Launch a dedicated cloud GPU server running Laboratory OS to download and run Qwen 2.5 Math 72B using any compatible app or framework.
Direct Download
Must be used with a compatible app, notebook, or codebase. May run slowly, or not work at all, depending on local system resources, particularly GPU(s) and available VRAM.
Open WebUI is an open-source, self-hosted web interface with a polished, ChatGPT-like user experience for interacting with LLMs. Integrates seamlessly with local Ollama installation.
The most full-featured web interface for experimenting with open source Large Language Models. Featuring a wide range of configurable settings, inference engines, and plugins.
Model Report
Alibaba Cloud / Qwen 2.5 Math 72B
Qwen 2.5 Math 72B is a specialized large language model developed by Alibaba Cloud with 72.7 billion parameters, designed for solving advanced mathematical problems in English and Chinese. The model incorporates chain-of-thought reasoning and tool-integrated reasoning capabilities, enabling step-by-step problem solving and code execution for complex mathematical tasks, and demonstrates performance improvements over previous versions on standardized mathematical benchmarks.
Explore the Future of AI
Your server, your data, under your control
Qwen 2.5 Math 72B is a specialized large language model (LLM) designed for solving advanced mathematical problems in both English and Chinese. Developed by the Qwen Team at Alibaba Group, it is an evolution of the Qwen mathematical model family, developed from the foundations established by the earlier Qwen2-Math series. Officially released in September 2024, Qwen 2.5 Math 72B includes enhancements in reasoning, multilingual support, and mathematical accuracy, developed to advance automated mathematical problem-solving and research. The model is an open-weight release and is accompanied by resources for evaluation and application.
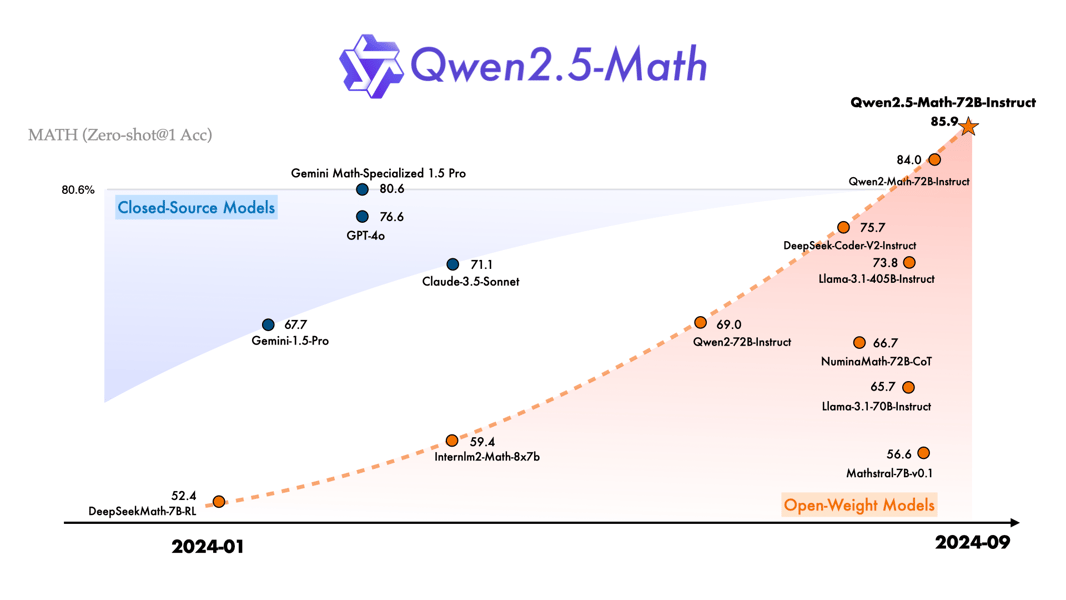
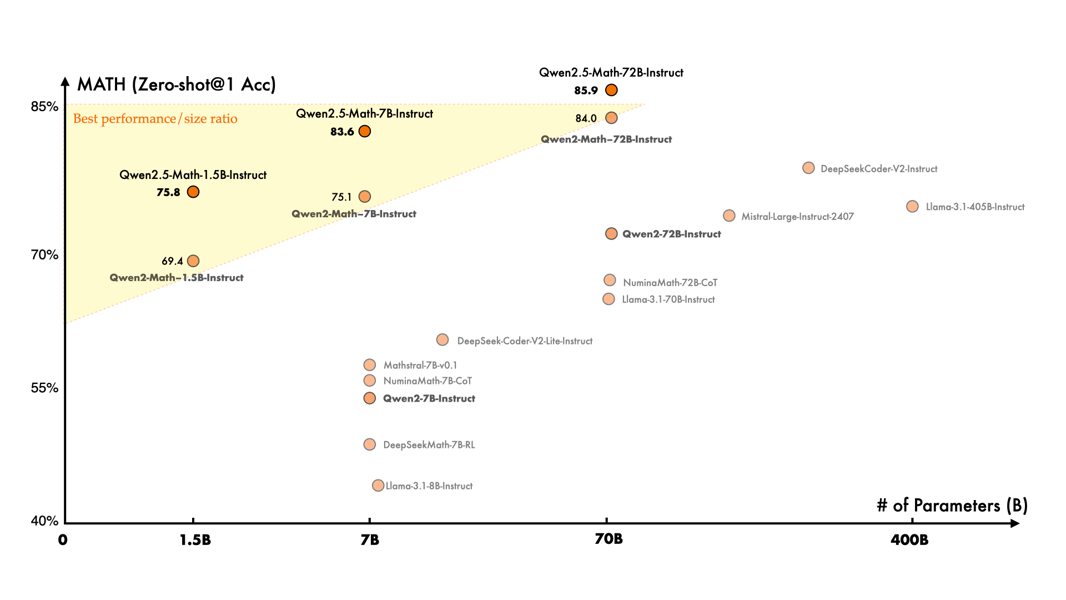
Qwen2.5-Math-72B-Instruct demonstrates a high level of mathematical accuracy compared to other models as of September 2024.
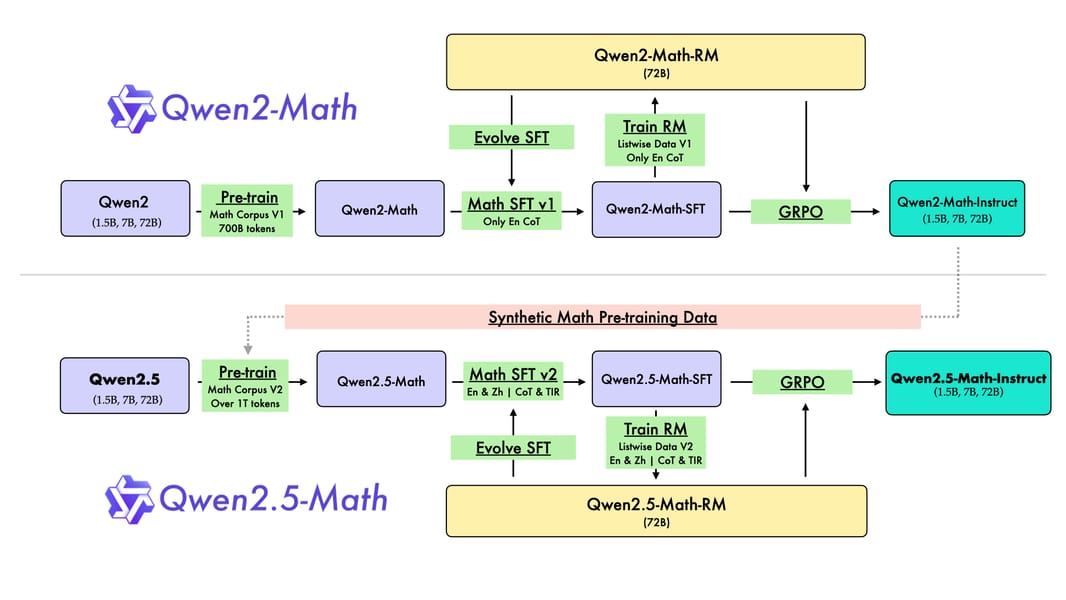
Qwen 2.5 Math 72B builds upon the Qwen2.5 series architecture, utilizing parameter initialization and model refinement techniques that distinguish it from its predecessors. With 72.7 billion parameters using the BF16 tensor format, it is among the largest in the Qwen2.5-Math series. The upgrade process is characterized by three main strategies: synthesizing mathematical training data using prior model generations, aggregating additional mathematical corpora (especially in Chinese), and leveraging the base capabilities of the Qwen2.5 series for language understanding, code synthesis, and symbolic reasoning.
