Launch a dedicated cloud GPU server running Laboratory OS to download and run Qwen3 14B using any compatible app or framework.
Direct Download
Must be used with a compatible app, notebook, or codebase. May run slowly, or not work at all, depending on local system resources, particularly GPU(s) and available VRAM.
Open WebUI is an open-source, self-hosted web interface with a polished, ChatGPT-like user experience for interacting with LLMs. Integrates seamlessly with local Ollama installation.
The most full-featured web interface for experimenting with open source Large Language Models. Featuring a wide range of configurable settings, inference engines, and plugins.
Model Report
Alibaba Cloud / Qwen3 14B
Qwen3-14B is a dense transformer language model developed by Alibaba Cloud with 14.8 billion parameters, featuring hybrid "thinking" and "non-thinking" reasoning modes that can be controlled via prompts. The model supports 119 languages, extends to 131k token contexts through YaRN scaling, and includes agent capabilities with tool-use functionality, all released under Apache 2.0 license.
Explore the Future of AI
Your server, your data, under your control
Qwen3-14B is a dense large language model (LLM) developed by Alibaba Cloud's Qwen team as part of the Qwen3 model series, officially released on April 29, 2025. Designed to balance advanced reasoning abilities, multilingual coverage, and efficient deployment, Qwen3-14B forms a core component of the Qwen3 lineup. The model and its weights are made publicly available under the Apache 2.0 license, supporting broad research and application in natural language processing. Qwen3-14B distinguishes itself through its hybrid "thinking" and "non-thinking" modes, high context window support, agent tool-use capabilities, and a comprehensive training pipeline leveraging both vast data and advanced architectural features.
Qwen3 logo, serving as the official visual identity for the model family.
Qwen3-14B employs a dense, causal transformer architecture featuring 40 layers and grouped query attention (GQA), with 40 heads for queries and 8 for keys/values. The total parameter count reaches approximately 14.8 billion, of which 13.2 billion are non-embedding parameters, supporting nuanced language understanding and generation, as described in the Qwen3 technical report.
Major architectural components include SwiGLU activation, rotary positional embeddings (RoPE) with enhanced base frequency, and RMSNorm with pre-normalization. The model utilizes Qwen's byte-level byte-pair encoding (BBPE) tokenizer with a vocabulary of 151,669 tokens, facilitating robust multilingual handling. Innovative attention mechanisms such as QK-Norm and the removal of QKV bias further improve stability during training.
A key distinction for Qwen3-14B is its support for hybrid reasoning modes. In "thinking mode," the model undertakes detailed, stepwise reasoning, generating intermediate "thinking content" before arriving at a final response. This process is explicitly marked with <think> tags and can be controlled dynamically by prompt instructions. Alternatively, "non-thinking mode" provides rapid, concise outputs suitable for general queries. This hybrid capability enables users to balance computational cost with response quality.
Training Pipeline and Data
Qwen3-14B is trained using a multi-stage pipeline, beginning with a massive pre-training dataset of roughly 36 trillion tokens in 119 languages and dialects. This pre-training dwarfs earlier Qwen model generations, bolstering the model's knowledge base and cross-lingual performance as detailed in the Qwen3 blog.
The pipeline encompasses three main pre-training stages: a general phase for language acquisition and factual content, a reasoning-intensive stage with increased STEM, coding, and chain-of-thought data, and a long-context phase that adapts the model for sequences up to 32,768 tokens using RoPE adjustments such as ABF, YaRN scaling, and Dual Chunk Attention. For extended contexts, Qwen3-14B can handle up to 131,072 tokens via YaRN scaling with simple configuration changes.
