Launch a dedicated cloud GPU server running Laboratory OS to download and run Wan 2.1 T2V 1.3B using any compatible app or framework.
Direct Download
Must be used with a compatible app, notebook, or codebase. May run slowly, or not work at all, depending on local system resources, particularly GPU(s) and available VRAM.
Generate images and videos using a powerful low-level workflow graph builder - the fastest, most flexible, and most advanced visual generation UI.
Model Report
Wan-AI / Wan 2.1 T2V 1.3B
Wan 2.1 T2V 1.3B is an open-source text-to-video generation model developed by Wan-AI, featuring 1.3 billion parameters and utilizing a Flow Matching framework with diffusion transformers. The model supports multilingual text-to-video synthesis in English and Chinese, operates efficiently on consumer GPUs requiring 8.19 GB VRAM, and generates 480P videos with capabilities for image-to-video conversion and text rendering within videos.
Explore the Future of AI
Your server, your data, under your control
Wan 2.1 T2V 1.3B is an open-source text-to-video generative model developed as part of the Wan2.1 suite, which includes a range of AI models for video synthesis and editing. This model utilizes its architecture to enable efficient and high-quality video generation from textual prompts, supporting both English and Chinese languages. Designed for resource-efficient deployment, Wan 2.1 T2V 1.3B targets compatibility with consumer-grade GPUs. The model's performance has been evaluated across a variety of standardized benchmarks, and it incorporates approaches in video compression and text rendering within videos.
Evaluation results for Wan2.1-T2V-1.3B and other state-of-the-art models using the Wan-Bench framework, comparing a wide range of video generation metrics.
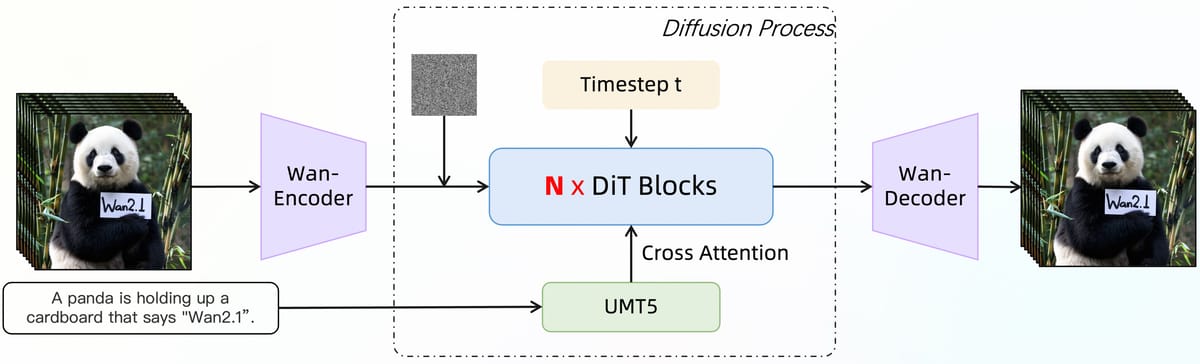
Wan 2.1 T2V 1.3B builds upon the diffusion transformer paradigm, following a Flow Matching framework for video generation. At its core lies a UMT5-based text encoder that processes multilingual prompts, with cross-attention mechanisms embedded into each transformer block for semantic integration. Temporal dynamics are represented using a multi-layer perceptron to generate specialized modulation parameters for each time step, contributing to temporal consistency and visual coherence. This architecture is complemented by the custom Wan-VAE—a three-dimensional causal variational autoencoder—which is responsible for spatio-temporal compression and efficient video encoding and decoding.
Architectural diagram of the diffusion-based video generation process in Wan2.1, illustrating the role of the encoder, transformer blocks, and VAE in converting textual prompts into video sequences.
The model is configured with 1.3 billion parameters and features a dimensionality of 1536 across 30 transformer layers, 12 attention heads, and a feedforward dimension of 8960. Input and output dimensions accommodate sequences of video frames, allowing flexible video lengths. This design aims to support semantic alignment and video synthesis, while optimizing memory and compute efficiency.
