Launch a dedicated cloud GPU server running Laboratory OS to download and run Llama 3.2 3B using any compatible app or framework.
Direct Download
Must be used with a compatible app, notebook, or codebase. May run slowly, or not work at all, depending on local system resources, particularly GPU(s) and available VRAM.
Open WebUI is an open-source, self-hosted web interface with a polished, ChatGPT-like user experience for interacting with LLMs. Integrates seamlessly with local Ollama installation.
The most full-featured web interface for experimenting with open source Large Language Models. Featuring a wide range of configurable settings, inference engines, and plugins.
Model Report
Meta / Llama 3.2 3B
Llama 3.2 3B is a multilingual instruction-tuned language model developed by Meta with 3 billion parameters and a 128,000-token context window. The model utilizes knowledge distillation from larger Llama variants, Grouped-Query Attention for efficient inference, and advanced quantization techniques optimized for PyTorch's ExecuTorch framework. Supporting eight languages, it targets assistant and agentic applications while enabling deployment in resource-constrained environments.
Explore the Future of AI
Your server, your data, under your control
Llama 3.2 3B is a multilingual large language model (LLM) developed by Meta, released on September 25, 2024. Designed as an instruction-tuned, text-only generative model, Llama 3.2 3B is part of the Llama 3.2 model family, which includes both 1B and 3B parameter variants. It targets scalable assistant and agentic language technologies, emphasizing efficient performance, expanded language support, and optimized deployment for constrained environments. The model family builds upon prior iterations in the Llama lineage, incorporating architectural and training advancements as detailed in the official release and documentation.
Model Architecture and Technical Innovations
Llama 3.2 3B is structured as an auto-regressive transformer-based language model, leveraging recent optimizations to balance quality and computational efficiency. It utilizes Grouped-Query Attention (GQA) to improve inference scalability—a technique that enables high-throughput processing without a proportional increase in hardware demands.
The model has a maximum context window of 128,000 tokens for its text-only variant, facilitating long-context understanding and document processing tasks. In quantized deployments, this context is set to 8,000 tokens to further enable efficient on-device operation.
Advanced quantization techniques are core to Llama 3.2’s design. The quantization scheme employs 4-bit groupwise quantization for transformer block weights, 8-bit per-token dynamic quantization for activations, and 8-bit per-channel quantization for both the classification and embedding layers. These optimizations are designed specifically for PyTorch’s ExecuTorch inference framework, allowing for reductions in model size and improvements in inference speed and memory usage.
Additionally, Llama 3.2 integrates Quantization-Aware Training (QAT) and low-rank adaptation techniques such as LoRA, followed by Direct Preference Optimization (DPO) for alignment. The SpinQuant method is used in conjunction with generative post-training quantization (GPTQ), further refining the quantized model’s performance.
Training Data, Distillation, and Environmental Impact
Llama 3.2 3B is pretrained on up to 9 trillion tokens drawn from publicly available online sources, with a data cutoff in December 2023 to ensure recency in its learned knowledge. The training process for the 1B and 3B models incorporates knowledge distillation from larger counterparts, specifically Llama 3.1 8B and Llama 3.1 70B, by using their output logits as token-level targets. This approach helps enhance the performance of smaller models, even after pruning.
Instruction tuning follows a staged recipe involving supervised fine-tuning, rejection sampling, and direct preference optimization, ensuring outputs that align more closely with human expectations for helpfulness and safety.
In terms of environmental considerations, the training of Llama 3.2 3B utilized about 460,000 GPU hours on H100-80GB hardware, resulting in an estimated 133 tons of CO₂-equivalent greenhouse gas emissions as measured by location-based methodology. However, due to Meta's commitment to net zero greenhouse gas emissions and exclusive use of renewable energy, the total market-based emissions attributed to the model’s training are reported as zero.
Multilingual Performance and Benchmark Evaluation
Llama 3.2 3B features official support for English, German, French, Italian, Portuguese, Hindi, Spanish, and Thai, having been trained on a broader spectrum of languages to increase generalizability. The model exhibits performance across a variety of standardized NLP benchmarks, as summarized in the model card and official documentation:
For instance, on the MMLU benchmark (5-shot setting), the base pretrained Llama 3.2 3B scores 58, compared to 66.7 for the larger Llama 3.1 8B model. Instruction-tuned variants also exhibit metrics in summarization (ROUGE-L), reasoning (ARC-Challenge), math (GSM8K, MATH), and multilingual understanding tasks that are consistent with similar-sized models.
