Launch a dedicated cloud GPU server running Laboratory OS to download and run Qwen 2.5 Math 7B using any compatible app or framework.
Direct Download
Must be used with a compatible app, notebook, or codebase. May run slowly, or not work at all, depending on local system resources, particularly GPU(s) and available VRAM.
Open WebUI is an open-source, self-hosted web interface with a polished, ChatGPT-like user experience for interacting with LLMs. Integrates seamlessly with local Ollama installation.
The most full-featured web interface for experimenting with open source Large Language Models. Featuring a wide range of configurable settings, inference engines, and plugins.
Model Report
Alibaba Cloud / Qwen 2.5 Math 7B
Qwen 2.5 Math 7B is a 7.62-billion parameter language model developed by Alibaba Cloud that specializes in mathematical reasoning tasks in English and Chinese. The model employs chain-of-thought reasoning and tool-integrated approaches using Python interpreters for computational tasks. It demonstrates improved performance over its predecessor on mathematical benchmarks including MATH, GSM8K, and Chinese mathematics evaluations, achieving 83.6 on MATH using chain-of-thought methods.
Explore the Future of AI
Your server, your data, under your control
Qwen 2.5 Math 7B is a large language model (LLM) developed to address complex mathematical reasoning tasks in both English and Chinese. As part of the Qwen2.5-Math series, this 7.62-billion parameter model is engineered for enhanced accuracy in mathematical problem-solving, leveraging advanced reasoning techniques and integrating external computational tools. The Qwen2.5-Math family comprises multiple model sizes, instruction-tuned variants, and a specialized mathematical reward model. The series reflects iterative advances over its predecessor, Qwen2-Math, offering improvements in data scale, bilingual capabilities, and benchmark performance.
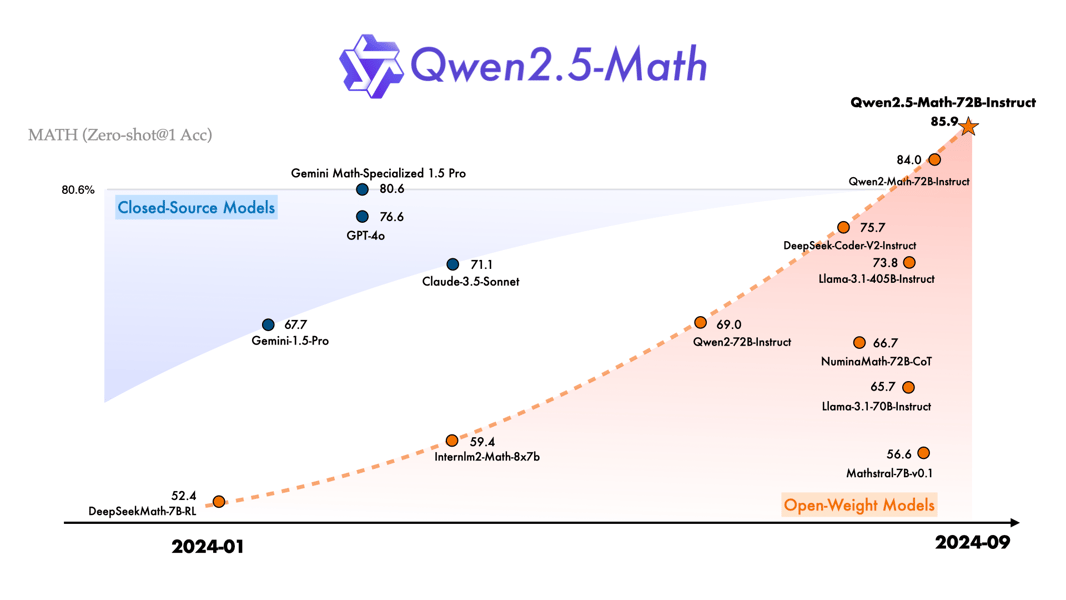
Performance trajectory of mathematical LLMs, with Qwen2.5-Math-72B-Instruct demonstrating high performance on zero-shot MATH accuracy.