Training Data and Data Curation Pipeline
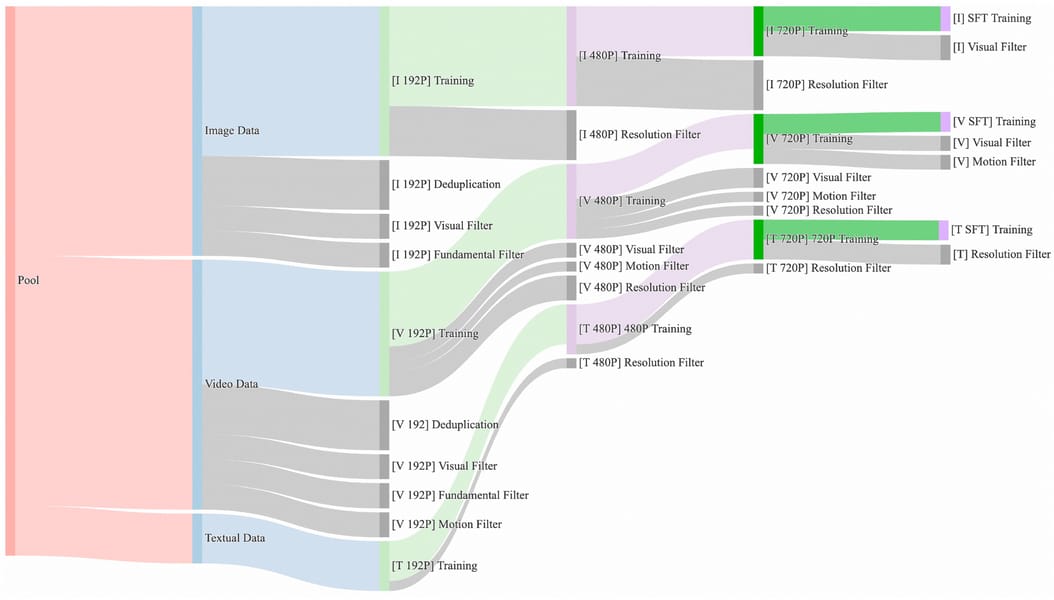
The training of Wan 2.1 T2V 1.3B utilized a large-scale, heterogeneous dataset comprising both high-quality videos and images. A multi-stage data cleaning pipeline was employed. This process began with deduplication and filtering based on fundamental dimensions, followed by targeted quality assessments of visual, motion, and resolution characteristics. These measures ensured that only data meeting quality standards contributed to training, thereby supporting video clarity, visual characteristics, and textual integration.
Sankey diagram illustrating the multi-step data curation pipeline, from raw pool to filtered training data encompassing both image and video modalities.
The data corpus enabled the model to learn a broad spectrum of styles, objects, actions, and scene structures. The inclusion of extensive multilingual text-video pairs also supported the model’s ability to render text accurately within generated videos—a feature for applications requiring onscreen textual information.
Technical Innovations and Performance
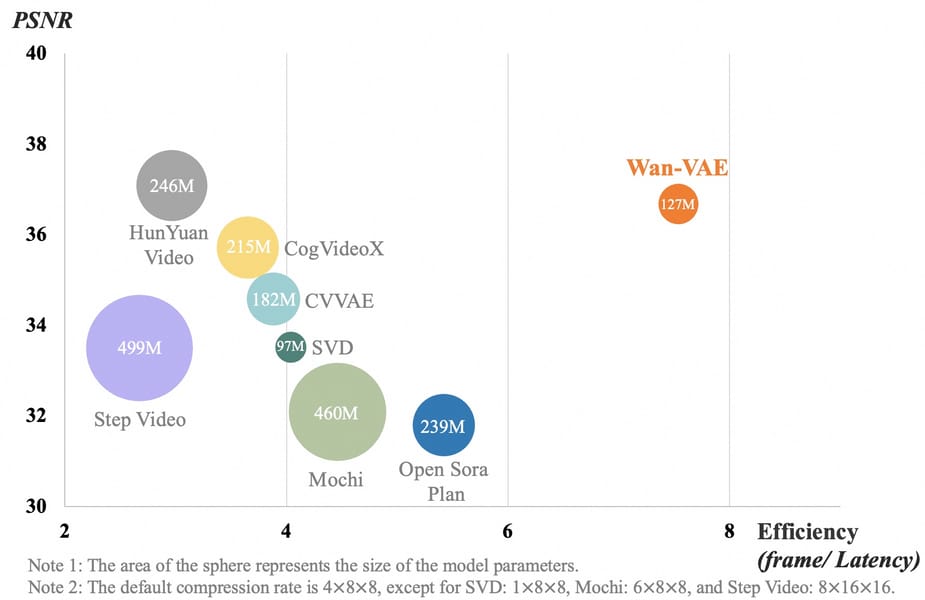
The model's efficiency relies on the Wan-VAE, a novel video variational autoencoder. This 3D causal VAE architecture provides gains in spatio-temporal compression, reducing memory and compute requirements while preserving temporal structure. The VAE is capable of encoding and decoding high-resolution videos, including 1080P sequences of variable length, supporting both direct video synthesis and use as an intermediate representation for editing and transformation tasks.