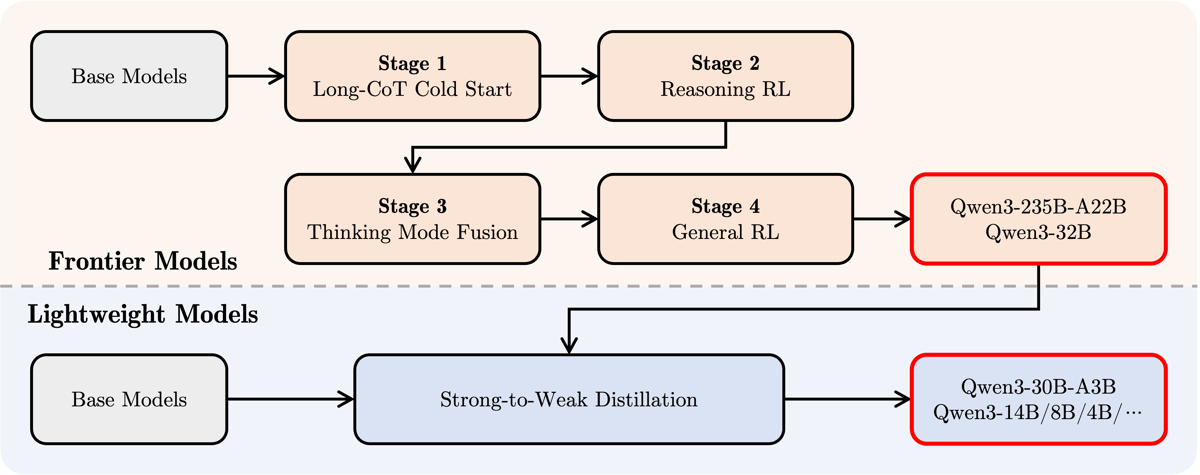
The post-training process for Qwen3-14B leverages "strong-to-weak distillation," where knowledge from larger models is transferred through both off-policy and on-policy means, enabling efficient enhancement of reasoning and dynamic mode-switching abilities with fewer computational resources than full four-stage training. These procedures are formally outlined in the Qwen3 technical paper.
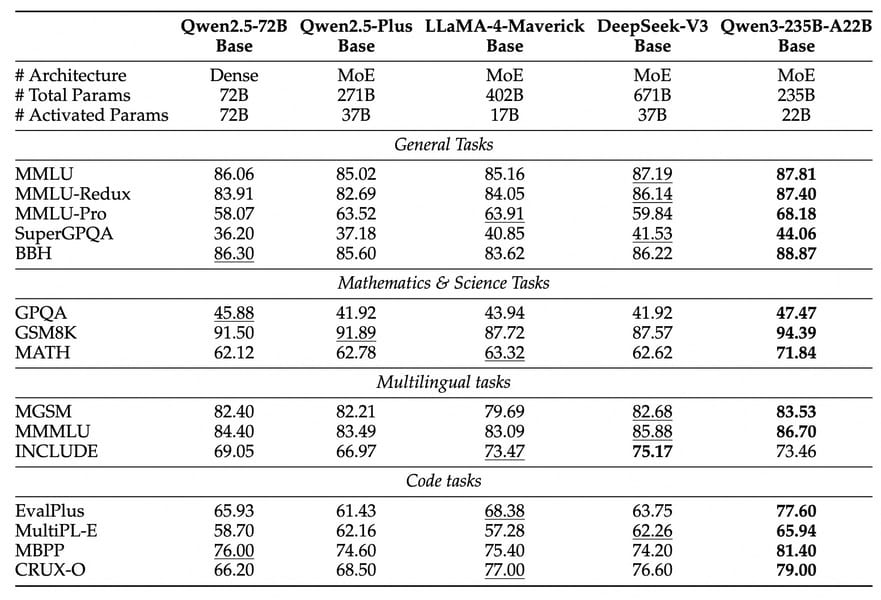
Performance benchmarks across major language model tasks, demonstrating comparative test scores on general, STEM, multilingual, and code-related benchmarks.
Qwen3-14B demonstrates competitive performance across a diverse range of evaluation benchmarks. On general tasks, such as MMLU and BBH, it typically surpasses comparably sized and even larger models. For example, quantitative results reported in the technical paper indicate that Qwen3-14B-Base attains scores of 81.05 on MMLU and 81.07 on BBH, outperforming baselines like Gemma-3-12B and Qwen2.5-14B.
