Launch a dedicated cloud GPU server running Laboratory OS to download and run Yi 1.5 34B using any compatible app or framework.
Direct Download
Must be used with a compatible app, notebook, or codebase. May run slowly, or not work at all, depending on local system resources, particularly GPU(s) and available VRAM.
Open WebUI is an open-source, self-hosted web interface with a polished, ChatGPT-like user experience for interacting with LLMs. Integrates seamlessly with local Ollama installation.
The most full-featured web interface for experimenting with open source Large Language Models. Featuring a wide range of configurable settings, inference engines, and plugins.
Model Report
01.AI / Yi 1.5 34B
Yi 1.5 34B is a 34.4 billion parameter decoder-only Transformer language model developed by 01.AI, featuring Grouped-Query Attention and SwiGLU activations. Trained on 3.1 trillion bilingual tokens, it demonstrates capabilities in reasoning, mathematics, and code generation, with variants supporting up to 200,000 token contexts and multimodal understanding through vision-language extensions.
Explore the Future of AI
Your server, your data, under your control
The Yi 1.5 34B model is a large language model developed by 01.AI as part of the broader Yi series, which focuses on capabilities in both language and multimodal understanding. It incorporates updates over prior iterations and was designed for performance across a range of domains, demonstrating capabilities in reasoning, mathematics, code, and instruction-following tasks. The Yi model family includes various sizes and configurations, as well as extensions for long-context processing and vision-language capabilities, aiming to serve as a versatile foundation for natural language processing research and applications, as documented in its Hugging Face model page and research paper.
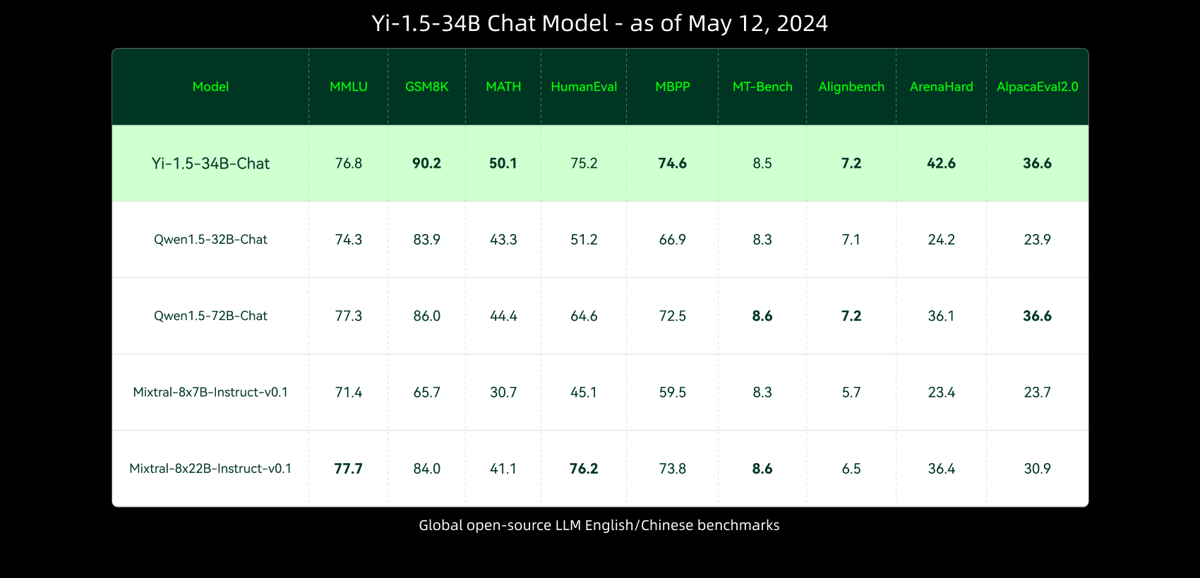
A benchmark table comparing chat model performances across several language understanding and reasoning benchmarks. Rows highlight Yi-1.5-34B-Chat alongside other models.
Yi 1.5 34B features a modified decoder-only Transformer architecture, inheriting design elements from established models. The model uses Grouped-Query Attention (GQA) to improve efficiency in both training and inference. Activation layers are built on the SwiGLU function, which aims to optimize parameter usage post-attention, while positional encoding employs RoPE with an adjusted base frequency to support extended context windows. The base model contains 34.4 billion parameters, with a hidden size of 7168 and 60 layers.
The Yi model series also encompasses long-context variants capable of handling contexts up to 200,000 tokens, accomplished through lightweight continual pretraining and specialized positional encodings, as described in the research paper. For vision-language integration, Yi-VL models adapt a Vision Transformer and projection modules, aligning visual and textual representations through multi-stage training, according to the research paper.
Training Data and Optimization Techniques
Yi 1.5 34B was pretrained on a large-scale, high-quality bilingual corpus, comprising approximately 3.1 trillion tokens in English and Chinese. A rigorous pipeline—incorporating heuristic, learned, and cluster-based filters—aimed to ensure data quality and redundancy reduction, as detailed in the research paper. Tokenization utilizes SentencePiece with byte pair encoding, supporting a vocabulary of 64,000 tokens.
Fine-tuning emphasizes carefully filtered instruction-response pairs, prioritizing dataset diversity and quality. Techniques such as compound instruction writing, structured response formatting, and “Step-Back” chain-of-thought reasoning were employed, as noted in the research paper. The finetuning process employs next-word prediction loss, focused only on responses, and uses the AdamW optimizer with a batch size of 64 and a sequence length of 4096.
