Note: MusicGen weights are released under a CC-BY-NC 4.0 License, and cannot be utilized for commercial purposes. Please read the license to verify if your use case is permitted.
Laboratory OS
Launch a dedicated cloud GPU server running Laboratory OS to download and run MusicGen using any compatible app or framework.
Direct Download
Must be used with a compatible app, notebook, or codebase. May run slowly, or not work at all, depending on local system resources, particularly GPU(s) and available VRAM.
Experiment with various cutting-edge audio generation models, such as Bark (Text-to-Speech), RVC (Voice Cloning), and MusicGen (Text-to-Music).
Model Report
Meta / MusicGen
MusicGen is a text-to-music generation model developed by Meta's FAIR team as part of the AudioCraft library. The model uses a two-stage architecture combining EnCodec neural audio compression with a transformer-based autoregressive language model to generate musical audio from textual descriptions or melody inputs. Trained on approximately 20,000 hours of licensed music, MusicGen supports both monophonic and stereophonic outputs and demonstrates competitive performance in objective and subjective evaluations against contemporary music generation models.
Explore the Future of AI
Your server, your data, under your control
MusicGen is a generative artificial intelligence model developed by the FAIR team at Meta AI for text-to-music synthesis. The model is a component of the AudioCraft library, which provides a suite of tools and models for audio generation and processing using deep learning techniques. Introduced in 2023, MusicGen is trained to generate high-fidelity musical audio conditioned on textual descriptions or, optionally, melody inputs. It supports both monophonic and stereophonic outputs and has been released for research and non-commercial use.
A conceptual flow diagram showing how MusicGen transforms a text prompt into an audio music output. Example prompt: 'Lo-fi song with organic samples, saxophone solo.'
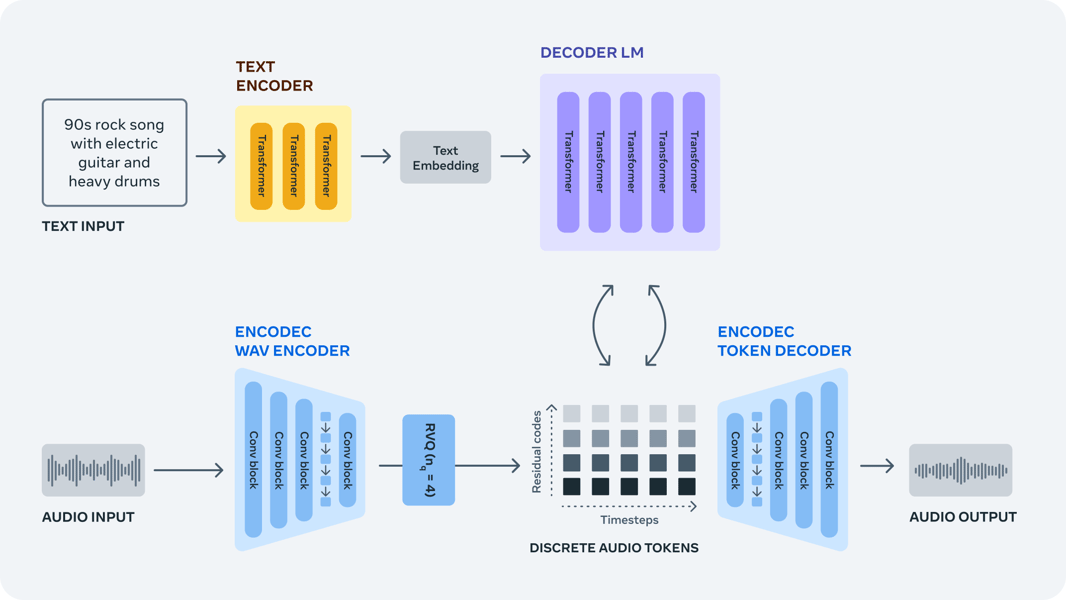
MusicGen employs a two-stage architecture combining a neural audio codec and a transformer-based autoregressive language model. The core audio representation is built upon EnCodec, a convolutional auto-encoder with Residual Vector Quantization (RVQ). Audio is tokenized into discrete codes, which the generative model then predicts sequentially.
The EnCodec model encodes audio signals at a 32 kHz sample rate into a latent representation, which is quantized using four stacked codebooks, each with 2048 entries. This process yields a discrete sequence of tokens representing the audio content. For stereo generation, EnCodec is applied independently to the left and right channels, producing eight codebooks per frame.
