Launch a dedicated cloud GPU server running Laboratory OS to download and run Yi 1 34B using any compatible app or framework.
Direct Download
Must be used with a compatible app, notebook, or codebase. May run slowly, or not work at all, depending on local system resources, particularly GPU(s) and available VRAM.
Open WebUI is an open-source, self-hosted web interface with a polished, ChatGPT-like user experience for interacting with LLMs. Integrates seamlessly with local Ollama installation.
The most full-featured web interface for experimenting with open source Large Language Models. Featuring a wide range of configurable settings, inference engines, and plugins.
Model Report
01.AI / Yi 1 34B
Yi 1 34B is a bilingual transformer-based language model developed by 01.AI, trained on 3 trillion tokens with support for both English and Chinese. The model features a 4,096-token context window and demonstrates competitive performance on multilingual benchmarks including MMLU, CMMLU, and C-Eval, with variants available including extended 200K context and chat-optimized versions released under Apache 2.0 license.
Explore the Future of AI
Your server, your data, under your control
Yi 1 34B is a large-scale, open-source bilingual language model developed by 01.AI as part of the broader Yi model series. The Yi models are engineered to facilitate advanced language understanding, commonsense reasoning, and reading comprehension in both English and Chinese. The architecture, training regimen, and release practices aim to balance research accessibility, cross-lingual capability, and robust performance across a wide range of language benchmarks and real-world tasks.
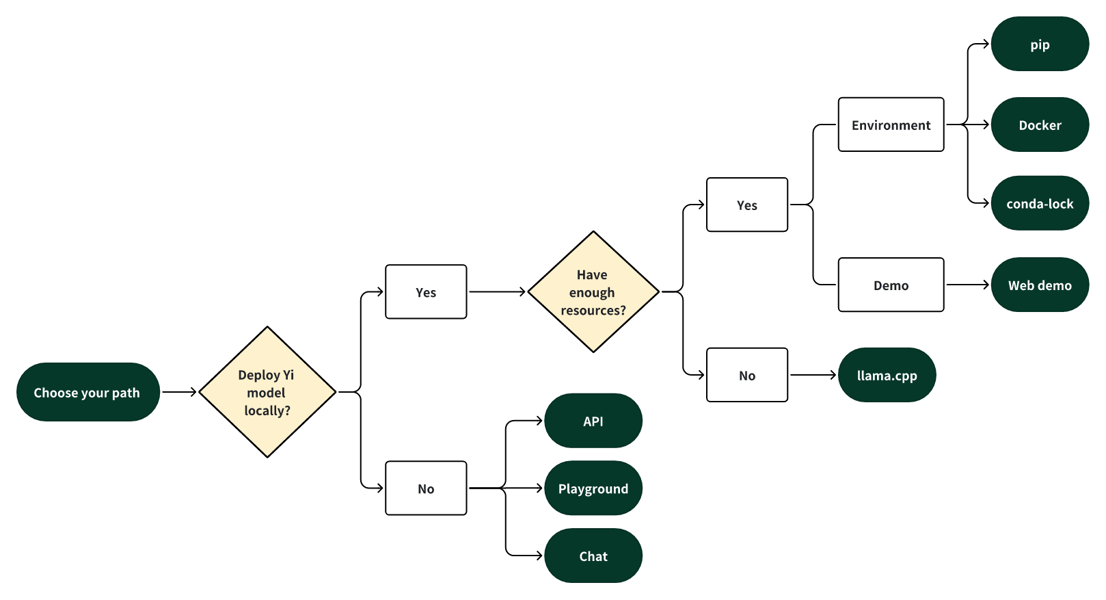
Quick start flowchart outlining the diverse deployment paths for Yi models, including local inference and web-based playgrounds.
Yi 1 34B is implemented using the Transformer architecture, a foundational approach for contemporary large language models. While its design principles are similar to other transformer-based models such as LLaMA, the Yi models are developed independently and do not utilize third-party weights. The model is trained on a 3 trillion token multilingual corpus, with data collected up to June 2023, encompassing both English and Chinese sources to ensure strong bilingual proficiency. Training leverages a suite of proprietary datasets, efficient training pipelines, and large-scale distributed infrastructure to achieve high computational throughput and robust generalization.
A key feature of the Yi model family is support for extended context windows. The base Yi 34B model offers a 4,096-token context window by default, while the Yi-34B-200K variant expands context length to 200,000 tokens, enabling it to process extremely long text sequences. The model series has also undergone supervised fine-tuning (SFT) and supports various quantization techniques, such as GPT-Q and AWQ, to reduce memory footprint and increase inference speed with minimal loss in accuracy.
Capabilities and Evaluation
Yi 1 34B demonstrates capability in multilingual understanding, commonsense reasoning, and complex reading comprehension. Its design specifically targets high performance on both English and Chinese tasks, validated through competitive benchmark results. Evaluations encompass a suite of recognized datasets, including MMLU, CMMLU, C-Eval, BBH, GSM8K, ARC, and others focused on mathematical reasoning, reading comprehension, and code generation.
Demonstration of the Yi 34B chat model responding interactively to a user's request for an explanation of large language models.
In empirical evaluation, Yi-34B and its derived chat models have appeared in top rankings on numerous open leaderboards. As of early 2024, the Yi-34B-Chat model ranked among the leading publicly available LLMs in instruction-following assessments, outperforming several prominent models on the Hugging Face Open LLM Leaderboard, as well as on English and Chinese C-Eval benchmarks. The model sustains high performance in diverse modalities, including question answering, code synthesis, commonsense inference, and more.