Qwen2.5-Math-7B builds upon the Qwen2.5 base model architecture, inheriting language understanding abilities as well as code and text reasoning. The model’s mathematical proficiency is developed through a comprehensive training pipeline that includes pre-training, supervised fine-tuning (SFT), reward modeling, and reinforcement learning.
A distinguishing aspect of the Qwen2.5-Math series is the integration of an expanded and refined mathematical corpus. Pre-training data, synthesized with earlier iterations such as Qwen2-Math-72B-Instruct, is augmented with a large volume of domain-specific material in both English and Chinese—including datasets sourced from the web, academic texts, and mathematical code repositories. This resulted in the creation of the Qwen Math Corpus v2, which exceeds 1 trillion tokens and supports a 4K context length.
The specialization pipeline includes instruction-tuning with conversational data, training a 72B-parameter mathematical reward model for supervised fine-tuning (using rejection sampling), and post-training enhancements using both tool-integrated reasoning (TIR) and chain-of-thought (CoT) data generation.
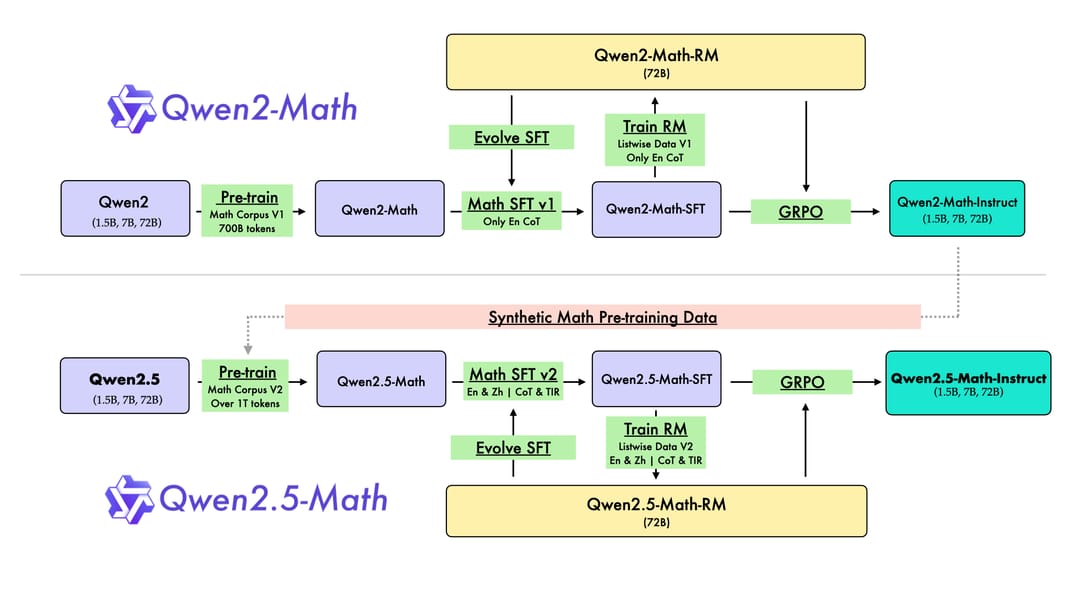
Architectural overview of the Qwen2.5-Math development pipeline, detailing pre-training, supervised fine-tuning, reward modeling, and instruction-tuning workflows.
Qwen2.5-Math-7B employs two primary approaches for mathematical problem solving. The first, chain-of-thought (CoT), structures solutions via step-by-step logical reasoning, which can be applied to complex, multi-step problems. The second approach, tool-integrated reasoning (TIR), augments the model's symbolic and algorithmic computation abilities by embedding external tools within its workflow, notably leveraging a Python interpreter for code-based calculations.
TIR has resulted in performance gains, particularly in benchmarks requiring precise computation or symbolic manipulation. In addition, the instruction-tuned models provide conversational formats suited to interactive educational or tutoring settings, while base models are optimized for prompt completion and as foundations for further fine-tuning.