For the vision-language models, multi-phase training incorporates large-scale public image-text datasets such as LAION-400M and several specialized multimodal resources, facilitating bilingual and multimodal alignment, per the research paper.
Performance and Benchmarking
Yi 1.5 34B-Chat is observed to perform in alignment with established open models on established benchmarks. It performs in alignment with and in some cases exhibits comparable results to alternatives with more parameters—for example, GPT-3.5—in certain categories. Evaluations on tasks such as MMLU, BBH, and reading comprehension indicate the model's capabilities in reasoning and instruction following.
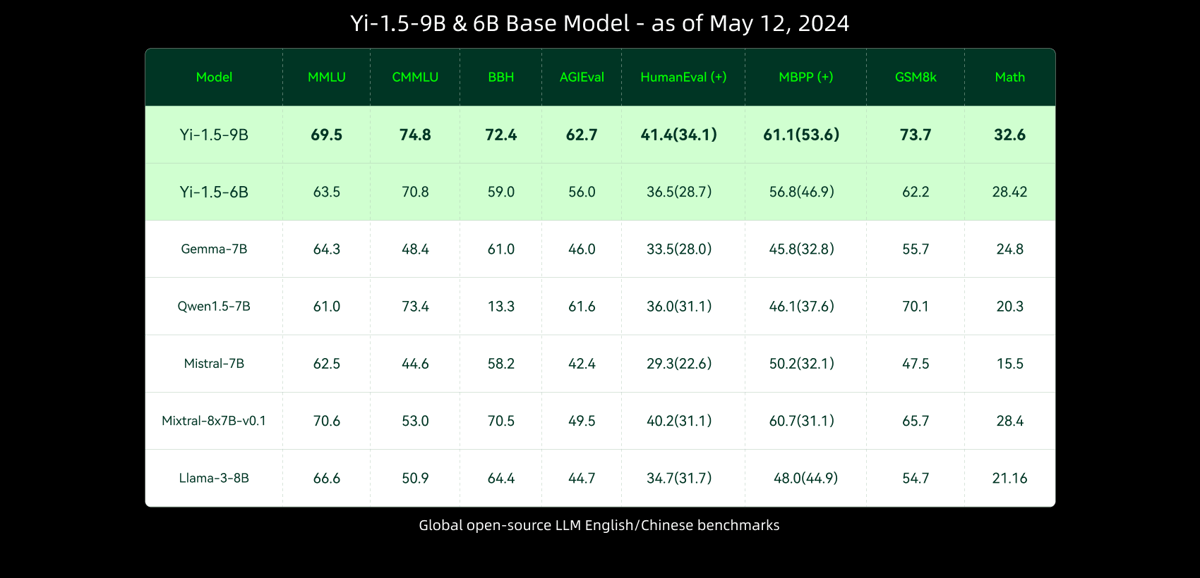
A comparison table illustrating benchmark scores for Yi-1.5-9B and 6B base models versus other large language models on multiple English/Chinese evaluation sets.
The base model achieves reported scores of 76.3 on MMLU, 54.3 on BBH, and 81.4 on C-Eval, as cited in the research paper. In human and automated comparisons, such as the LMSys Chatbot Arena, Yi-Chat-34B exhibits instruction-following capabilities comparable to other models, attaining an Elo score of 1110. On the SuperClue benchmark, it attains a score of 71.87 in Chinese language tasks. Performance in tasks necessitating extensive context—validated by results on Needle-in-a-Haystack tests—confirms the effectiveness of context-length extensions up to 200,000 tokens. For multimodal tasks, Yi-VL-34B achieves competitive results, scoring 41.6 on the MMMU set, as stated in the research paper.
Applications and Use Cases
As a general-purpose language model, Yi 1.5 34B is applicable to a diverse set of natural language and code-related tasks, such as language understanding, instruction following, reasoning, coding, and mathematical problem solving, as described on its Hugging Face model page. Efficient quantization (4/8-bit) can enable deployment on widely available GPUs with minimal loss of accuracy, supporting local inference and privacy preservation, per the research paper. The model’s long-context capabilities are relevant for document analysis, summarization, and question answering with extensive source material.
Vision-language variants (Yi-VL-6B/34B) expand the model’s applicability to image-guided dialogue, multimodal comprehension, and generation tasks, bridging visual and textual domains, according to the research paper.
Model Family and Comparative Position
The Yi 1.5 family includes multiple parameter scales and configurations, such as 6B, 9B, and 34B models, in both base and chat forms, and offers long-context and multimodal versions. Depth upscaling was used to create intermediate models, such as the 9B, by duplicating network layers and continuing training from checkpoints. The full family was pretrained on a dataset size that exceeds “Chinchilla optimal” recommendations, which aims to support performance considerations even in smaller models. Comparative benchmarking indicates that the Yi-1.5-9B-Chat demonstrates performance comparable to many models of similar size on major evaluation suites, as presented on the Hugging Face model page.
Limitations and Future Improvements
Although Yi 1.5 34B demonstrates all-around performance, there remain areas for improvement. Mathematical reasoning and coding performance show lower scores compared to some specialized models on certain benchmarks, as noted in the research paper. The capabilities of smaller variants, such as Yi-6B, particularly in mathematics, are observed to be limited and may require additional training strategies. While safety measures—including the Responsible AI Safety Engine (RAISE)—are employed during alignment, ongoing research is necessary to further strengthen model robustness and reduce undesirable outputs.