Note: Qwen2.5 VL 3B weights are released under a Qwen Research License, and cannot be utilized for commercial purposes. Please read the license to verify if your use case is permitted.
Laboratory OS
Launch a dedicated cloud GPU server running Laboratory OS to download and run Qwen2.5 VL 3B using any compatible app or framework.
Direct Download
Must be used with a compatible app, notebook, or codebase. May run slowly, or not work at all, depending on local system resources, particularly GPU(s) and available VRAM.
Open WebUI is an open-source, self-hosted web interface with a polished, ChatGPT-like user experience for interacting with LLMs. Integrates seamlessly with local Ollama installation.
The most full-featured web interface for experimenting with open source Large Language Models. Featuring a wide range of configurable settings, inference engines, and plugins.
Model Report
Alibaba Cloud / Qwen2.5 VL 3B
Qwen2.5-VL-3B-Instruct is a multimodal large language model developed by Alibaba Cloud featuring 3 billion parameters. The model combines a Vision Transformer encoder with a Qwen2.5-series decoder to process images, videos, and text through dynamic resolution handling and temporal processing capabilities. It supports object detection, OCR, document analysis, video understanding, and computer interface automation, trained on approximately 1.4 trillion tokens across multiple modalities and released under Apache-2.0 license.
Explore the Future of AI
Your server, your data, under your control
Qwen2.5-VL-3B-Instruct is a multimodal, instruction-tuned large language model developed by the Qwen team at Alibaba Cloud. As part of the Qwen2.5-VL series, which includes larger 7B and 72B parameter variants, the 3B model is designed for efficient, on-device deployment while maintaining capabilities in image, video, and multimodal understanding. Released in January 2025, Qwen2.5-VL-3B-Instruct includes architectural and functional refinements over its predecessor, Qwen2-VL, particularly in visual comprehension, agentic behavior, and temporal processing for long videos, with further developments described in the Qwen2.5-VL technical report.
Qwen2.5-VL-3B processes and describes scenes involving people, animals, and diverse objects, supporting detailed multimodal understanding.
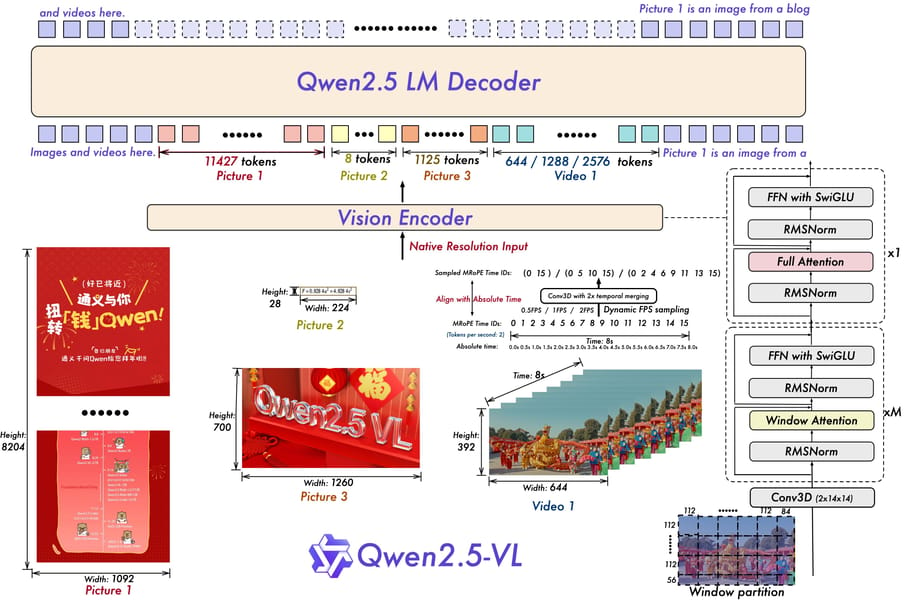
Qwen2.5-VL-3B-Instruct employs a multi-stage training strategy and incorporates several architectural elements. The core of the system integrates a Vision Transformer (ViT) encoder with a Qwen2.5-series large language model decoder, connected via cross-modal layers. The ViT architecture incorporates window attention for efficiency, with four of its layers utilizing full attention and the remainder operating in windowed mode for computational scalability. The model natively supports dynamic resolution inputs for both image and video data, enabling it to process media in their original aspect ratios for spatial sensitivity.
A critical innovation is the extension of dynamic resolution into the temporal dimension for video understanding. Qwen2.5-VL-3B samples video frames at dynamic rates and applies Multimodal Rotary Position Embedding (mRoPE) with absolute time alignment, allowing it to discern and reason over long video sequences and accurately localize events.
Technical diagram of the Qwen2.5-VL model, showing the interaction between the vision encoder, dynamic resolution handling, and temporal processing for images and videos.