Scatter plot comparing PSNR and efficiency of various video VAE architectures, highlighting the parameter efficiency of Wan-VAE relative to other open-source models.
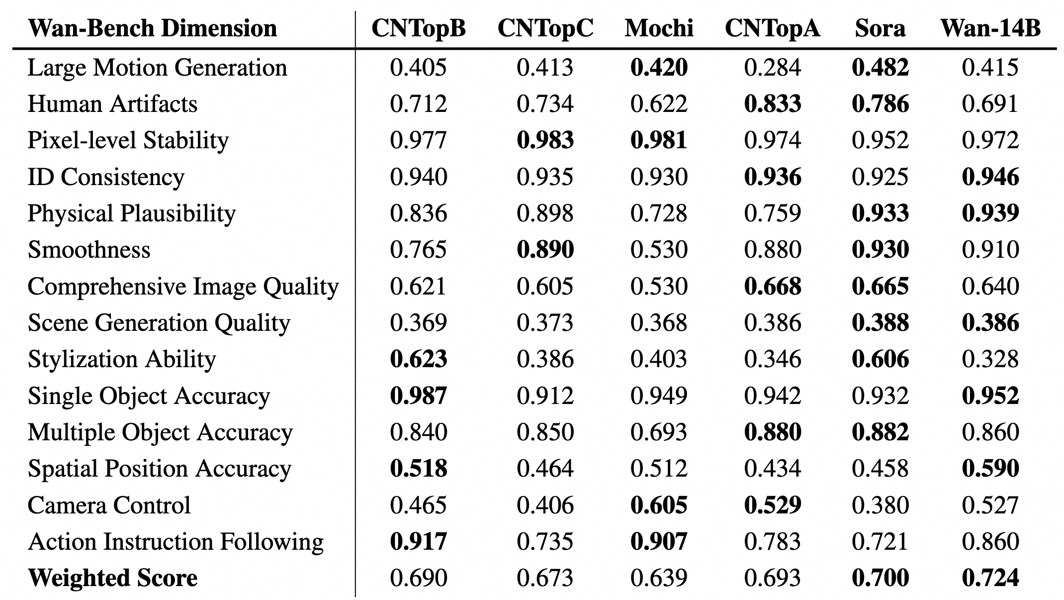
In systematic benchmarking using the Wan-Bench evaluation suite, the T2V-1.3B model's performance was evaluated against comparable open-source models and proprietary solutions. Metrics assessed include motion generation, physical plausibility, image quality, scene diversity, stylization, and action following. The model's architecture and data processing pipeline are associated with its evaluated weighted scores across multiple test dimensions.
Comparison of evaluation scores for Wan2.1 and other leading models across a range of video synthesis criteria, including motion, quality, and scene control.
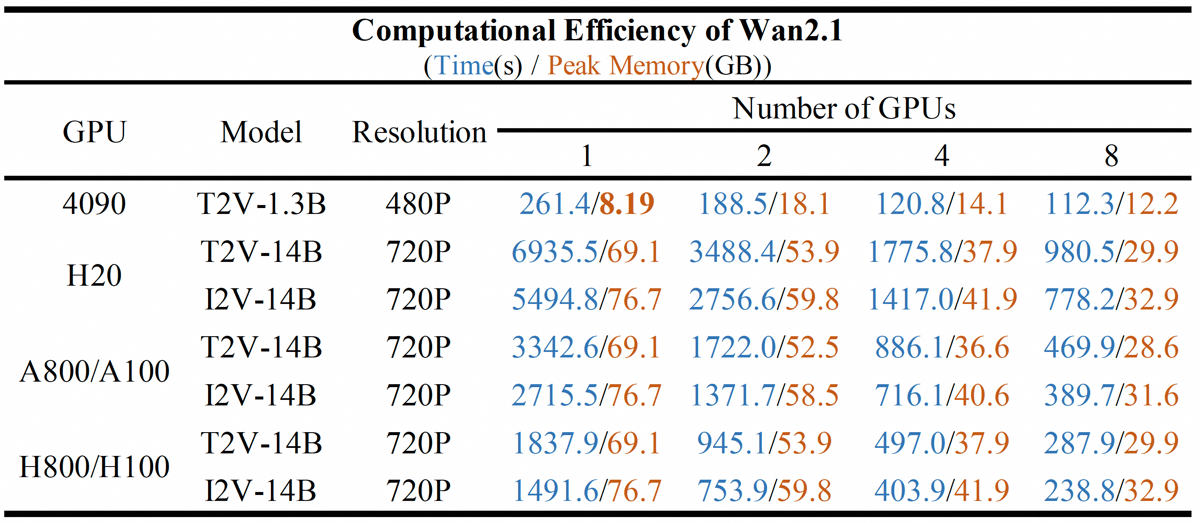
The model requires 8.19 GB of VRAM to generate a 5-second 480P video, enabling operation on widely available consumer GPUs. Execution time for this generation task is approximately 231 seconds on an RTX 4090, with further acceleration achievable through optimized distributed computation.
