Note: Qwen2.5 VL 72B weights are released under a Qwen Research License, and cannot be utilized for commercial purposes. Please read the license to verify if your use case is permitted.
Laboratory OS
Launch a dedicated cloud GPU server running Laboratory OS to download and run Qwen2.5 VL 72B using any compatible app or framework.
Direct Download
Must be used with a compatible app, notebook, or codebase. May run slowly, or not work at all, depending on local system resources, particularly GPU(s) and available VRAM.
Open WebUI is an open-source, self-hosted web interface with a polished, ChatGPT-like user experience for interacting with LLMs. Integrates seamlessly with local Ollama installation.
The most full-featured web interface for experimenting with open source Large Language Models. Featuring a wide range of configurable settings, inference engines, and plugins.
Model Report
Alibaba Cloud / Qwen2.5 VL 72B
Qwen2.5-VL 72B is a 72-billion parameter multimodal generative AI model developed by Alibaba Cloud that integrates vision and language understanding. The model features dynamic resolution processing, temporal video alignment, and architectural enhancements over previous Qwen2-VL versions. It performs object detection, document parsing, video comprehension, OCR across multiple languages, and functions as a visual agent for interactive tasks, trained on over 1.4 trillion tokens.
Explore the Future of AI
Your server, your data, under your control
Qwen2.5-VL 72B is a configuration within the Qwen2.5-VL family, a suite of large multimodal generative AI models developed by the Qwen team at Alibaba Cloud. Released in early 2025, Qwen2.5-VL unifies vision and language understanding. Its capabilities include image and video comprehension, document parsing, object grounding, structured data extraction, and visual-agent interactions, as detailed in the Qwen2.5-VL Technical Report and on the Qwen2.5 VL Blog. Containing 72 billion parameters, the Qwen2.5-VL-72B-Instruct functions as a configuration for multimodal tasks, succeeding the earlier Qwen2-VL models and introducing architectural, training, and functional enhancements.
Banner for Qwen2.5-VL illustrating the model’s launch.
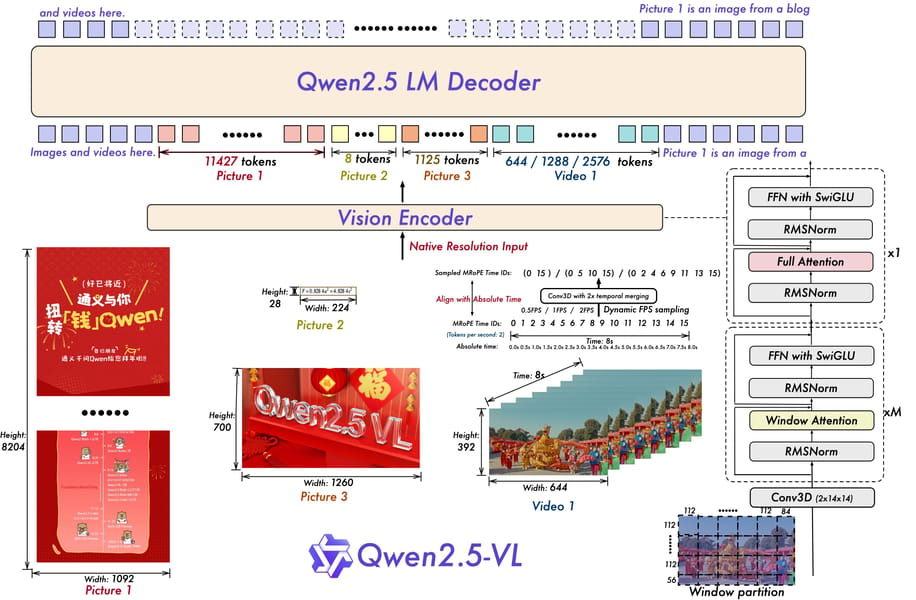
Qwen2.5-VL 72B is built upon a unified architecture that integrates a large language model from the Qwen2 series with a vision encoder, enabling comprehensive visual-language reasoning. Key architectural features include:
Dynamic Resolution Processing: The vision encoder adopts a native vision transformer (ViT) optimized for dynamic resolutions. Images and videos of differing spatial and temporal dimensions are tokenized according to actual scale, accommodating variable input sizes without conventional normalization, as described in the Qwen2.5-VL Technical Report.