Performance on resource-constrained devices is optimized using quantized models. When deployed using ExecuTorch on an Android mobile device, quantized Llama 3.2 3B models achieve over double the decoding speed and reductions in both memory footprint and model size.
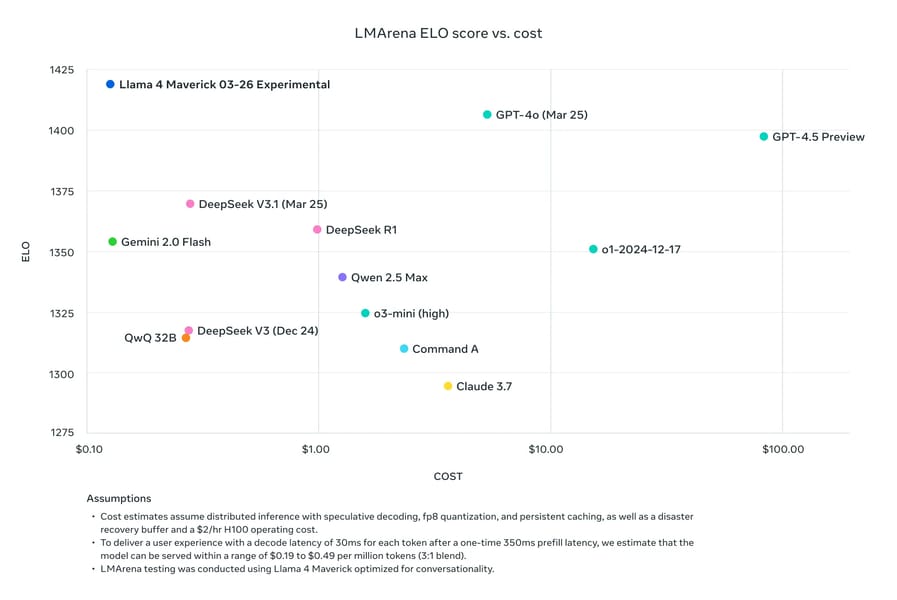
Scatter plot comparing ELO scores and inference costs for various language models. Llama models are benchmarked for cost-effectiveness and performance.
Llama 3.2 3B is instruction-tuned as a text-only model and is intended for both commercial and research applications. Its design prioritizes assistant-like interactions and agentic behaviors, covering use cases such as knowledge retrieval, summarization, writing assistance, query reformulation, and more. The pretrained version provides a foundation for a wide variety of natural language generation tasks through further fine-tuning.
Quantized variants are engineered for deployment in highly constrained environments, including mobile devices and other settings where computational resources are limited. The intended usage encompasses multilingual applications, provided developers adhere to the license agreements and acceptable use policies. Developers are directed to ensure responsible, compliant, and safe deployments, particularly when expanding model use to additional languages or novel domains.
Limitations and Considerations
Llama 3.2 3B shares several limitations typical of large language models. Its outputs are inherently probabilistic and may include inaccuracies or bias. The model's behavior in deployment cannot be predicted for all scenarios, and its use requires the integration of additional safety guardrails. Comprehensive safety and misuse testing are ongoing, but no AI model can be exhaustively validated against every possible risk or application context.
The model is governed by the Llama 3.2 Community License, specifying terms for use, reproduction, adaptation, and distribution—including requirements for attribution and naming conventions when building derivative models. Certain uses are explicitly prohibited, including applications that violate laws, promote harm, or operate in high-risk or highly regulated sectors. Notably, licensing for any multimodal model variants imposes restrictions on use within the European Union.
Family, Release Timeline, and Future Directions
Llama 3.2 3B is part of the Llama 3.2 model family, which also features a 1B parameter size variant. The series builds upon lessons and techniques from the Llama 3.1 family, leveraging distillation from larger models for improved efficiency.
Comparisons with prior models highlight performance differences attributable to model size and and training strategies; Llama 3.2 3B exhibits performance for its parameter count comparable to the Llama 3.1 8B variant when benchmarked. Future development directions, such as the Llama 4 family, are expected to include native multimodality, mixture-of-experts architectures, and further increases in context length, as described in Meta's announcements.
Banner-style graphic used for Llama model section dividers or web headers.