Launch a dedicated cloud GPU server running Laboratory OS to download and run Qwen 1.5 72B using any compatible app or framework.
Direct Download
Must be used with a compatible app, notebook, or codebase. May run slowly, or not work at all, depending on local system resources, particularly GPU(s) and available VRAM.
Open WebUI is an open-source, self-hosted web interface with a polished, ChatGPT-like user experience for interacting with LLMs. Integrates seamlessly with local Ollama installation.
The most full-featured web interface for experimenting with open source Large Language Models. Featuring a wide range of configurable settings, inference engines, and plugins.
Model Report
Alibaba Cloud / Qwen 1.5 72B
Qwen 1.5 72B is a 72-billion parameter transformer-based language model developed by Alibaba Cloud's Qwen Team and released in February 2024. The model supports a 32,768-token context window and demonstrates strong multilingual capabilities across 12 languages, achieving competitive performance on benchmarks including MMLU (77.5), C-Eval (84.1), and GSM8K (79.5). It features alignment optimization through Direct Policy Optimization and Proximal Policy Optimization techniques, enabling effective instruction-following and integration with external systems for applications including retrieval-augmented generation and code interpretation.
Explore the Future of AI
Your server, your data, under your control
Qwen1.5-72B is a large-scale generative AI model and a central member of the Qwen1.5 series, developed by the Qwen Team and released in February 2024. This iteration emphasizes advanced alignment with human preferences, robust multilingual proficiency, and enhanced developer accessibility. Qwen1.5-72B has been benchmarked extensively against leading models, displaying consistent performance gains in language understanding, code generation, and external system integration.
Qwen1.5 in context: a timeline of the Qwen model development, highlighting the February 2024 release of Qwen1.5 alongside earlier iterations.
Qwen1.5-72B follows the transformer-based architecture typical of recent large language models, offering both base and chat-optimized variants across multiple parameter scales. The 72B-parameter version supports a context window of up to 32,768 tokens, with settings optionally extendable in configuration files for longer sequences, enabling flexible adaptation for tasks requiring extended memory.
Alignment was a central concern in model design; techniques such as Direct Policy Optimization (DPO) and Proximal Policy Optimization (PPO) were utilized to fine-tune instruction-following ability and to closely match model outputs to human preference. The open-source documentation does not detail the proprietary datasets used for pre-training, but references the inclusion of broad multilingual materials and the use of community open-source repositories for evaluation benchmarks. Quantized model formats, such as GPTQ (Int4/Int8), AWQ, and GGUF, are officially provided, facilitating efficient deployment and lower resource utilization for inference.
Multilingual and General Language Capabilities
Qwen1.5-72B demonstrates considerable strength in multilingual understanding, covering at least 12 languages from diverse regions including Europe, East Asia, and Southeast Asia. Performance analysis on representative tasks shows substantial gains over earlier models—and in several cases, over peers like Llama 2 70B and GPT-3.5—in translation, language reasoning, and code execution benchmarks.
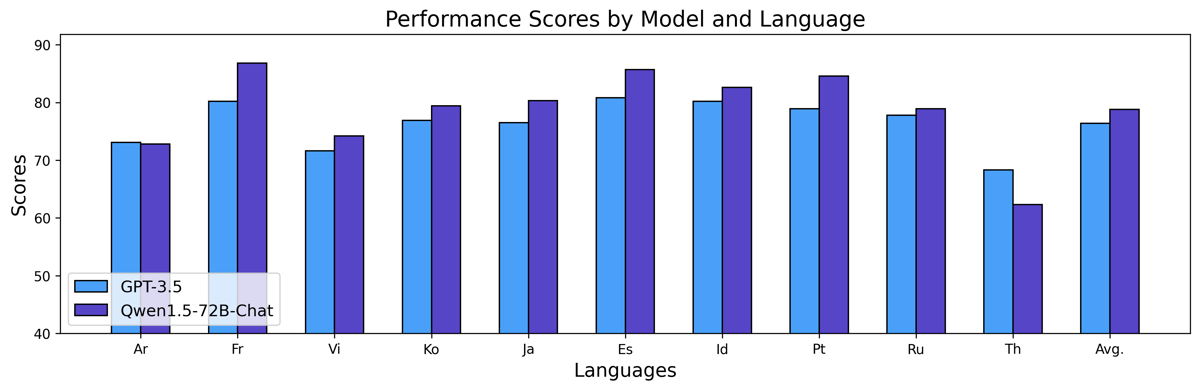
Qwen1.5-72B-Chat outperforms GPT-3.5 in multilingual language tasks across several languages including Arabic, French, Vietnamese, Korean, Japanese, Spanish, Indonesian, Portuguese, Russian, and Thai.
In tasks such as the MMLU benchmark (77.5), C-Eval (84.1), GSM8K (79.5), MATH (34.1), and HumanEval (41.5), Qwen1.5-72B displays broad competence across knowledge, reasoning, and coding domains. These benchmarks indicate not only linguistic fluency but also advanced capability in mathematics and programming, although there remains a performance gap in code interpretation when compared to models such as GPT-4.
Alignment with Human Preferences and Benchmark Performance
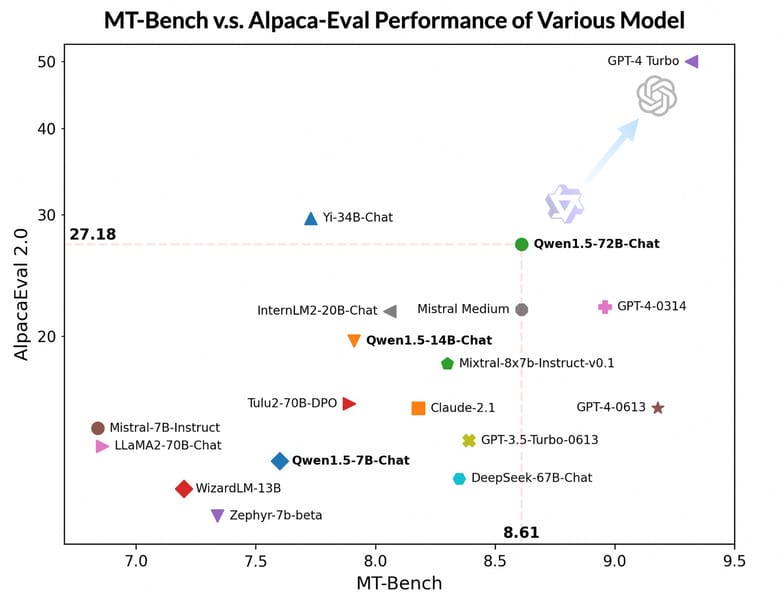
The Qwen1.5-72B-Chat model demonstrates high scores on benchmarks designed to measure alignment with human judgment and instruction-following quality. On MT-Bench the model achieves an average score of 8.61, with a 27.18 win rate on AlpacaEval 2.0.
Qwen1.5-72B-Chat achieves competitive results on MT-Bench and AlpacaEval 2.0, as shown in this benchmark comparison plot—prompting evaluation against models like GPT-4-Turbo and Mistral Medium.
Performance is especially notable when compared to contemporaries such as Claude-2.1, GPT-3.5-Turbo, and Mixtral 8x7B-Instruct, and approaches the scores of Mistral Medium. However, the model continues to trail GPT-4-Turbo on several of these gold-standard alignment benchmarks.
Integration, External System Connectivity, and Application Domains
One of the distinctive features of Qwen1.5-72B is its capacity for external system integration, including Retrieval-Augmented Generation (RAG), API-based tool and function calling for AI agent use cases, and Python code interpretation. The model performs competitively on RAG benchmarks, particularly in tasks requiring information retrieval under noise or counterfactual scenarios, and shows effective agent execution in both English and Chinese as measured by T-Eval.
Extensive evaluations demonstrate high tool-use accuracy (above 90% for both selection and input categories) and strong, though not leading, performance in mathematical and visualization-based code execution. The LEval long-context benchmark further highlights the model's ability to maintain performance in tasks involving complex, extended documents or dialogues.
Qwen1.5-72B has practical applications in conversational systems, code assistants, translation engines, mathematical problem solving, and customizable AI agents—thanks to its multilingual fluency, contextual memory, and open-ended instruction following.
Limitations and Future Directions
Despite robust scores in multilingual and alignment assessments, Qwen1.5-72B exhibits certain limitations. On advanced code interpretation and mathematical reasoning tasks, the model’s performance does not yet match that of GPT-4, especially for complex programming or difficult visualization problems. The efficacy of context windows significantly longer than 32,768 tokens, enabled by configuration changes, may vary and is not uniformly validated.
Continued improvements are anticipated in subsequent iterations to address these areas, with particular focus on enhancing coding capabilities and ensuring stable performance in longer-context applications.
Licensing and Access
Qwen1.5 models, including the 72B parameter variant, are open-source and are distributed via platforms like Hugging Face and ModelScope. While model licensing is not explicitly detailed in all official documentation, their open-source status facilitates broad research, adaptation, and integration into downstream AI pipelines.