Note: Qwen2.5 VL 7B weights are released under a Qwen Research License, and cannot be utilized for commercial purposes. Please read the license to verify if your use case is permitted.
Laboratory OS
Launch a dedicated cloud GPU server running Laboratory OS to download and run Qwen2.5 VL 7B using any compatible app or framework.
Direct Download
Must be used with a compatible app, notebook, or codebase. May run slowly, or not work at all, depending on local system resources, particularly GPU(s) and available VRAM.
Open WebUI is an open-source, self-hosted web interface with a polished, ChatGPT-like user experience for interacting with LLMs. Integrates seamlessly with local Ollama installation.
The most full-featured web interface for experimenting with open source Large Language Models. Featuring a wide range of configurable settings, inference engines, and plugins.
Model Report
Alibaba Cloud / Qwen2.5 VL 7B
Qwen2.5 VL 7B is a 7-billion parameter multimodal language model developed by Alibaba Cloud that processes text, images, and video inputs. The model features a Vision Transformer with dynamic resolution support and Multimodal Rotary Position Embedding for spatial-temporal understanding. It demonstrates capabilities in document analysis, OCR, object detection, video comprehension, and structured output generation across multiple languages, released under Apache-2.0 license.
Explore the Future of AI
Your server, your data, under your control
Qwen2.5 VL 7B is a multimodal large language model developed by the Qwen team at Alibaba Cloud, belonging to the broader Qwen2.5-VL model family. Released in early 2025, this 7-billion parameter model is designed to bridge language and vision, delivering diverse capabilities in image, document, and video comprehension, text recognition, information extraction, and visual reasoning. It incorporates architectural features that enable comprehensive understanding and structured output, building upon its predecessor, Qwen2-VL. The following article provides a detailed technical and scientific overview of its architecture, training methodology, performance, and primary use cases as supported in the official technical report, model documentation, and release notes.
Banner for the Qwen2.5-VL series, representing the model's launch.
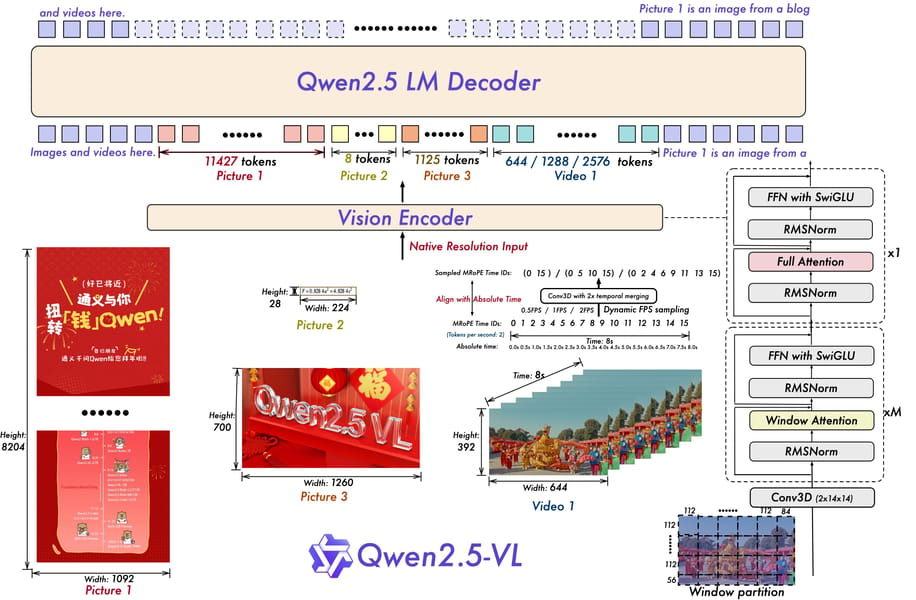
Qwen2.5 VL 7B employs a unified multimodal architecture, supporting integration of textual, visual, and video inputs. At its core, the model features a Vision Transformer (ViT) trained with native dynamic resolution support. This design enables the model to process images of varying dimensions efficiently, avoid information loss due to forced resizing, and learn fine-grained spatial details directly from raw inputs. The visual encoder’s structure closely aligns with large language models (LLMs), utilizing RMSNorm and SwiGLU activation mechanisms for consistency across modalities.
A notable architectural feature is the implementation of Multimodal Rotary Position Embedding (M-RoPE), which facilitates explicit modeling of temporal and spatial positions by decomposing rotary position encoding into time and 2D spatial axes. This enables more accurate localization in both images and videos. For video understanding, the model employs mixed training on static images and sampled video frames, with 3D convolution modules incorporated to capture temporal dynamics and event structure. The visual backbone’s windowed attention mechanism is used throughout most layers, reducing computational overhead while maintaining native resolution input.
Qwen2.5-VL architecture diagram, illustrating unified image and video input processing, tokenization, and internal backbone innovations.
