Launch a dedicated cloud GPU server running Laboratory OS to download and run Llama 2 13B using any compatible app or framework.
Direct Download
Must be used with a compatible app, notebook, or codebase. May run slowly, or not work at all, depending on local system resources, particularly GPU(s) and available VRAM.
Open WebUI is an open-source, self-hosted web interface with a polished, ChatGPT-like user experience for interacting with LLMs. Integrates seamlessly with local Ollama installation.
The most full-featured web interface for experimenting with open source Large Language Models. Featuring a wide range of configurable settings, inference engines, and plugins.
Model Report
Meta / Llama 2 13B
Llama 2 13B is a 13-billion parameter auto-regressive transformer language model developed by Meta for text generation and dialogue tasks. The model features a 4096-token context length and was pretrained on 2 trillion tokens across multiple languages. Available in both base and chat-optimized versions, it incorporates reinforcement learning from human feedback for improved safety and helpfulness in conversational applications.
Explore the Future of AI
Your server, your data, under your control
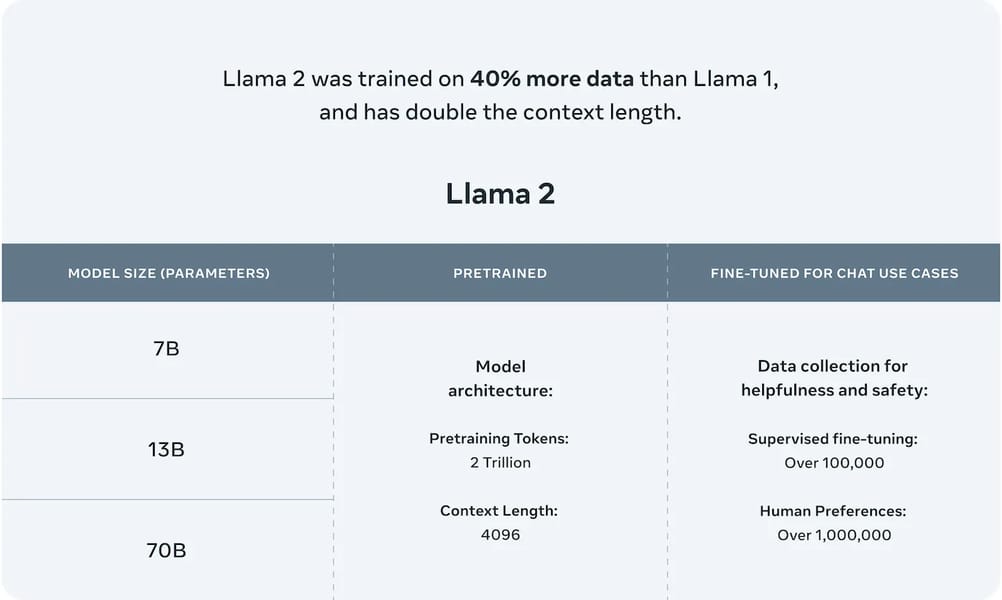
Llama 2 13B is a large language model comprising 13 billion parameters, released as part of the Llama 2 series by Meta. Designed for general-purpose text generation and dialogue, it is available in both a standard pretrained version and a fine-tuned chat-optimized version known as Llama 2-Chat 13B. The release underscores Meta's commitment to open research and commercial use, with the model and its associated resources made available to the public under a permissive community license. Llama 2 13B achieves strong performance across a range of established natural language processing benchmarks and introduces architectural and training advances relative to its predecessor, Llama 1.
Llama 2 stylized logo, featuring references to its 7B, 13B, and 70B model variants as part of Meta's open foundation model release.
Llama 2 13B is an auto-regressive transformer model built upon advances in large scale language modeling. Compared to Llama 1, Llama 2 models have a doubled context length of 4096 tokens, enabling them to consider a wider range of input for each generation step and significantly improving performance on tasks requiring complex reasoning over longer text spans. The model is primarily trained on English-language data, but also incorporates material from 27 additional languages, with English performance remaining optimal.
Pretraining for Llama 2 13B involved extensive exposure to 2 trillion tokens of publicly sourced textual data, representing a 40% increase relative to the Llama 1 models. The architecture maintains standard transformer components while incorporating optimizations for efficiency and scalability. Larger models in the Llama 2 family, such as the Llama 2 70B version, employ Grouped-Query Attention (GQA) for improved inference speed, though this feature is not present in the 13B model, as documented in the Llama 2 technical report.
Table summarizing Llama 2 model variants, the scale of pretraining data (2 trillion tokens), context length (4096 tokens), and scope of human feedback used in fine-tuning.