The generative stage uses a single-stage, causal transformer decoder, conditioned either on text, melodic context, or both. Text descriptions are transformed into embeddings via a dedicated text encoder. Melody conditioning relies on chromagram representations extracted from reference audio, providing harmonic and melodic guidance. The model employs cross-attention blocks to integrate conditioning signals and uses memory-efficient Flash Attention for scalability.
Schematic diagram of the AudioCraft architecture, illustrating how text descriptions and discrete audio tokens interact for audio generation in MusicGen and related models.
A feature of MusicGen is its efficient codebook interleaving approach, such as the "delay pattern," which reduces autoregressive steps for a given audio duration, enabling faster inference and support for longer outputs.
The model is optimized on 30-second audio segments, using the AdamW optimizer and mixed-precision (float16) training to balance computational efficiency and performance. Conditioning and augmentation techniques—such as dropout and condition-merging—were applied to descriptions, improving robustness. For melody-guided training, conditioning is performed on extracted chromagrams, with drums and bass typically omitted from the chromagram reference for clarity. Classifier-free guidance is used during sampling to enhance adherence to user prompts.
Evaluation and Performance
MusicGen's performance has been evaluated using both objective and subjective criteria. Objective metrics include Frechet Audio Distance (FAD) for perceptual quality, Kullback-Leibler Divergence for label distribution similarity, CLAP Score for audio-text alignment, and chroma cosine similarity for melody adherence. Human studies assess overall perceptual quality, text relevance, and melodic alignment on a scale of 1–100.
Benchmarking on the MusicCaps dataset demonstrates that MusicGen achieves competitive results in both objective and subjective evaluations compared to contemporary models including MusicLM, Noise2Music, Riffusion, and Mousai. The 1.5B parameter version receives high marks for both audio quality and textual relevance, with the stereophonic models generally receiving higher perceptual ratings than monophonic counterparts.
MusicGen 3.3B Mono Output
Mono music sample generated by MusicGen 3.3B with the prompt: 'A grand orchestral arrangement with thunderous percussion, epic brass fanfares, and soaring strings, creating a cinematic atmosphere fit for a heroic battle.' [Source]
MusicGen 3.3B Stereo Output
Stereo music sample generated by MusicGen 3.3B using the same orchestral prompt as above, demonstrating spatialization and depth in the generated audio. [Source]
MusicGen 3.3B - Classic Reggae
Mono output for the prompt: 'Classic reggae track with an electronic guitar solo.' [Source]
MusicGen 3.3B Stereo - 80s Electronic
Stereo output for the text prompt: '80s electronic track with melodic synthesizers, catchy beat and groovy bass.' [Source]
Applications and Use Cases
MusicGen enables a variety of applications centered on automated and controlled music creation. Primary applications include generating music from descriptive text prompts, producing music that follows the structure of a provided melody, and supporting music co-creation tools for both research and artistic workflows. The model can generate outputs beyond its training window using a sliding window approach, facilitating the synthesis of longer tracks by reusing the last section of prior outputs as context.
Researchers utilize MusicGen to explore the capabilities and limitations of large-scale generative models for music, as well as to study aspects of musical coherence, conditioning, and style transfer. The design also facilitates iterative refinement of musical outputs, as users can combine text conditioning with melody inputs for more nuanced control.
Limitations
Despite its capabilities, MusicGen exhibits several notable limitations. The model is unable to generate realistic vocals, as its training data omitted vocal tracks. Its conditioning performance is optimized for English-language prompts, with reduced reliability for non-English inputs. Additionally, since the majority of the training data is Western or EDM-focused, the generated music often reflects these stylistic biases and may not generalize to all musical cultures or genres.
Technical limitations include occasional generation of abrupt or silent endings, a reliance on careful prompt engineering to achieve desired outcomes, and constrained fine-grained control over specific musical attributes due to its single-stage generation approach. MusicGen’s accuracy for out-of-domain prompts is limited, and subjective quality improvements tend to plateau for model sizes beyond 1.5 billion parameters.
Model Family and Related Work
MusicGen is a member of the AudioCraft library, which features related models such as AudioGen for text-to-sound effects, EnCodec for neural audio compression, and MAGNeT, a non-autoregressive text-to-music model. Within the landscape of music generation, MusicGen’s autoregressive approach, single-stage decoding, and chromagram-based melody conditioning distinguish it from models such as MusicLM and Noise2Music.