Launch a dedicated cloud GPU server running Laboratory OS to download and run Llama 2 70B using any compatible app or framework.
Direct Download
Must be used with a compatible app, notebook, or codebase. May run slowly, or not work at all, depending on local system resources, particularly GPU(s) and available VRAM.
Open WebUI is an open-source, self-hosted web interface with a polished, ChatGPT-like user experience for interacting with LLMs. Integrates seamlessly with local Ollama installation.
The most full-featured web interface for experimenting with open source Large Language Models. Featuring a wide range of configurable settings, inference engines, and plugins.
Model Report
Meta / Llama 2 70B
Llama 2 70B is a 70-billion parameter transformer-based language model developed by Meta, featuring Grouped-Query Attention and a 4096-token context window. Trained on 2 trillion tokens with a September 2022 cutoff, it demonstrates strong performance across language benchmarks including 68.9 on MMLU and 37.5 pass@1 on code generation tasks, while offering both pretrained and chat-optimized variants under Meta's commercial license.
Explore the Future of AI
Your server, your data, under your control
Llama 2 70B is a generative large language model developed by Meta as part of the Llama 2 family, designed for advanced natural language understanding and generation. Released in July 2023, Llama 2 70B is notable for its scale—comprising 70 billion parameters—and serves as both a foundational pretrained model and the basis for further fine-tuned conversational systems. The Llama 2 models are distributed under a specialized commercial and research license, emphasizing openness alongside responsible use and safety guidelines, according to the official model overview.
Stylized graphic representing the Llama 2 family, including the 7B, 13B, and 70B parameter variants, highlighting its research and commercial availability.
Llama 2 70B is built upon a transformer-based, auto-regressive architecture with optimizations for efficient large-scale training and inference. It introduces Grouped-Query Attention (GQA) in its larger variants, such as 70B, to accelerate inference and enhance scalability without compromising accuracy. The context window has been expanded to 4096 tokens, twice the context length of the Llama 1 models, allowing for better handling of longer text sequences and more complex prompts, as described in the Llama 2 research publication.
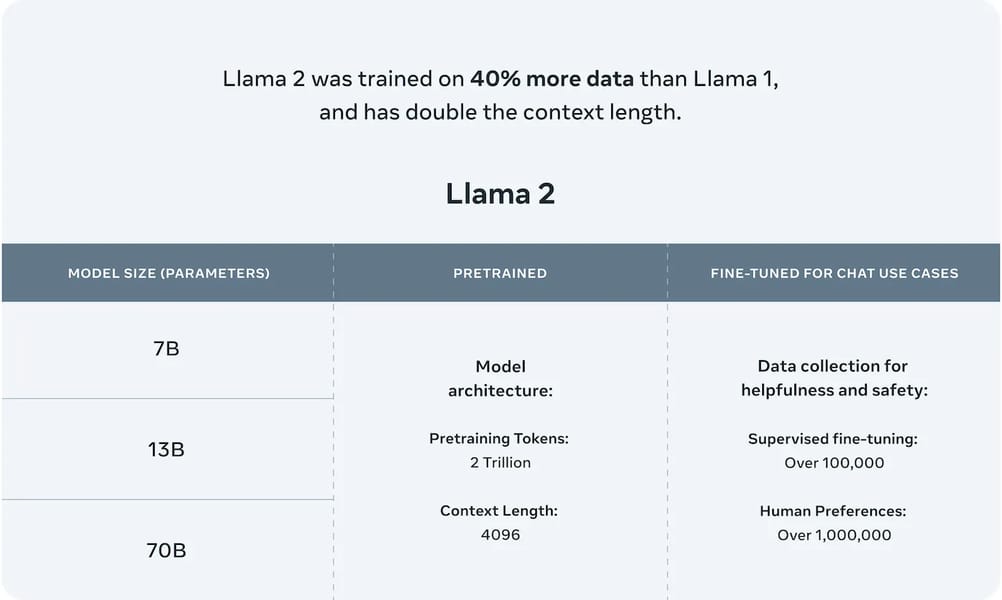
Pretraining utilized 2 trillion tokens from publicly available online sources, exceeding the Llama 1 family's dataset by 40%. The primary language of the training data is English, with supplementary data from 27 other languages, although performance in languages other than English is comparatively limited. The pretraining data cutoff is September 2022.