Temporal and Spatial Alignment: Videos are sampled at dynamically adjustable frame rates; absolute time encoding aligns multimodal rotary position embeddings (mRoPE) with real video durations, improving event localization and summarization in long-form video analysis, as presented in the Qwen2.5-VL Technical Report.
Efficient Attention Mechanisms: The vision encoder structure strategically combines full attention layers with windowed attention for efficient computation, further stabilized by RMSNorm and SwiGLU techniques to harmonize architectural consistency with the Qwen2 LLM, according to the Qwen2.5 VL Blog.
Schematic of Qwen2.5-VL’s video understanding pipeline and modular network design.
Structured Output and Grounding: The model supports outputting bounding boxes, points, and structured JSON data for detected objects, which is for tasks such as precise object localization and form data extraction.
Training Methodology and Datasets
The training of Qwen2.5-VL employs a three-phase approach, optimizing each component for multimodal understanding, as detailed in the Qwen2.5-VL Technical Report:
Stage 1: The ViT encoder is pre-trained with image-text pairs, focusing on image classification, OCR, and semantic alignment. Initial weights are adapted from large vision models but use rotary 2D positional embeddings.
Stage 2: Multimodal joint training unfreezes all network parameters, introducing diverse data including visual question answering, multitask datasets, and continued text-only learning for language robustness.
Stage 3: Parameters for the vision encoder are frozen, while the LLM undergoes instruction fine-tuning using conversational, document, video, and agent-based datasets in the ChatML format.
The curriculum exposes Qwen2.5-VL to over 1.4 trillion tokens, blending textual and visual data. Specialized agent datasets enable the model to reason through UI operations and decision-making tasks, while OCR and document parsing data ensure reliable recognition under varied orientations and languages.
Technical Capabilities
Qwen2.5-VL 72B’s capabilities extend across multiple modalities and tasks, including:
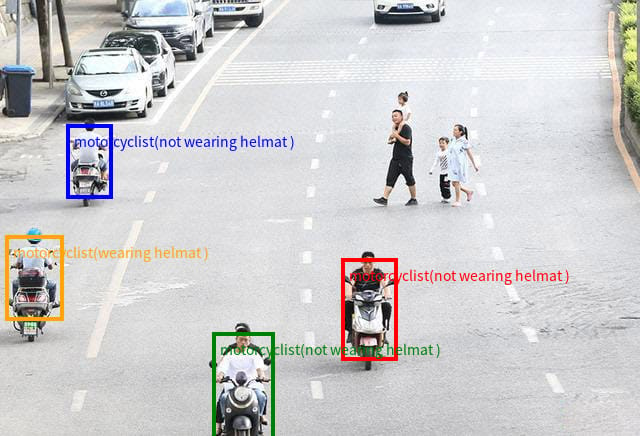
Object Detection and Grounding: The model provides object localization with bounding boxes and labels, supporting hierarchical grounding for complex scenes.
Output showing detection and helmet classification among motorcyclists.
Robust Object Counting and Classification: The model accurately counts and identifies multiple instances, including partially occluded objects, as demonstrated in benchmarks and practical outputs.
Benchmark comparison between compact Qwen2.5-VL models and peers.
Model interacts as a computer agent to find specific weather data. [Source]
Multiple cupcakes grounded and described with bounding boxes, demonstrating attribute extraction. Prompt: enumerate coordinates and features of all cupcakes.