Model Variants and Applications
The Yi model suite is composed of several configurations and parameter scales, adapting to a variety of use cases:
Yi-6B and Yi-9B: Lighter-weight models optimized for personal or academic applications and tasks requiring greater efficiency. The 9B variant, in particular, demonstrates robust performance in coding and mathematical benchmarks.
Yi-34B and Yi-34B-200K: Larger models designed for enhanced reasoning and expanded context support. The extended window of the 200K variant allows processing of book-length texts or multiple long documents in a single pass.
Vision-Language Models: The release of Yi-VL-34B and Yi-VL-6B extends capabilities to multimodal tasks, including image and text integration.
Quantized Versions: GPT-Q and AWQ quantizations offer smaller memory footprints, accommodating deployment on resource-constrained hardware with only minor reductions in accuracy.
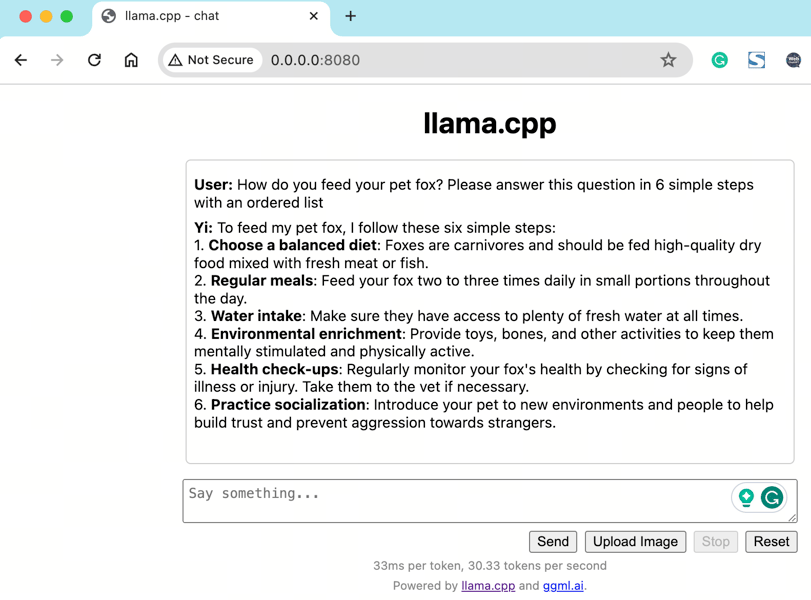
Screenshot of an interactive conversation with Yi-34B running locally, demonstrating structured output to a user's multi-step query.
Typical applications for the Yi models encompass conversational AI, creative content generation, educational assistants, code generation, and research scenarios requiring strong multilingual support and long-context reasoning.
Performance, Benchmarks, and Limitations
Benchmark results indicate Yi 1 34B positions competitively among open-source bilingual models. On the AlpacaEval leaderboard, it maintained a consistent position directly behind commercial GPT-4 models, while outperforming numerous open-access alternatives.
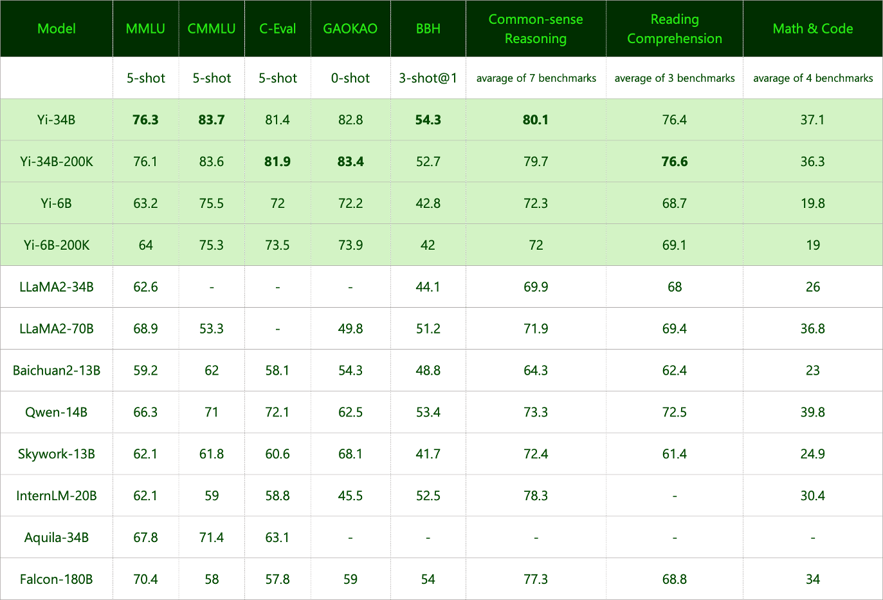
A comprehensive table comparing Yi-34B models with other leading open-source language models across academic and commonsense reasoning tasks.
Despite its high performance, Yi-34B shares known LLM limitations. The chat models may produce outputs that are non-deterministic or factually incorrect, especially when prompted for creative or open-ended tasks, due to the SFT-induced diversity. Quantized models, particularly those reduced to 4 or 8-bits, can experience a small but noticeable performance decline, especially in tasks requiring subtle logical reasoning. Cumulative error may occur in complex reasoning chains, and, as with all large language models, thorough result validation is essential in critical applications.
Release Timeline and Licensing
Yi-34B and other Yi models have been released in several milestones:
The initial release of Yi-6B and Yi-34B occurred on November 2, 2023, followed soon after by the long-context (200K) models.
Chat variants and quantized models followed later in November 2023.
Vision-language models and subsequent intermediate-scale models (Yi 1.5 series) expanded the portfolio in early to mid-2024.
The technical report and Yi Cookbook provide further documentation, tutorials, and practical examples for the community.
Yi models are released under the Apache 2.0 license, granting permissive usage for personal, academic, and commercial projects, subject to attribution requirements.