Launch a dedicated cloud GPU server running Laboratory OS to download and run Qwen 2.5 14B using any compatible app or framework.
Direct Download
Must be used with a compatible app, notebook, or codebase. May run slowly, or not work at all, depending on local system resources, particularly GPU(s) and available VRAM.
Open WebUI is an open-source, self-hosted web interface with a polished, ChatGPT-like user experience for interacting with LLMs. Integrates seamlessly with local Ollama installation.
The most full-featured web interface for experimenting with open source Large Language Models. Featuring a wide range of configurable settings, inference engines, and plugins.
Model Report
Alibaba Cloud / Qwen 2.5 14B
Qwen 2.5 14B is a 14.7 billion parameter transformer-based language model developed by Alibaba Cloud's Qwen Team, featuring a 128,000 token context window and support for over 29 languages. The model utilizes advanced architectural components including Grouped Query Attention, RoPE embeddings, and SwiGLU activation, and was pretrained on up to 18 trillion tokens of diverse multilingual data for applications in reasoning, coding, and mathematical tasks.
Explore the Future of AI
Your server, your data, under your control
Qwen 2.5-14B is a large language model developed by the Qwen Team at Alibaba Group. Released in September 2024, it is part of the Qwen 2.5 model family, which builds upon previous Qwen iterations and introduces several specialized variants. Qwen 2.5 models are available as open-source, dense, decoder-only transformer models and span a range of parameter sizes and capabilities. The 14B version targets developers and researchers seeking a scalable base for further fine-tuning and domain-specific adaptation.
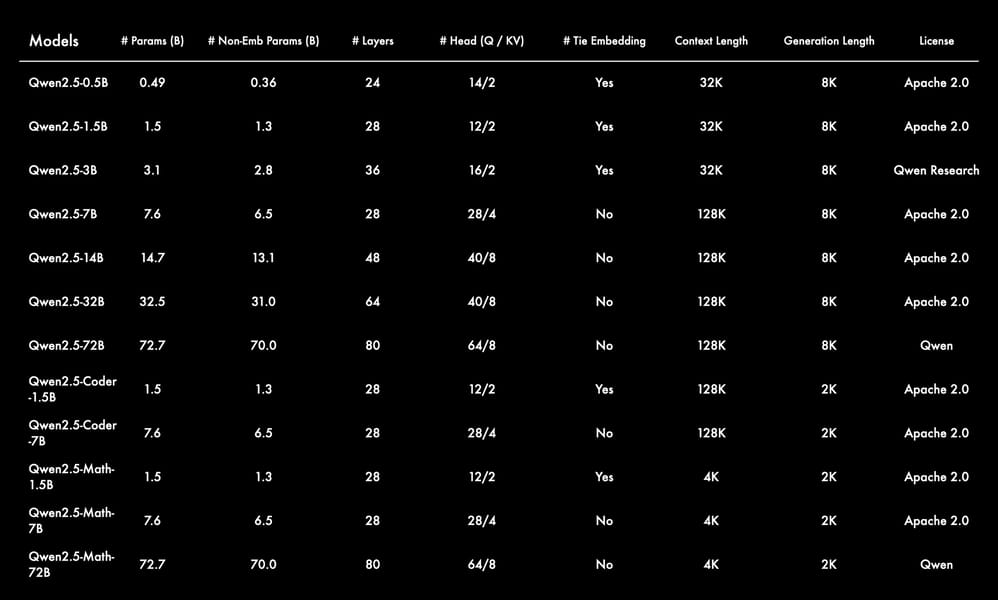
A tabular summary of the Qwen2.5 model family, highlighting key architectural and licensing details for each model variant.
An introduction to the Qwen2.5 project, detailing its motivations, architecture, and capabilities. [Source]
Model Architecture and Features
Qwen2.5-14B is a causal language model built on the transformer architecture. It utilizes Rotary Position Embeddings (RoPE), the SwiGLU activation function, RMSNorm for layer normalization, and introduces Attention QKV biasing to enhance expressivity. The model contains approximately 14.7 billion parameters in total, with 13.1 billion non-embedding parameters. Architecturally, it is organized into 48 layers and implements Grouped Query Attention (GQA), allocating 40 heads for query vectors and 8 heads for key/value vectors.
Qwen2.5-14B supports an extended context window of up to 128,000 tokens, facilitating applications that demand significant memory and document processing capabilities. For generation tasks, it can produce output sequences of up to 8,000 tokens. The design of Qwen 2.5 series emphasizes adaptability to post-training techniques such as supervised fine-tuning and reinforcement learning from human feedback, and the base models are not recommended for direct conversational use prior to such refinement. Technical specifications and architectural choices are further detailed in the Qwen2.5 announcement and technical documentation.
Pretraining Data and Multilingual Support
Qwen2.5 models, including the 14B variant, are pretrained on a large-scale corpus comprising up to 18 trillion tokens. The pretraining data covers diverse domains and is curated for high data quality, aiming to foster robust language understanding and generation capabilities. The Qwen2.5 family also features expert models, such as Qwen2.5-Coder-7B and Qwen2.5-Math-7B, which are trained on specialist datasets, including 5.5 trillion code-related tokens for the Coder variant and synthetic math-focused data for the Math variant.
A hallmark of Qwen2.5 is its strong multilingual support. The model is capable of working with over 29 languages, including Chinese, English, French, Spanish, Portuguese, German, Italian, Russian, Japanese, Korean, Vietnamese, Thai, and Arabic. This enables enhanced instruction following and translation across a broad linguistic landscape, as documented in the Qwen technical resources and Hugging Face model repository.
Performance and Benchmarking
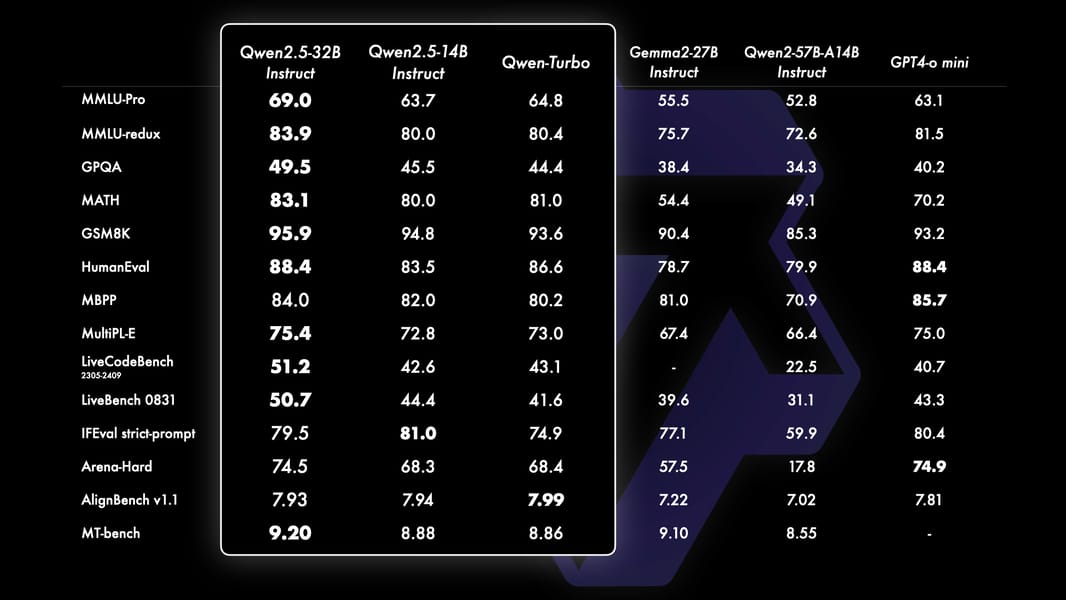
The Qwen2.5-14B model demonstrates competitive performance across a range of language understanding, reasoning, coding, and mathematical benchmarks. Notably, Qwen2.5-14B often matches or outperforms other models in its parameter class and, in some instances, rivals larger models on select tasks. Evaluation results highlight strong knowledge representation on the MMLU benchmark (with scores above 85), as well as high proficiency in coding (HumanEval 85+) and mathematics (MATH 80+).
Benchmark results comparing Qwen2.5-14B and Qwen2.5-32B to peer models on tasks including knowledge, reasoning, coding, and alignment.
In comprehensive comparisons, the Qwen2.5-14B model's instruction-following, long text generation, structured data understanding, and JSON output capabilities are evident. The model demonstrates robustness to various prompt structures, which improves both role-play and condition-setting for downstream chatbot applications. Detailed evaluation metrics and benchmarks are available in the Qwen2.5 performance summary.
Applications and Usage
While the base Qwen2.5-14B model is not intended for direct deployment in conversational settings without further fine-tuning, it serves as a foundation for a variety of advanced applications after supervised training. Use cases include complex logical reasoning, advanced mathematics, and code synthesis. The model is suitable for tasks such as multi-turn dialogues, instruction following, creative writing, and role-playing, particularly when preference alignment or agent-based functionality is required.
Specialized variants, such as Qwen2.5-Coder-7B and Qwen2.5-Math-7B, are tailored for intensive coding assistance—including debugging and code suggestion—and mathematical problem-solving using advanced reasoning strategies. After domain-specific or instruction tuning, Qwen2.5-14B may also serve as the core model in multi-agent systems and tool-augmented pipelines, enabled by its ability to handle diverse prompt styles and system settings. Further details on deployment and optimal settings can be found in the Qwen2.5 GitHub repository.
Model Family, Licensing, and Limitations
The Qwen2.5 series is positioned between Qwen2 and Qwen3 in the Qwen model family. Later generations, such as Qwen3, introduce additional architectural refinements, extended language coverage, and features like "thinking mode" and streamlined instruction tuning. Qwen2.5 models are distributed under the Apache 2.0 license, with the exception of select 3B and 72B variants.
Qwen2.5-14B, as a base model, is not recommended for out-of-the-box conversational use and should be fine-tuned for most real-world applications. In some specialized benchmarks, certain competing models may demonstrate higher scores, and context management settings may require attention when deployed in different environments. The model’s licensing, source code, and weights are openly available in their respective Hugging Face and GitHub repositories.