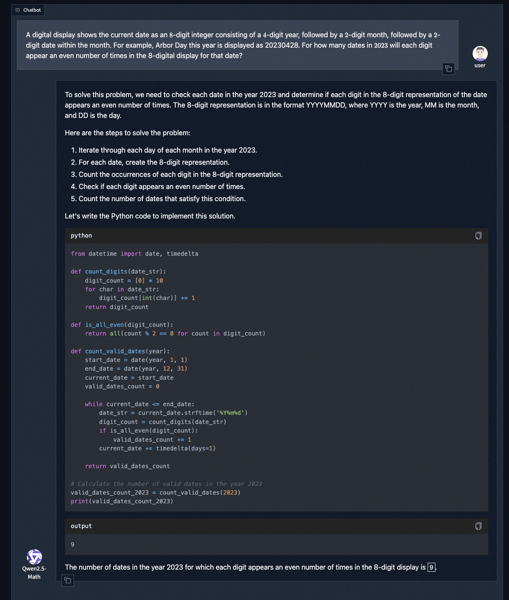
Example of Tool-Integrated Reasoning: The model outlines a solution plan, generates Python code, and executes it to solve a math problem.
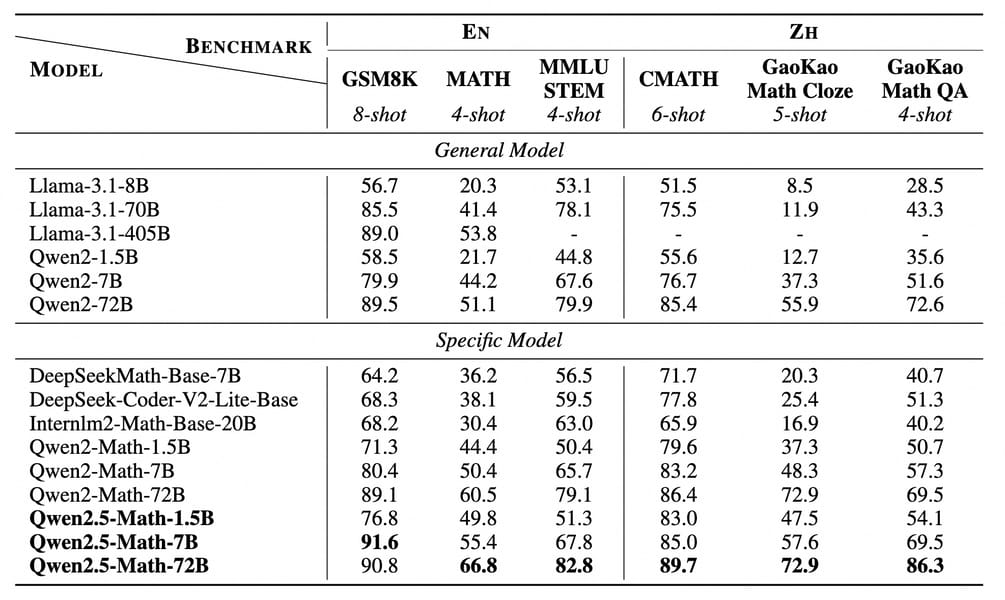
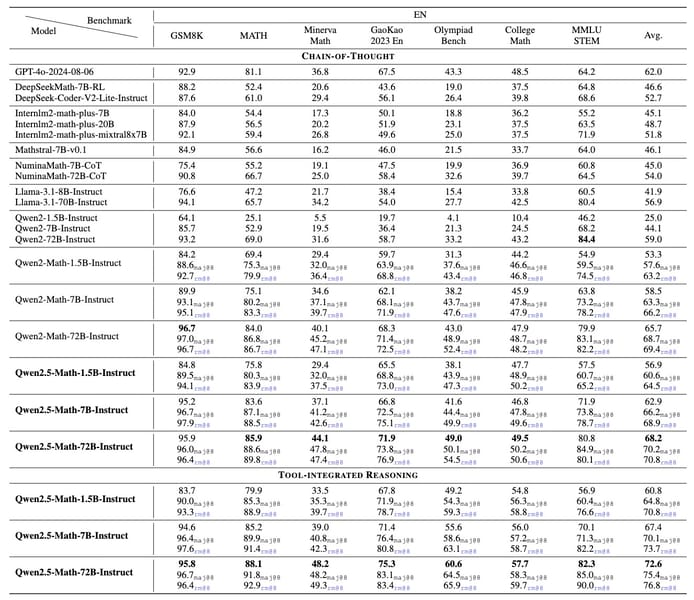
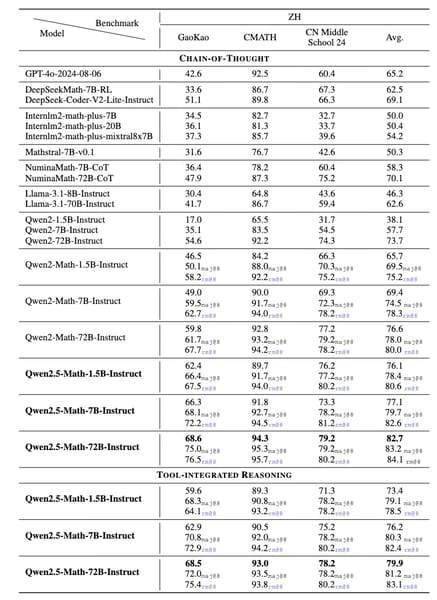
Qwen2.5-Math-7B demonstrates improved performance over earlier iterations across multiple benchmarks in both English and Chinese. The model’s performance has been assessed using datasets such as GSM8K, MATH, MMLU STEM, CMATH, and GaoKao Math QA. In CoT settings, Qwen2.5-Math-7B shows increased performance, outperforming its Qwen2-Math-7B predecessor by 5.0 points on MATH and by 12.2 points on Chinese high school math QA.
Instruction-tuned Qwen2.5-Math-Instruct variants have been evaluated on problems from OlympiadBench, AIME 2024, and AMC 2023. The 7B Instruct model registered MATH benchmark scores of 83.6 (CoT) and 85.3 (TIR). The 72B model, Qwen2.5-Math-72B-Instruct, reached a score of 92.9 on MATH (TIR RM@8), demonstrating performance comparable to or exceeding that of several closed-source models.
Comparison of MATH accuracy by model size, with Qwen2.5-Math models noted for their performance-to-size ratio.
Chinese-language benchmarks also reflect favorable results, with Qwen2.5-Math-7B demonstrating high accuracy across GaoKao, CMATH, and CN Middle School 24 tasks.
When presented with competition benchmarks such as AIME 2024 and AMC 2023, the Qwen2.5-Math-Instruct model demonstrates effective problem-solving capabilities when applied to competition benchmarks such as AIME 2024 and AMC 2023.
Performance of instruction-tuned Qwen2.5-Math-Instruct models on English mathematical benchmarks.
Qwen2.5-Math-7B incorporates roughly 7.62 billion parameters and uses bfloat16 (BF16) tensor types for efficient computation. The base model, Qwen/Qwen2.5-7B, is offered alongside an instruction-tuned version designed for dialogue-based tutoring and interactive use. The Qwen2.5-Math series was publicly released in September 2024, following the initial launch of Qwen2-Math in August 2024, and is distributed openly for research and development.
The series also includes a 72B-parameter reward model (Qwen2.5-Math-RM-72B), employed for supervised data selection and reinforcement learning via Group Relative Policy Optimization (GRPO).
Limitations and Decontamination
Qwen2.5-Math-7B is specialized for mathematical reasoning in English and Chinese using chain-of-thought and tool-integrated approaches. Its application to general text tasks beyond mathematics is not recommended. While CoT enhances stepwise reasoning, it remains limited in direct computation and some algorithmic scenarios, which TIR partially addresses.
To ensure the integrity of performance benchmarks, comprehensive decontamination procedures were implemented throughout the data pipeline. Potentially overlapping training and test samples were identified and excluded using 13-gram matching and longest common subsequence ratios, reducing bias especially for benchmarks like GSM8K, MATH, Minerva Math, Olympiad Bench, and national mathematics exams. Specialized filtering was also conducted for post-training and supervised datasets, excluding not only matched sample problems but also problems with similar concepts.
References and Further Reading
For further technical details, model code, benchmarks, and demonstration environments, consult the following resources:
For citation, please refer to the official publication:
Yang, A. et al., "Qwen2.5-Math Technical Report: Toward Mathematical Expert Model via Self-Improvement", arXiv preprint arXiv:2409.12122 (2024).