Mathematics and STEM-related tasks also show notable strengths, with Qwen3-14B achieving 62.02 on MATH and 92.49 on GSM8K. In multilingual benchmarks spanning 119 dialects and languages, the model maintains high accuracy, as reflected in MGSM and MMMLU benchmarks. Coding challenges—evaluated on datasets such as EvalPlus and MBPP—highlight robust agentic and code synthesis capabilities.
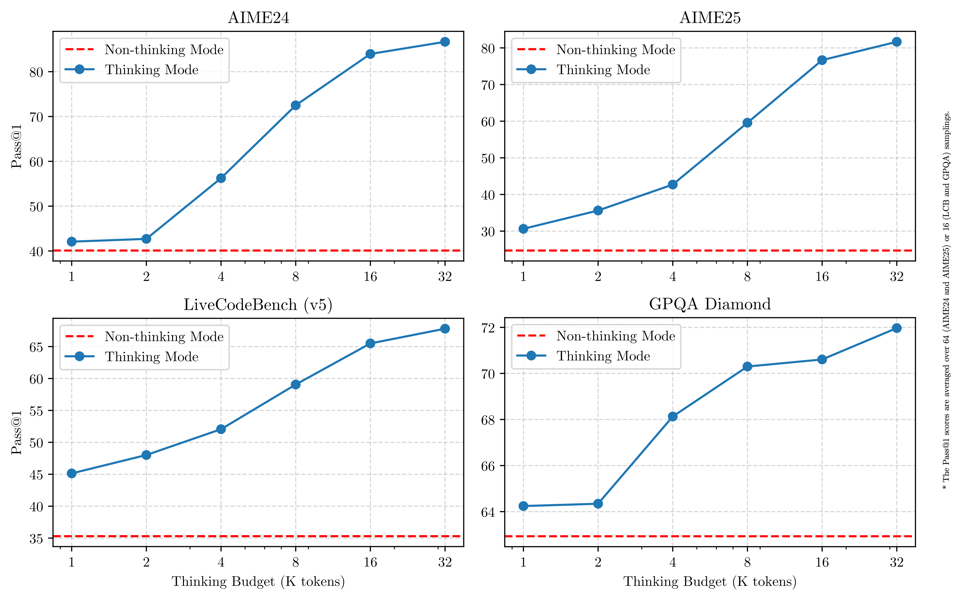
The "thinking mode" is particularly effective for problems requiring multi-step reasoning, as visualized in a series of line charts illustrating the effect of cognitive budget on Pass@1 rates. Non-thinking mode facilitates efficiency on simpler or retrieval-oriented queries, with dynamic switching available by prompt control.
Performance of thinking vs non-thinking modes across major benchmarks as a function of thinking budget.
Qwen3-14B has been optimized for versatile agent-style use cases, supporting the Multi-Modal Control Protocol (MCP) for seamless tool-calling and environment interaction. This enables the model to function effectively in agent-driven workflows, integrating with external APIs and applications. The built-in "Qwen-Agent" toolkit packages prompt templates for tool-use, further facilitating agentic deployment as noted in the Qwen-Agent documentation.
Demonstration of Qwen3's agentic tool-use capability, showing reasoning steps and tool invocation via the MCP protocol. [Source]
The extensive multilingual pre-training corpus equips Qwen3-14B for nuanced cross-lingual understanding and generation across 119 languages. Assessments on Spanish, French, Portuguese, Italian, Arabic, Japanese, and other languages reveal strong generalization beyond English, opening pathways for globally inclusive applications as described in the Qwen3 paper.
Applications, Usage, and Practical Considerations
Qwen3-14B is employed in scenarios ranging from complex problem-solving—such as mathematical competitions and scientific reasoning—to general-purpose dialogue, creative writing, and code synthesis. Its dynamic reasoning modes allow practitioners to select between stepwise reasoning and concise, rapid responses depending on task complexity. When deployed in agent systems, its tool-use skills support complex workflow automation and decision support.
To maximize performance, sampling parameters such as temperature and top-p should be tuned according to mode; the technical documentation recommends settings of temperature=0.6, top-p=0.95 for thinking mode, and temperature=0.7, top-p=0.8 for non-thinking mode. For exceptionally long documents, YaRN scaling can be enabled via simple configuration to extend processing to 131,072 tokens, though it is advisable to activate this feature only when necessary, as described in the deployment guidelines.