Infographic highlighting Llama 2’s scale, including 2 trillion pretraining tokens, expanded context length, and detailed parameters for each model size.
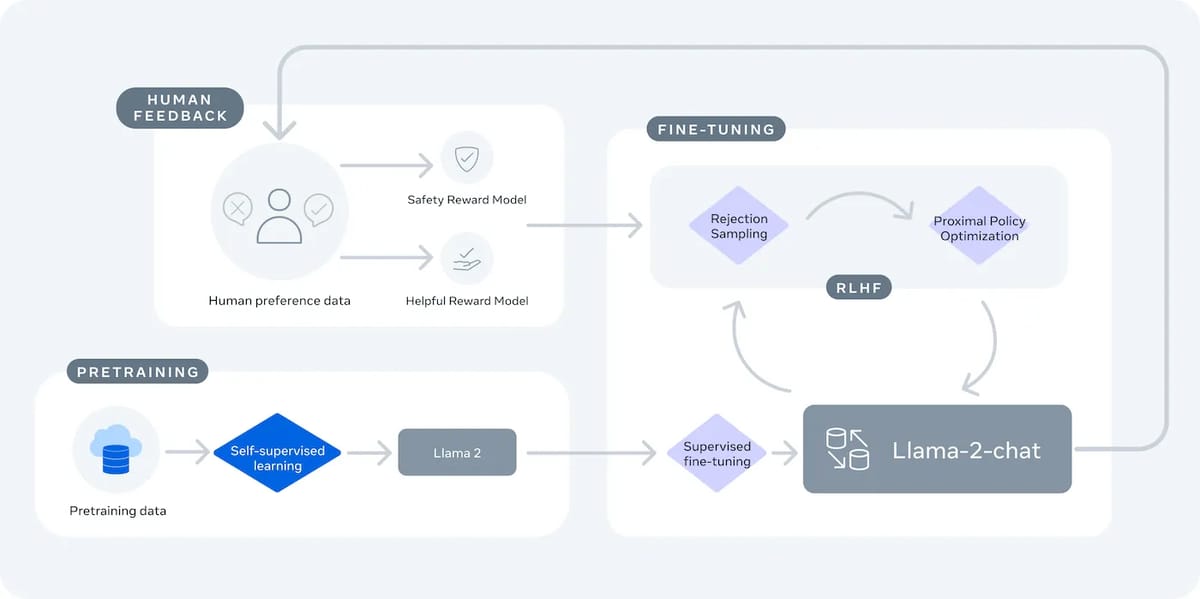
For fine-tuned conversational models, such as Llama-2-Chat 70B, additional training was performed using supervised fine-tuning and reinforcement learning from human feedback (RLHF), leveraging over one million human preference annotations and more than 100,000 supervised examples to align model outputs with human preferences for helpfulness and safety.
Flow chart illustrating the supervised and reinforcement learning from human feedback (RLHF) framework used to fine-tune Llama 2 for conversational safety and helpfulness.
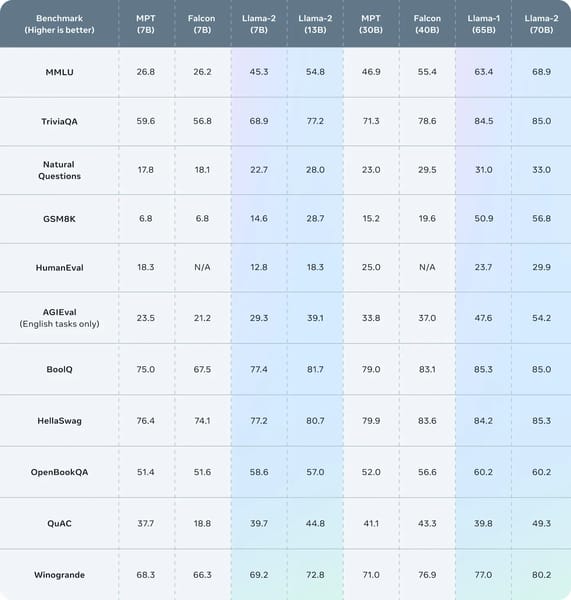
Llama 2 70B demonstrates robust performance across a spectrum of academic language model benchmarks, outperforming both prior Llama 1 models and many contemporary open models. On code generation tasks such as HumanEval and MBPP, it achieves a pass@1 score of 37.5. In commonsense reasoning, spanning metrics like PIQA, SIQA, and HellaSwag, it records an average score of 71.9. For world knowledge benchmarks, including NaturalQuestions and TriviaQA, it attains a score of 63.6.
Other notable benchmark scores include a reading comprehension average of 69.4 (across SQuAD, QuAC, and BoolQ), a math benchmark average of 35.2 (across GSM8K and MATH), a MMLU score of 68.9, and a 51.2 on the "Big Bench Hard" (BBH) tasks. On AGIEval assessments—designed to probe aspects of artificial general intelligence—Llama 2 70B scores 54.2. These results are consistently higher than those of corresponding Llama 1 models and other open-source LLMs in similar parameter ranges, as detailed in the Llama 2 technical documentation.
Benchmark comparison chart showcasing Llama 2 model’s performance across diverse NLP evaluation tasks relative to other leading open LLMs.
Regarding safety, Llama 2 70B achieves a TruthfulQA performance of 50.18% as a pretrained model, which rises to 64.14% in the fine-tuned chat variant. Toxic content generation, as measured by Toxigen, is reduced drastically in Llama-2-Chat 70B to 0.01%, underscoring the impact of RLHF and supervised alignment processes.
Alignment, Safety, and Responsible Use
Meta emphasizes safety and responsible development in Llama 2, with particular attention to alignment for conversational applications. Fine-tuning with RLHF incorporates explicit human feedback to optimize for both helpful and safe responses. The RLHF process in Llama 2 involves a combination of supervised fine-tuning, reward modeling for safety and helpfulness, and iterative policy optimization through rejection sampling and proximal policy optimization.
Visual display of the Responsible Use Guide provided to developers for best practices in deploying LLM-powered products with Llama 2.
Developers are encouraged to conduct additional safety evaluations tailored to their deployment scenarios. The model’s Responsible Use Guide and Acceptable Use Policy provide detailed resources to help ensure legal and ethical integration, as the Llama 2 models are not exhaustively evaluated in every context and remain an evolving technology.
Applications, Limitations, and Licensing
Llama 2 70B is designed for use as a foundational model in research, commercial applications, and a wide range of natural language processing tasks. The model serves as the baseline for Llama-2-Chat, which is optimized for dialogue and assistant use cases. General pretrained versions are suitable for further adaptation to specific tasks including document summarization, question answering, and more, as outlined in the model’s documentation.
However, Llama 2 70B’s strongest performance is in English, given the composition of the training data. Its capabilities in other languages are comparatively limited. As a static, pretrained model with a training data cutoff in September 2022, it is not aware of more recent world events or facts. As with all large language models, Llama 2 70B may produce inaccurate, biased, or otherwise unsuitable outputs, and its deployment requires careful consideration and ongoing evaluation.
The Llama 2 Community License permits free use for research and commercial purposes under specified terms. Redistribution and derivative works are allowed with appropriate attribution and adherence to responsible use guidelines, but the license prohibits using Llama 2 outputs to improve other large language models (apart from Llama 2 and its derivatives), and enforces compliance with the Acceptable Use Policy.
Model Family and Community
The Llama 2 family encompasses several parameter sizes: 7B, 13B, and 70B. Each model is available in both pretrained and chat-optimized versions, enabling different use cases and computational footprints. Compared to Llama 1, the Llama 2 family offers expanded datasets, longer context length, and enhanced alignment through RLHF.
Llama 2’s release is supported by a network of research and commercial partners who contribute to its ecosystem and promote open, safe research and innovation. The broad support from the community is visible through collaborations, contributions, and adoption across research, academia, and industry.