Qwen2.5 VL 7B is trained via a three-stage pipeline, harnessing a diverse mix of data modalities. The initial stage involves the isolated training of the ViT on large-scale image-text pairs to cultivate semantic alignment between visual and linguistic spaces. Subsequently, all parameters are unfrozen in a comprehensive training stage that incorporates up to 1.4 trillion tokens (details in technical report), with extensive datasets covering textual documents, interleaved image-text articles, visual question answering, structured forms, and multi-language OCR. The final instruction-tuning phase further specializes the LLM via annotated conversations in ChatML format, enabling responses to tasks such as document parsing, multi-image comparison, and video stream dialogue.
To ensure high performance and training efficiency, the infrastructure relies on distributed parallelism and memory optimization techniques, leveraging 3D parallelism, DeepSpeed’s ZeRO optimizer, Flash-Attention kernels, and staged checkpointing across storage solutions such as Alibaba Cloud’s CPFS and OSS. The model is pre-trained on a combination of cleaned web data, open datasets, and synthetic samples, with its knowledge cutoff in June 2023.
Capabilities: Visual, Document, and Video Understanding
Qwen2.5 VL 7B exhibits a broad set of capabilities across modalities, with particular strengths in structured document analysis, object detection, and video event localization.
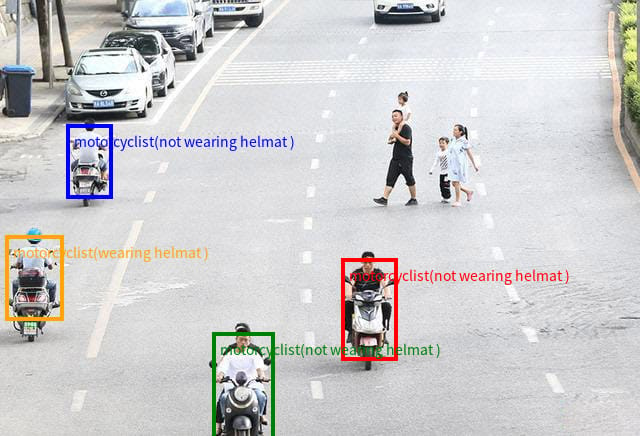
For visual understanding, the model can accurately detect and localize multiple objects, identify their attributes, and output results in structured, machine-readable formats.
Model output for "Detect all the motorcyclists with coordinates and indicate whether a helmet is being worn".
The model provides text recognition and information extraction capabilities, supporting multi-language OCR and key-value data extraction from complex backgrounds such as receipts, financial statements, invoices, and delivery bills.
Line-level OCR result: recognized text regions detected with bounding boxes in a retail receipt.
For document and layout analysis, Qwen2.5 VL 7B uses the QwenVL HTML format to reconstruct hierarchical structure for complex sources such as academic papers, magazines, and mobile screenshots.
Example output showing Qwen2.5-VL's automatic HTML parsing of scientific documents for downstream applications.
In video, the model can perform long-context comprehension, temporal event detection, summarization, and reasoning over hour-long footage, using both spatial and temporal cues.
Demonstration of extracting structured paper titles from a video and compiling them into a table. [Source]Video reasoning example: Detailed object analysis of a traditional Chinese lion dance prop as prompted by the user. [Source]Structured event localization and captioning in video: JSON output of detected activity segments with start/end timestamps and descriptions. [Source]
Performance Benchmarks
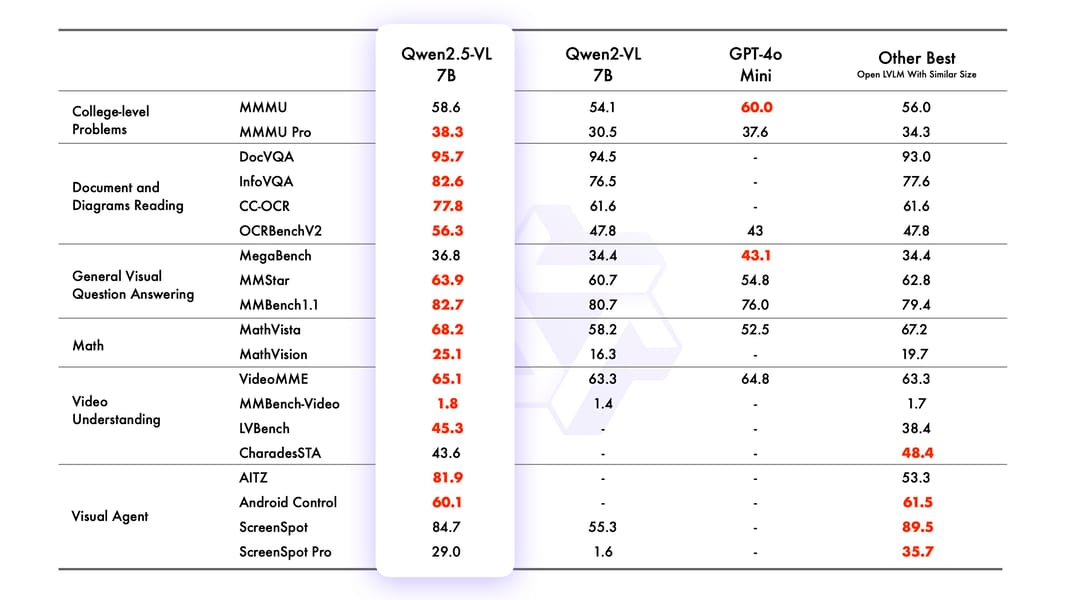
Qwen2.5 VL 7B-Instruct demonstrates competitive results across a wide spectrum of multimodal benchmarks. On document and diagram understanding tasks, it achieves accuracy in DocVQA and InfoVQA, and performs well on ChartQA and general visual question answering tasks. In video benchmarks, the model performs robustly on MVBench, PerceptionTest, and Video-MME. For agentic capabilities, Qwen2.5 VL 7B demonstrates reliable UI operation and screen navigation (as measured by ScreenSpot and related tasks).