Computational efficiency comparison for Wan2.1 models across multiple GPU types and cluster sizes, demonstrating scalability and resource-friendly deployment.
Wan 2.1 T2V 1.3B supports various creative and technical workflows. Its main capability is text-to-video generation, in which video content is synthesized directly from descriptive prompts. The model can also transform static images into dynamic video clips (image-to-video), perform advanced video editing, and execute complex generation tasks such as interpolating entire sequences from specified first and last frames (First-Last-Frame-to-Video, or FLF2V). With its integrated multilingual text rendering engine, the model allows for the generation of embedded English and Chinese text within videos.
The VACE pipeline enables combining text, video, mask, and image inputs for flexible video creation and editing. Wan 2.1 T2V 1.3B finds application in animation, content creation, storyboarding, educational media, and research on video-language models.
Demonstration video highlighting the text-to-video generation capabilities of Wan2.1-T2V-1.3B. [Source]
Sample of AI-generated content created using Wan2.1, demonstrating detailed scene composition and lighting effects for complex prompts.
Additional video demo illustrating diverse visual and motion capabilities of the Wan2.1 suite. [Source]
Model Variants, Benchmarks, and Limitations
The Wan2.1 suite features additional models—including T2V-14B, I2V-14B, FLF2V-14B, and VACE variants—that offer higher resolution (up to 720P), larger parameter counts, and expanded editing functionalities. T2V-1.3B supports 480P video synthesis, with 720P support available but stability may vary due to training data characteristics. For FLF2V tasks, results are typically achieved using Chinese prompts, reflecting training data characteristics.
Benchmark comparisons of Wan2.1 T2V 1.3B show its weighted scores and performance across evaluation categories.
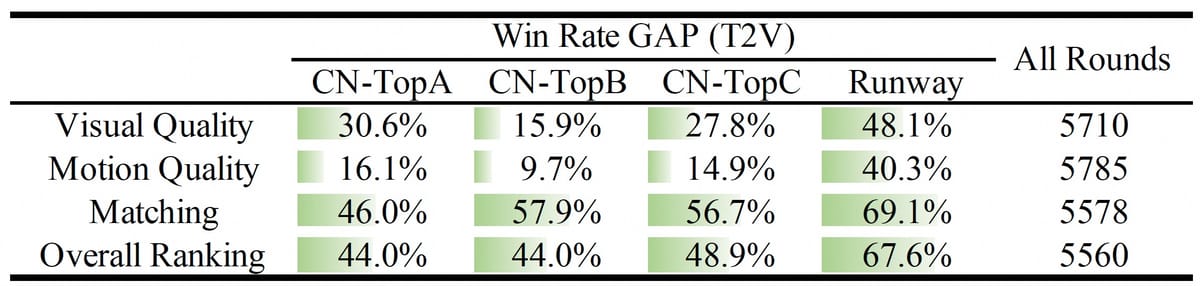
Results from the Win Rate GAP (T2V) benchmark, comparing Wan2.1 outputs with other major text-to-video models on visual quality and motion metrics.
Limitations include stability at 720P for the 1.3B parameter model, incomplete support for distributed inference or prompt extension within some deployment pipelines, and language preferences for specialized tasks such as first-last-frame generation.
Release, Licensing, and Access
Wan2.1 T2V 1.3B is released under the Apache 2.0 License, which permits free use, modification, and distribution. Users must ensure compliance with the license terms, which prohibit harmful or illegal use, dissemination of personal data, or the propagation of misinformation. The model weights, codebase, and documentation are publicly available, with releases periodically updated to expand capabilities across the Wan2.1 family.
Standalone example of an AI-generated scene depicting dynamic motion and detailed environmental effects.
Further demonstration videos and model outputs are also available in the official video demo. For collaborative discussion, refer to the Discord community.