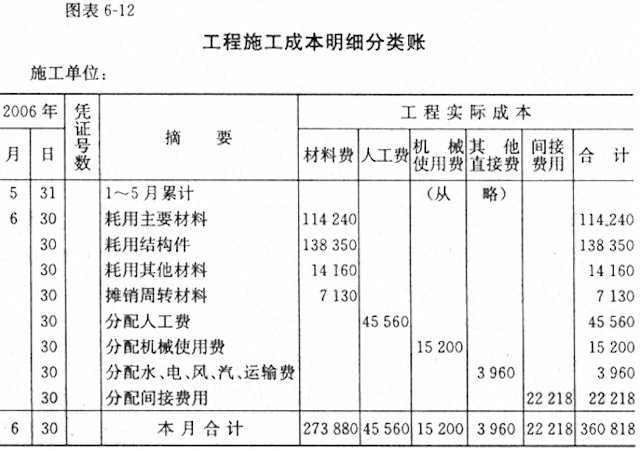
Document Understanding and OCR: Upgraded OCR enables precise, multilingual, and multi-orientation recognition in complex documents, such as scanned receipts and structured ledgers.
Parsing a technical report and outputting HTML-like layout, demonstrating structured textual and graphic extraction.
Video Comprehension: Qwen2.5-VL can process and summarize long-form videos, identify events at second-level granularity, and output structured descriptions for video segments.
Demonstration of extracting paper titles from video, showcasing information extraction over time. [Source]Video reasoning: the model summarizes and analyzes an object (lion dance prop) in video. [Source]Structured video captioning with activity timelines and JSON outputs. [Source]
Agentic and Interactive Abilities: The model can operate as a visual agent for dynamic reasoning and tool manipulation in computer and mobile environments.
Mobile agent books a ticket in-app following user guidance. [Source]Image editing software operated by model as a computer agent. [Source]
Benchmark Evaluation
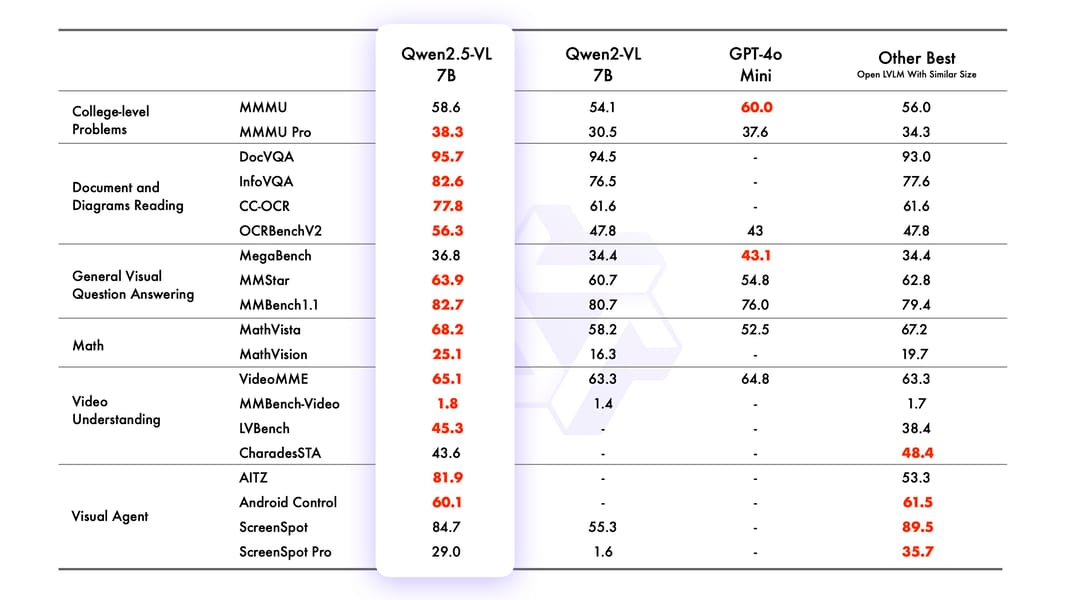
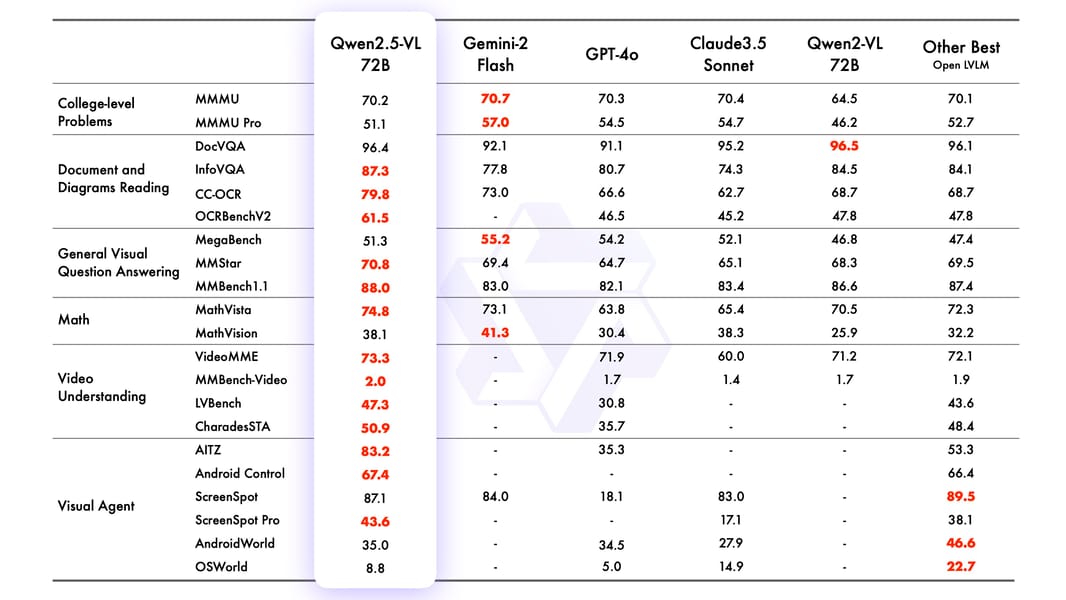
Qwen2.5-VL-72B-Instruct delivers strong performance on established benchmarks spanning math, science, document understanding, object recognition, and video analysis, as reported in the official technical report and model documentation.
Comparative benchmark scores of Qwen2.5-VL-72B versus other vision-language models on diverse tasks.
The model demonstrates noteworthy results for document parsing, general visual question answering, multilingual OCR, and agent benchmarks. Evaluations indicate robust video reasoning and generalization to multiple languages and domains. Performance on challenging complex-problem sets, such as MMMU, remains a focus for future improvement.
Applications and Use Cases
