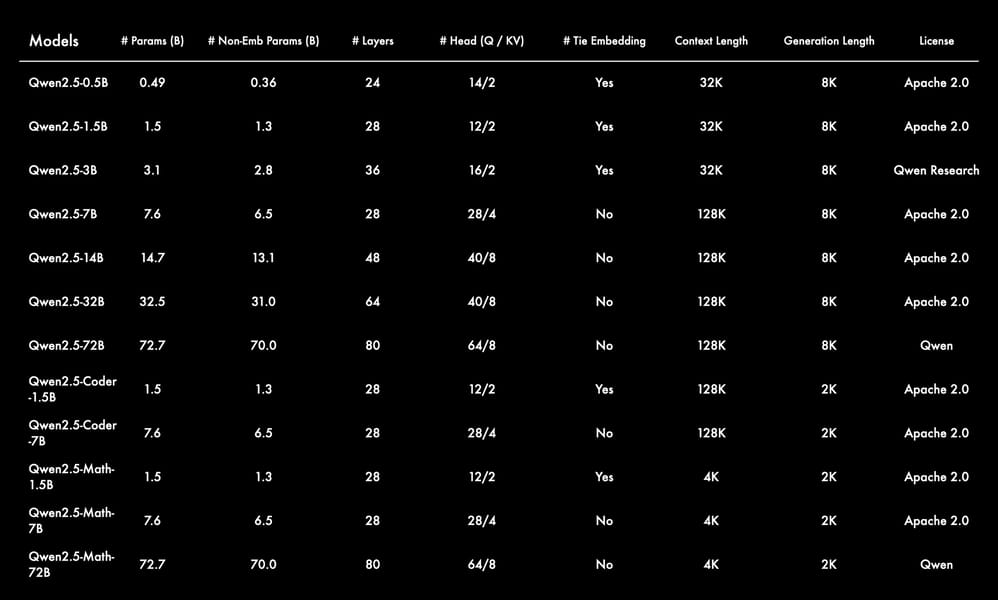
Qwen2.5 model family specifications, including general and specialized versions such as Qwen2.5-Coder and Qwen2.5-Math, as detailed in the official documentation.
An introductory video overview of the Qwen2.5 project, explaining its main features and capabilities. [Source]
Model Architecture and Technical Specifications
Qwen2.5-32B is built as a dense, decoder-only transformer, employing architectural innovations such as Rotary Position Embeddings (RoPE), SwiGLU (Swish Gated Linear Unit), and RMSNorm (Root Mean Square Normalization), along with a bias in the attention query-key-value computation. The model contains 64 layers, with 40 query heads and 8 key-value heads in a Grouped Query Attention setup, supporting efficient and scalable context processing. The total parameter count reaches 32.5 billion, with 31.0 billion non-embedding parameters.
The model supports a context window of up to 128,000 tokens, with internal specification supporting up to 131,072 tokens, and can produce outputs of up to 8,000 tokens per generation. This extensive context length significantly enhances the model’s capacity for document-level understanding and advanced reasoning tasks. Multilingual by design, Qwen2.5-32B recognizes and generates text in over 29 languages, including but not limited to Chinese, English, French, Spanish, Russian, Japanese, and Arabic, accompanied by strong instruction-following and translation abilities as outlined in the Qwen2.5 technical summary.
Further, the model introduces enhancements over previous Qwen2 series models, including improved knowledge coverage, better handling of structured data and long-form text, and improved resilience to diverse prompting scenarios. Its design accounts for downstream adaptation, enabling continued pretraining, supervised fine-tuning (SFT), reinforcement learning from human feedback (RLHF), and other post-training methodologies.
Training Regimen
The training of Qwen2.5-32B was conducted on a large-scale multilingual and multi-domain corpus comprising up to 18 trillion tokens, incorporating diverse sources to maximize knowledge acquisition and adaptability. The training process introduced refinements over prior series, emphasizing improvements in long context modeling, comprehension of structured outputs such as tables and JSON data, and stability across a variety of prompt types. These advances are documented in the Qwen2.5 blog.
Following pretraining, post-training algorithms were systematically integrated to further enhance performance in instruction adherence, complex task reasoning, and cross-lingual transfer. Although a comprehensive technical report is pending release as of September 2024, summary methodologies and preliminary findings are provided through project communications and the public model card.