Model outputs for mathematical or multiple-choice answers can be standardized using specific prompting strategies. In multi-turn conversations, only final outputs (not intermediate thinking steps) should be retained in context to ensure consistent results.
Model Family, Comparisons, and Limitations
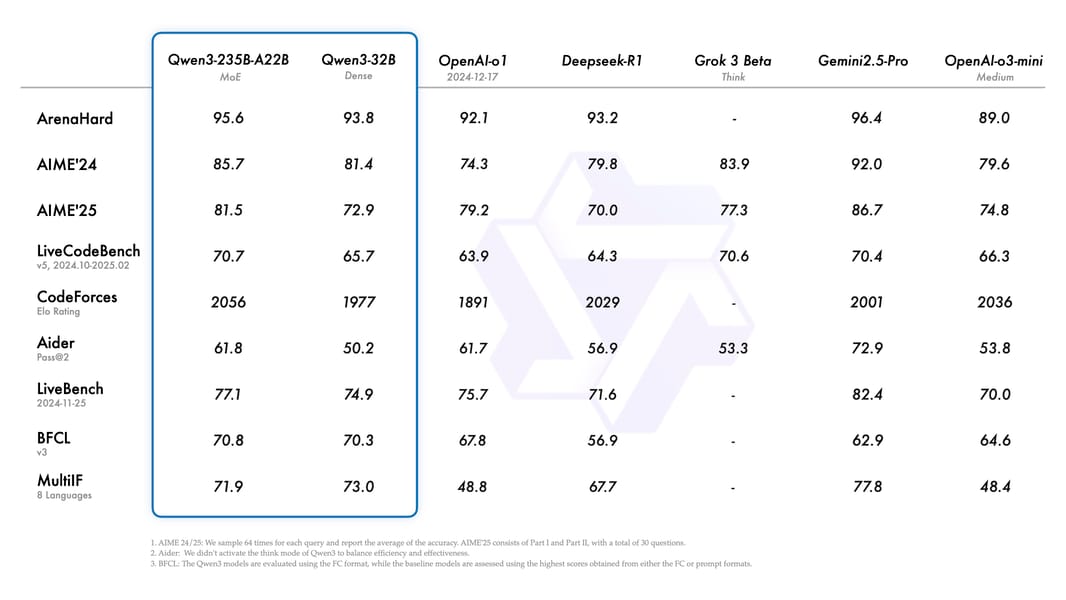
Within the broader Qwen3 family, Qwen3-14B is a mid-scale, dense model that benefits from distillation techniques adopted from larger "frontier" variants such as Qwen3-235B-A22B and Qwen3-32B. The Qwen3 series spans both dense and mixture-of-experts (MoE) designs, with architectures ranging from Qwen3-0.6B up to Qwen3-235B. MoE models utilize advanced routing and load balancing for improved efficiency, matching performance of dense models with fewer activated parameters. Comparative studies in the blog overview and the technical report show that Qwen3-14B generally matches or exceeds the accuracy of similar-size and prior-generation Qwen2.5 models.
Comprehensive table comparing Qwen3 models to other prominent LLMs across major benchmarks.
However, the model does have some known limitations:
Greedy decoding, particularly in thinking mode, can lead to reduced response diversity or looping; probabilistic sampling is recommended for optimal results.
Excessive use of YaRN scaling may degrade performance on standard-length inputs.
For retrieval-focused tasks, thinking mode may introduce irrelevant reasoning steps, slightly lowering accuracy compared to non-thinking mode.
There is a trade-off between generalization and specialization during the final reinforcement learning stage; broadening task coverage can marginally diminish peak performance in highly specialized domains.
Release Cycle, Timeline, and License
The Qwen3 series, including Qwen3-14B, was officially released on April 29, 2025, with the technical report posted in May 2025 on arXiv. The series builds on prior Qwen and QwQ developments based on community and in-house benchmarks.
All Qwen3 models, including Qwen3-14B, are distributed under the Apache 2.0 license, supporting open research, modification, and deployment with attribution.
Further Resources
For more information, code, and documentation, the following resources are recommended: