Launch a dedicated cloud GPU server running Laboratory OS to download and run Llama 2 7B using any compatible app or framework.
Direct Download
Must be used with a compatible app, notebook, or codebase. May run slowly, or not work at all, depending on local system resources, particularly GPU(s) and available VRAM.
Open WebUI is an open-source, self-hosted web interface with a polished, ChatGPT-like user experience for interacting with LLMs. Integrates seamlessly with local Ollama installation.
The most full-featured web interface for experimenting with open source Large Language Models. Featuring a wide range of configurable settings, inference engines, and plugins.
Model Report
Meta / Llama 2 7B
Llama 2 7B is a transformer-based language model developed by Meta with 7 billion parameters, trained on 2 trillion tokens with a 4,096-token context length. The model supports text generation in English and 27 other languages, with chat-optimized variants fine-tuned using supervised learning and reinforcement learning from human feedback for dialogue applications.
Explore the Future of AI
Your server, your data, under your control
Llama 2 7B is a large language model developed by Meta, forming part of the Llama 2 family of generative text models. Llama 2 7B has 7 billion parameters and is part of the Llama 2 series, which also includes 13B and 70B parameter variants. Released for both research and commercial purposes, Llama 2 models facilitate access to language generation capabilities. The Llama 2-Chat variants have been fine-tuned for dialogue and exhibit performance on standard benchmarks consistent with human preferences for useful and safe outputs, as described in the Llama 2 research paper.
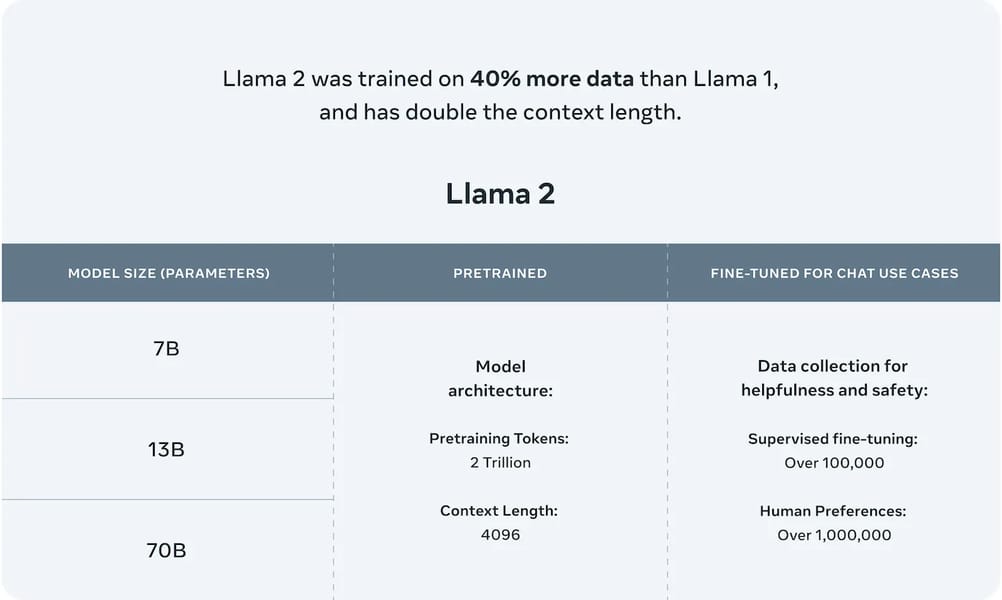
Stylized graphic highlighting Llama 2 and its model variants, including the 7B, 13B, and 70B parameter options.
Llama 2 7B belongs to the class of transformer-based language models using an auto-regressive architecture. The model is pretrained with 7 billion parameters on a corpus comprising two trillion tokens of publicly available online data. The training data represents a 40% increase compared to its predecessor, Llama 1, and the context length is extended to 4,096 tokens, twice that of previous versions. The fine-tuned "Llama-2-Chat" variants utilize supervised fine-tuning and reinforcement learning from human feedback (RLHF) to further optimize for dialogue quality, safety, and helpfulness, employing methods such as rejection sampling and proximal policy optimization, as detailed in the official model documentation.
Infographic showing the scale of Llama 2's training data, context length, and supervised fine-tuning process across model sizes.
Llama 2 7B, like the larger variants, does not use Meta user data for training or fine-tuning. Data for pretraining has a cutoff of September 2022, while supervised and preference-aligned data for fine-tuning includes examples curated up to July 2023. The training pipeline incorporates Meta’s large-scale infrastructure and custom libraries, leveraging both proprietary and third-party computing resources.
Fine-Tuning and Human Feedback
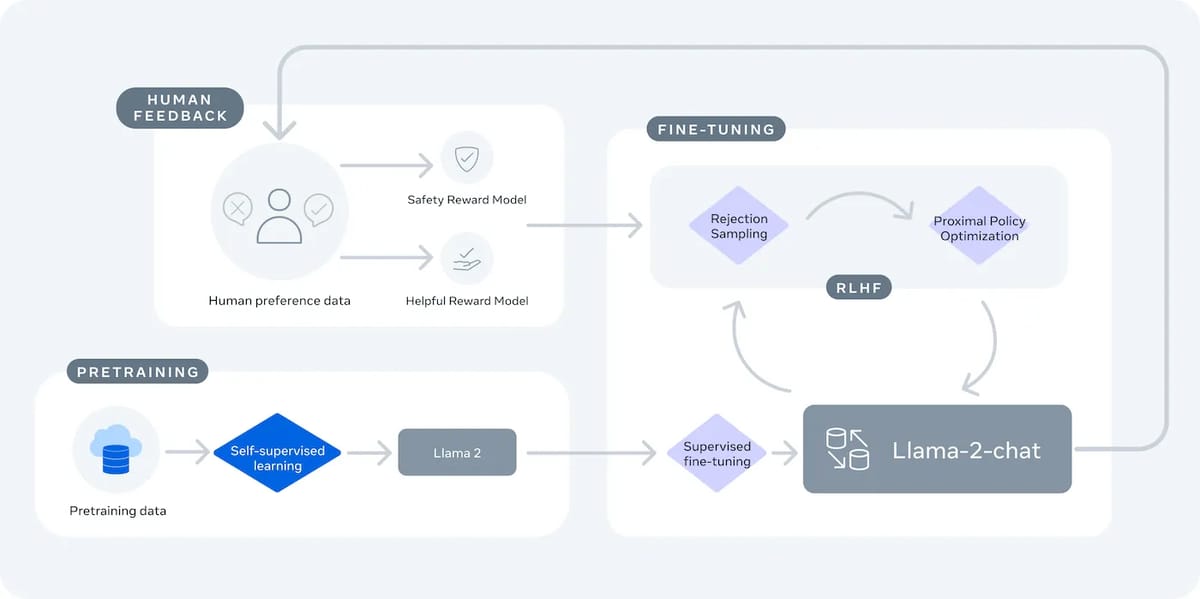
Alignment with human intent and safety has been prioritized in the development of Llama-2-Chat models. After pretraining, the model undergoes supervised fine-tuning using instructional datasets and a substantial set of human-annotated examples. The RLHF procedure integrates human preference data to build reward models for helpfulness and safety, which then guide further optimization.
Flow chart illustrating how Reinforcement Learning from Human Feedback (RLHF) is applied to produce Llama-2-Chat models focused on safety and helpfulness.
Supervised fine-tuning (SFT) is used as an initial phase, followed by iterative reinforcement learning steps that refine outputs in light of human judgement using techniques such as rejection sampling and proximal policy optimization. This alignment methodology is documented in the Llama 2 paper.
Performance and Benchmarking
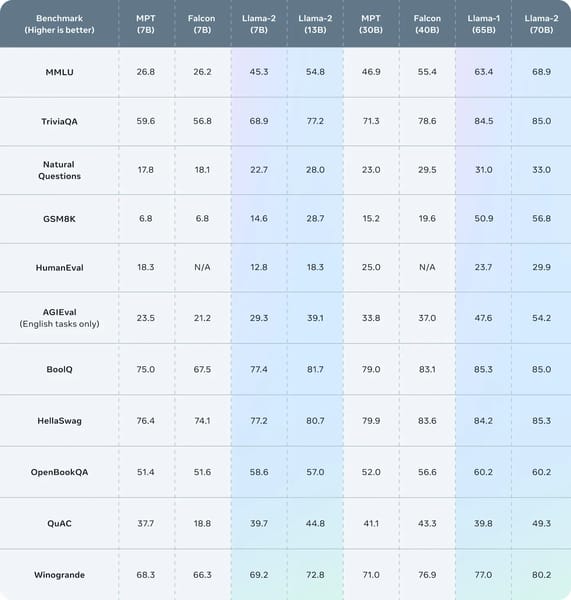
Llama 2 7B exhibits enhanced performance compared to previous models across a variety of academic benchmarks. When evaluated, Llama 2 7B achieves higher scores in areas such as code generation, commonsense reasoning, and reading comprehension relative to comparable open models. For instance, the Llama 2 7B model reaches 45.3 in MMLU, 14.6 in math, and 16.8 in code evaluations, surpassing Llama 1 7B in each category. The fine-tuned Llama-2-Chat variant outperforms both open-source and select proprietary models in specific helpfulness and truthfulness tests, as reflected in side-by-side academic comparisons benchmark results.
Benchmark table comparing Llama 2 with other language models across key tasks, emphasizing performance gains in MMLU, world knowledge, code, and more.
Improvements over earlier iterations include increased scores on TruthfulQA and a reduction in toxicity as measured by ToxiGen. These results contribute to model deployments that exhibit lower toxicity and higher truthfulness in practical applications.
Capabilities and Use Cases
Llama 2 7B is designed primarily for text generation in English, with additional exposure to data from 27 other languages. The model can be adapted for a broad array of tasks that require natural language understanding and generation, including conversational agents, document summarization, question answering, and code completion. The chat-optimized versions, Llama-2-Chat, are tailored for interactive dialogue applications and virtual assistants, incorporating extensive supervised and RLHF fine-tuning.
While non-English capabilities are present, output quality is generally higher in English, and performance may vary across other languages. Meta provides guidance for safe and responsible application development to assist users in developing applications based on Llama 2.
Visual cover for Meta's Responsible Use Guide, outlining best practices for developers working with Llama 2 models.
Llama 2 7B, consistent with other large language models, is subject to inherent unpredictability in its outputs and may occasionally generate inaccurate, biased, or objectionable content. The model's safety evaluations focus mainly on English, and thorough application-specific risk assessments are recommended prior to deployment. Use cases must comply with local laws, Meta’s Acceptable Use Policy, and licensing agreements.
The model is distributed under the custom LLAMA 2 Community License, which allows use, modification, and distribution under defined conditions. Terms include mandatory attribution, adherence to an acceptable use policy, restrictions against leveraging Llama 2 outputs to improve other large language models, and special provisions for entities with over 700 million monthly active users, who must seek a separate license.
Timeline and Ecosystem
Llama 2 models were trained from January to July 2023 and publicly announced with the release of the foundational Llama 2 research paper on July 18, 2023. The open availability of Llama 2 has led to an ecosystem of collaborators, partners, and research initiatives focused on expanding the use and assessment of large language models.
Collage of partner logos, representing global collaborators and supporters in the Llama 2 ecosystem.
These resources provide technical documentation, responsible usage guidelines, community developments, and detailed instructions for working with the Llama 2 7B model.