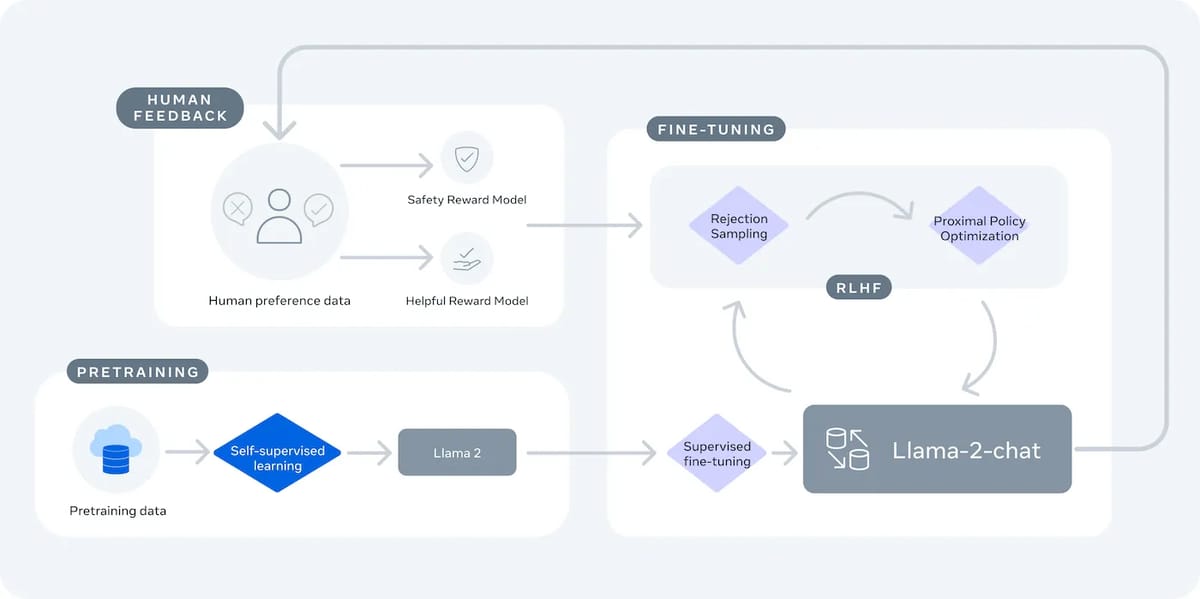
Standard Llama 2 13B is available in both a base (pretrained) form and as Llama 2-Chat 13B, a version specifically fine-tuned for dialogue alignment and safety. Fine-tuning utilizes a multi-step process: initial supervised learning is conducted with publicly available instruction datasets and over 1 million newly collected human annotations on response helpfulness and safety. Subsequent alignment is achieved through reinforcement learning from human feedback (RLHF), leveraging reward models trained on human preferences and further refined through rejection sampling and proximal policy optimization.
Llama 2's RLHF pipeline targets safety and quality, iteratively incorporating human-generated preference data to guide the model towards generating more helpful and less harmful responses in complex, open-ended dialogue settings. The annotations collected for Llama 2 are notable in their scale and diversity for open large language models, as detailed in the Llama 2 responsible use guide.
Flow diagram illustrating Llama 2's multi-stage training process, including human feedback collection, supervised fine-tuning, and iterative RLHF for enhancing dialogue safety and helpfulness.
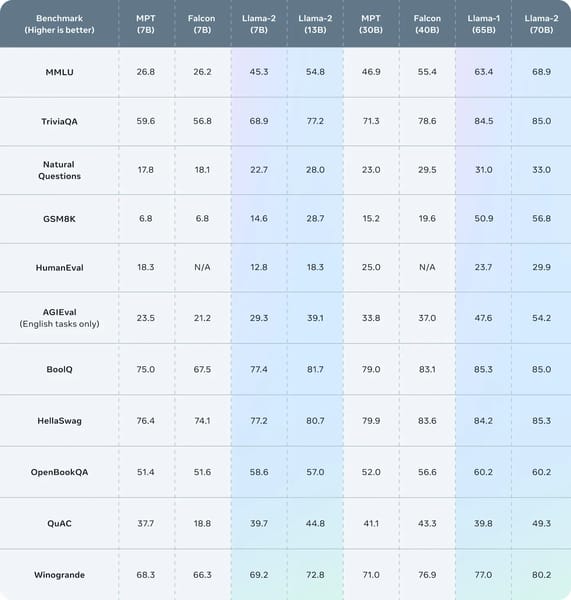
Llama 2 13B demonstrates improved performance compared to its predecessor and strong performance relative to other open models of comparable scale. In academic benchmarks, the 13B variant consistently outperforms Llama 1 13B across tasks including code generation, commonsense reasoning, world knowledge, reading comprehension, mathematical reasoning, and multi-task language understanding. For instance, on MMLU (a widely used multitask benchmark), Llama 2 13B achieves a score of 54.8, compared to 46.9 for Llama 1 13B.
On safety benchmarks such as TruthfulQA, the pretrained Llama 2 13B produces truthful and informative responses in 41.86% of cases, matching its predecessor, while the fine-tuned Llama 2-Chat 13B version achieves 62.18%. Toxic generation rates on Toxigen drop to zero in the fine-tuned model, according to the Llama 2 model card.
Benchmark comparison visualizing Llama 2's performance across a diverse set of evaluation datasets (e.g., MMLU, TriviaQA, HumanEval) relative to other open and closed LLMs.
Use Cases, Limitations, and Responsible Deployment
Llama 2 13B is intended for research and commercial applications in text generation, summarization, question-answering, dialogue, code completion, and related natural language tasks. The fine-tuned Llama 2-Chat models are specifically optimized for conversational agents and dialogue-based systems.
Despite these capabilities, users should be aware of its limitations. The model may occasionally produce inaccurate, biased, or unpredictable outputs, and performs most reliably in English. While significant safety tuning has been applied, outputs should be monitored and extra evaluation may be necessary in sensitive domains or untested languages. The responsible use guide provides detailed recommendations for deploying Llama 2 in accordance with ethical and legal standards.
Llama 2 Responsible Use Guide, outlining best practices and compliance requirements for deploying large language models in research and commercial contexts.
Llama 2 13B and its associated artifacts are distributed under the LLAMA 2 Community License Agreement, permitting use in both research and most commercial applications. Certain restrictions apply for organizations with extremely high user counts, who must seek additional licensing. The Acceptable Use Policy prohibits deployments relating to illegal or high-risk activities and restricts use of the model or its outputs to further train competing large language models. Users are required to retain proper attribution, and all Llama 2 materials are supplied "as is," with no warranties.
Meta maintains supporting documentation, model cards, and feedback channels to encourage responsible development and to facilitate community improvements and reporting.