A comprehensive multi-stage pipeline guides the specialization of Qwen2.5-Math, including pre-training, supervised fine-tuning (SFT), reward model training, and reinforcement learning. The introduction of chain-of-thought (CoT) and tool-integrated reasoning (TIR) methods supports its ability to tackle complex symbolic and algorithmic tasks.
The specialization pipeline for Qwen2.5-Math includes iterative data refinement, instructional fine-tuning, and reinforcement learning for mathematical reasoning.
Qwen 2.5 Math 72B is optimized for solving mathematical problems, supporting both English and Chinese language inputs. Qwen2.5-Math supports both English and Chinese, processing mathematical content relevant to each linguistic context, unlike prior Qwen2-Math models which were limited to English.
The model incorporates reasoning capabilities. Chain-of-thought (CoT) prompting enables step-by-step logical reasoning, while tool-integrated reasoning (TIR) incorporates external computation and code execution (such as Python) within the model output for precision on complex tasks. TIR is particularly effective for problems requiring symbolic manipulation or algorithmic procedures, such as solving equations or finding matrix eigenvalues.
Self-improvement mechanisms, such as iterative data synthesis and reinforcement training guided by a dedicated reward model, support performance enhancements. Qwen2.5-Math also features multimodal mathematical reasoning through integration with models from the Qwen2.5-VL series for optical character recognition (OCR), enabling the processing of mathematical problems from images, sketches, or dense text.
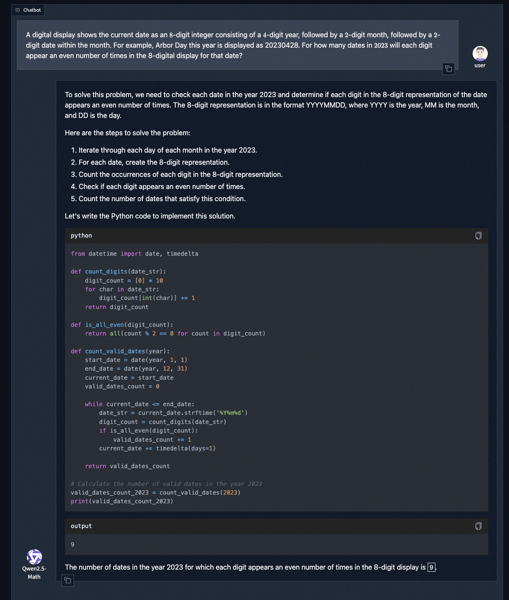
A demonstration of Qwen2.5-Math's Tool-Integrated Reasoning (TIR): the model provides a solution plan, Python code, and code output for a mathematical problem.
The development of Qwen 2.5 Math 72B leveraged an expanded and curated pre-training corpus, with the Qwen Math Corpus v2 providing over one trillion tokens in both English and Chinese. This represents an augmentation compared to previous iterations, and the dataset maintains a context length of 4,000 tokens to support reasoning over extended problem statements.
During supervised fine-tuning, a math-specific reward model (Qwen2.5-Math-RM-72B) is trained to construct SFT data using rejection sampling. The Group Relative Policy Optimization (GRPO) approach is subsequently employed to further align model outputs with optimal solution strategies.
Decontamination protocols are applied throughout: 13-gram matching with text normalization ensures exclusion of potentially leaked or excessively similar examples from training, especially with respect to common mathematical benchmarks such as GSM8K, MATH, Minerva Math, CMATH, Olympiad Bench, and high-stakes exams including GaoKao, AIME, and AMC. This filtering contributes to the integrity of model evaluation and mitigates inadvertent memorization of test content.