Qwen2.5-VL 72B addresses a set of practical demands:
Document Analysis: Extracts, parses, and structures data from invoices, receipts, forms, and technical diagrams, supporting business and financial workflows.
Visual Question Answering: Answers queries about images and videos, recognizes and localizes objects, and responds to prompts integrating both textual and visual clues.
Multilingual OCR: Processes texts embedded in images across major Asian and European languages under various orientations.
Video Summarization: Understands lengthy video footage, locating and describing key events at a fine temporal resolution.
Visual Agents: Functions as a digital agent for computer or phone operations, automating UI tasks, application management, and tool use in interactive settings.
Limitations and Model Family
While Qwen2.5-VL-72B offers multimodal capabilities, there are documented limitations. The model’s performance can be affected by out-of-distribution small images in OCR tasks, and its handling of extended text inputs beyond default context limits may reduce temporal or spatial localization fidelity, as noted in the Qwen2.5-VL Technical Report. Video URL compatibility is also subject to backend library constraints.
Within the Qwen2.5-VL family, smaller variants such as Qwen2.5-VL 3B and Qwen2.5-VL 7B provide resource-efficient options. Comparisons to the precursor Qwen2-VL series and experimental models such as QvQ-72B-Preview show ongoing development in visual reasoning and fine-grained multimodal alignment, as reported on the Qwen2.5-VL GitHub.
Release, Licensing, and Resources
Qwen2.5-VL was announced on January 26, 2025, with technical reports, quantized models, and open-source materials following in subsequent months, according to the Qwen2.5 VL blog. The series is released under the Apache-2.0 license, suitable for research, development, and further innovation in vision-language AI.