Performance and Benchmarking
Qwen2.5-32B demonstrates competitive performance across a spectrum of established natural language understanding and generation benchmarks. Evaluations summarized in the official documentation indicate particularly strong results in multi-task learning (MMLU), coding (HumanEval), and mathematics (MATH) assessments, outpacing comparable or larger models such as Phi-3.5-MoE-Instruct and Gemma2-27B-IT on several key indicators.
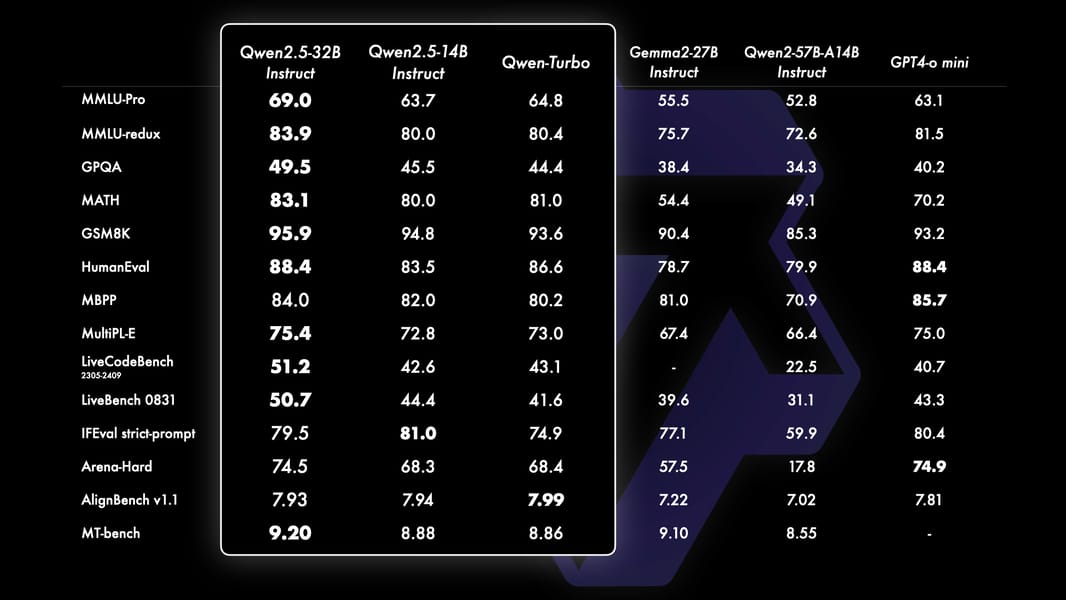
Performance comparison of Qwen2.5-32B and Qwen2.5-14B against baseline models on benchmarks including MMLU, GPQA, HumanEval, and MATH, highlighting strengths in knowledge, code generation, and mathematical reasoning.
Published figures show that Qwen2.5-32B achieves MMLU scores surpassing 85, HumanEval coding assessments above 85, and mathematics test results exceeding 80, representing significant improvements over the previous Qwen2 generation, as detailed in the Qwen2.5 evaluation report.
Use Cases and Applications
Qwen2.5-32B is designed primarily for scientific research, custom model development, and integration as a large language foundation for a variety of downstream tasks. The model's capabilities extend across natural language understanding, code synthesis, mathematical reasoning, and handling of structurally rich outputs. Qwen models are utilized in natural language processing, multilingual translation, agent-based reasoning, tool integration, and as building blocks for domain-specific assistant systems.
The Qwen2.5-32B base model is intended for further post-training activities—such as SFT, RLHF, or continued pretraining—rather than as a direct conversational endpoint. Matched with robust tool use scaffolding, the model can be integrated into complex agent frameworks. Official resources and implementation guides are available via the Qwen documentation portal.
Release and Licensing
The Qwen2.5-32B model, released in September 2024, contributes to a lineage of models whose development includes the earlier Qwen1.5 and Qwen2 series. Most models within the Qwen2.5 family, including Qwen2.5-32B, are licensed under the permissive Apache 2.0 license, with licensing details and exceptions, such as for some 3B and 72B parameter variants, made explicit in respective repositories. This licensing approach supports open research and community-driven advancements while upholding transparent governance around use and distribution.
Limitations
Qwen2.5-32B, as a base language model, is not recommended for direct conversational deployment without further post-training. The technical report offering comprehensive methodological detail remained unreleased as of September 2024, with the best available insights provided through current blog updates and preliminary documentation. As a research-oriented model, its optimal performance and safety in open-ended conversational systems requires additional, task-specific fine-tuning and evaluation.