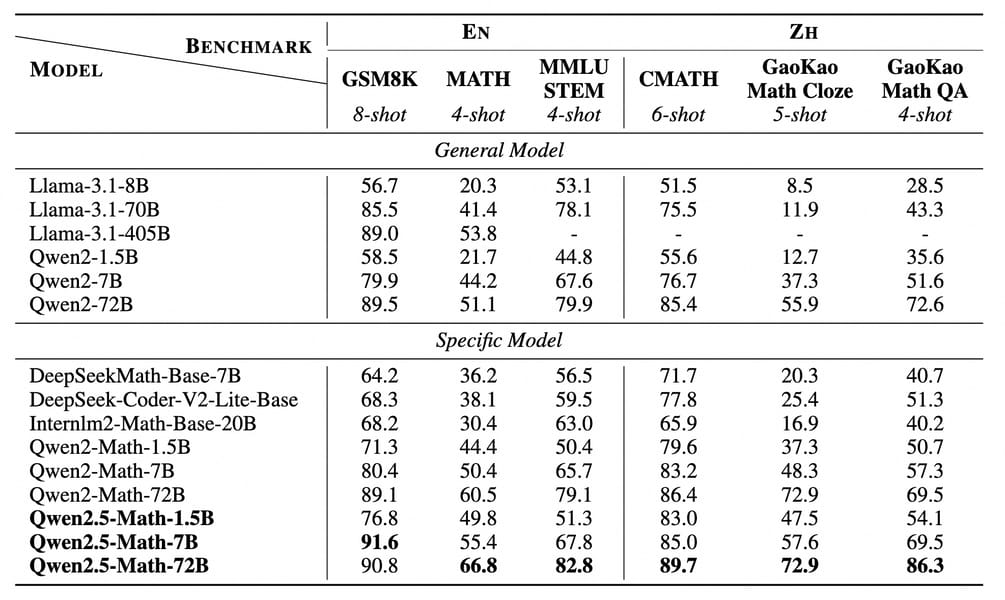
Qwen2.5-Math base models demonstrate notable performance on both English and Chinese mathematical benchmarks.
Qwen 2.5 Math 72B shows gains on a range of standardized mathematical evaluation sets, and is evaluated among other bilingual mathematical models. Evaluation covers both base models (using few-shot CoT prompting) and instruction-tuned models (using zero-shot or few-shot protocols). Benchmarks include GSM8K, MATH, MMLU STEM (English), and CMATH, GaoKao Math Cloze, and Gaokao Math QA (Chinese), as well as competitions such as OlympiadBench, College Math, AIME 2024, and AMC 2023.
Results show improvements over the Qwen2-Math series:
On the MATH (English) benchmark, Qwen2.5-Math-72B outperforms its predecessor by over 6 percentage points, achieving high accuracy in both chain-of-thought and tool-integrated reasoning settings.
In the TIR mode, the model attains a score of 92.9 on the MATH dataset and achieves a high score on AMC 2023.
On AIME 2024, the model solves up to 12 problems with TIR, compared to 1–2 for some closed-source models.
Qwen2.5-Math-Instruct solves more AIME 2024 and AMC 2023 problems than prior mathematical LLMs using TIR and CoT reasoning.
Qwen 2.5 Math 72B is intended primarily for mathematical tasks, and uses both chain-of-thought and tool-integrated reasoning strategies. The model supports queries in both English and Chinese and is not recommended for general language tasks outside mathematics.
A demonstration of its TIR capabilities shows its integration with code execution for mathematical reasoning, where the model provides solution plans, generates code (such as Python), and presents the output. Multimodal mathematical demos also show its ability to work with images or formulas captured from physical sources.
Some limitations remain. The model is intentionally restricted to mathematical domains, and the team notes that due to overlaps in public problem databases, even with data decontamination, some conceptual similarities may persist between training and evaluation datasets. The model documentation emphasizes maintaining filtering protocols and transparency regarding benchmarking methodologies.
Licensing and Availability
Qwen 2.5 Math 72B is released as an open-weight model, for research, benchmarking, and community exploration. License details are made available in its official repositories, and associated resources include reward models, evaluation scripts, and demonstration platforms for further experimentation.