Additionally, the model is configured for native box and point representation: it can directly output bounding box coordinates and keypoints in the context of the original image frame, bypassing traditional normalization techniques and contributing to fidelity in object localization.
Technical Capabilities
The 3B-Instruct variant provides multimodal reasoning across images, documents, and video streams. It demonstrates performance in object recognition, chart analysis, layout understanding, and text extraction, including optical character recognition (OCR) for multilingual and multi-orientational scenarios.
Bird counting demonstration: Qwen2.5-VL-3B detects and counts all birds in the image, including partially visible ones.
In video-related tasks, the model performs event detection, segment localization, and structured captioning, supporting variable resolution and video length.
Demonstrating Qwen2.5-VL-3B's video reasoning capabilities by providing detailed object analysis and information extraction from video frames. [Source]
The model’s agentic features allow it to interact with computer and mobile interfaces by interpreting user interfaces and executing actions in applications—including document editing, image manipulation, and task automation.
Computer agent demonstration: Qwen2.5-VL-3B performs photo editing tasks in a desktop application based on user instructions. [Source]
Performance and Evaluation
Qwen2.5-VL-3B-Instruct has been evaluated against established vision-language benchmarks. Results from evaluations against established vision-language benchmarks indicate its performance in comparison to larger models in its class and similarly efficient open models. On tasks such as multi-modal reasoning (MMMU), chart and diagram interpretation (DocVQA), visual question answering (AI2D, InfoVQA, TextVQA), mathematics (MathVista, MathVision), and video reasoning (VideoMME, MVBench), the 3B model's reported scores are comparable to those of some higher-parameter open models.
Model banner for the Qwen2.5-VL series, highlighting its multimodal focus.
The model's structured output capabilities enable extraction of information from invoices, forms, and receipts, and its QwenVL HTML format provides detailed document layout extraction, supporting downstream applications in finance, logistics, and commercial documentation.
Training Data and Methodology
Training of Qwen2.5-VL-3B-Instruct follows a three-stage process. Initially, the vision encoder is trained independently on a corpus of image-text pairs to establish foundational multimodal representations. In the subsequent stage, all model parameters are unfrozen and are further pre-trained on a broader dataset incorporating images, OCR, document formats, and visual question answering (VQA) data. The final stage involves locking the visual encoder weights and fine-tuning the language model on curated instruction datasets formatted in ChatML, encompassing both text and multimodal conversational data.
Pretraining leverages approximately 1.4 trillion tokens, including image, video, and text modalities. The data is composed of cleaned web data, curated open-source datasets, and synthetic sources, with a knowledge cutoff in June 2023. During fine-tuning, datasets span standard dialog, multi-image comparison, document parsing, video comprehension, and agent interaction.
Typical Applications
Qwen2.5-VL-3B-Instruct is suited for a range of applications requiring fine-grained visual analysis, document and chart parsing, information extraction from receipts or invoices, object counting, keypoint detection, and temporal localization within video. It supports accessibility solutions, process automation in mobile and desktop environments, multimedia content moderation, and educational applications that rely on multimodal understanding.
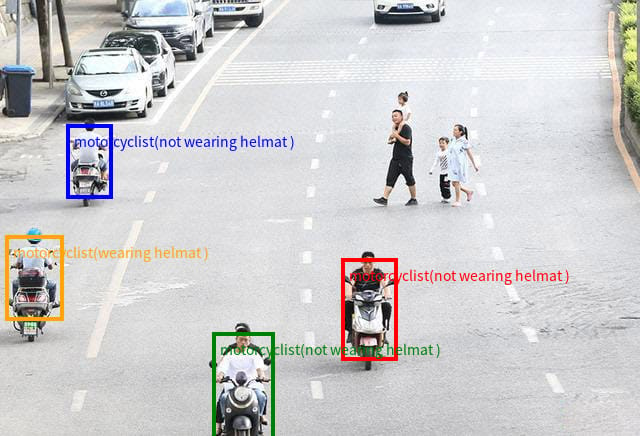
Demonstrating precise object grounding: the model localizes multiple motorcyclists, indicating helmet usage with bounding boxes.
Mobile agent example: Qwen2.5-VL-3B assists in booking a ticket in a mobile application by interpreting UI elements and automating input. [Source]Structured video captioning: the model identifies and describes segmented activity events with precise timestamps. [Source]
Limitations and Licensing
While Qwen2.5-VL-3B-Instruct processes context up to 32,768 tokens by default, certain extensions to context length (such as YaRN) may negatively impact the spatial or temporal precision required for some tasks. Careful parameter configuration is necessary in these cases, particularly when performing OCR on small images, where excessive upscaling may degrade performance due to shifts in data distribution.
Qwen2.5-VL-3B-Instruct is released under the Apache-2.0 license, which permits broad research and development use.