Quantitative results: Qwen2.5-VL 7B's benchmark scores compared to Qwen2-VL 7B, GPT-4o Mini, and peer models across a range of multimodal tasks.
The model exhibits multilingual OCR capacity, surpassing prior open-source LVLMs on most languages except Arabic (arXiv technical report). Its use of M-RoPE enables context length extrapolation, supporting inference up to 80K input tokens, with consistent performance for varying image sizes and resolutions.
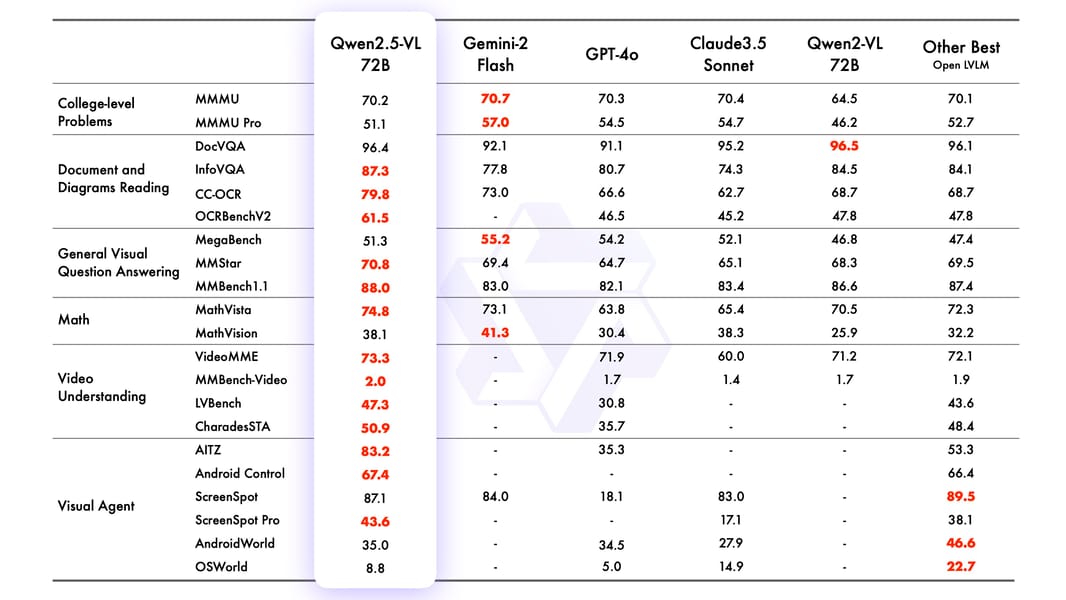
Performance overview: Qwen2.5-VL-72B and selected models on major multimodal leaderboards. The 7B variant achieves competitive relative scores.
The model supports a range of scientific, commercial, and industrial applications. In financial services, it parses invoices and structured tables, producing machine-readable outputs that can be used for automation. In digitalization, it performs information extraction from legal, logistics, and qualification documents. Its agentic capabilities allow it to interact with virtual environments, acting as a visual agent for UI manipulation, robotic task execution, and digital assistance.
Another primary use case is multimedia analysis, including reasoning over long videos, structuring event timelines, and extracting salient information for downstream automation or content management tasks.
Limitations
While Qwen2.5 VL 7B achieves high accuracy on most tasks, there remain open challenges in certain benchmark areas. The model underperforms on complex math and challenging college-level problems relative to much larger models or systems specialized for such reasoning. For Arabic OCR, performance trails that of some closed-source systems. Tasks requiring advanced mapping and 3D navigation, such as Vision-Language Navigation (VLN), reveal limitations in spatial modeling and the accurate construction of structured maps from fragmented input images. The model’s inference pipeline currently supports only local video files for analysis, with web-based video support depending on the stability of third-party libraries.
Licensing and Availability
Qwen2.5 VL 7B is openly available under the Apache-2.0 license for research and development, promoting transparency and collaborative scientific progress.