Launch a dedicated cloud GPU server running Laboratory OS to download and run Llama 3.1 8B using any compatible app or framework.
Direct Download
Must be used with a compatible app, notebook, or codebase. May run slowly, or not work at all, depending on local system resources, particularly GPU(s) and available VRAM.
Open WebUI is an open-source, self-hosted web interface with a polished, ChatGPT-like user experience for interacting with LLMs. Integrates seamlessly with local Ollama installation.
The most full-featured web interface for experimenting with open source Large Language Models. Featuring a wide range of configurable settings, inference engines, and plugins.
Model Report
Meta / Llama 3.1 8B
Llama 3.1 8B is a multilingual large language model developed by Meta using a decoder-only transformer architecture with Grouped-Query Attention and a 128,000-token context window. The model is pretrained on 15 trillion tokens and undergoes supervised fine-tuning and reinforcement learning from human feedback. It supports eight languages and demonstrates competitive performance across benchmarks in reasoning, coding, mathematics, and multilingual tasks, distributed under the Llama 3.1 Community License.
Explore the Future of AI
Your server, your data, under your control
Llama 3.1 8B is a multilingual large language model developed by Meta as part of the Llama 3.1 series of generative AI models. Released on July 23, 2024, Llama 3.1 8B is designed for advanced text generation and dialogue tasks, with a focus on multilingual performance and broad coverage across reasoning, code generation, and instruction-following capabilities. The model is part of a family that also includes 70B and 405B parameter versions, offering researchers and developers a range of model scales and capabilities for commercial and research applications. The Llama 3.1 models introduce several architectural and training advances over previous iterations, targeting both practical deployment and scientific utility through open-source distribution under the Llama 3.1 Community License.
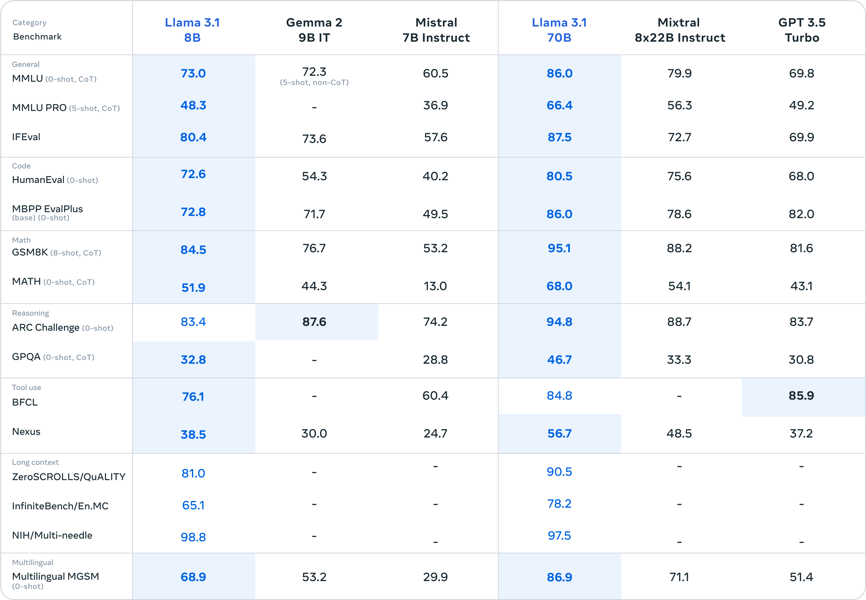
Benchmark table comparing Llama 3.1 8B to other contemporary large language models across tasks including general knowledge, code, math, reasoning, tool use, long context, and multilingual benchmarks.
Llama 3.1 8B is based on an optimized transformer architecture utilizing a decoder-only design. This approach emphasizes stability and efficiency, enabling effective scaling across parameter sizes. The model incorporates Grouped-Query Attention (GQA) to enhance inference scalability and support large context lengths, with Llama 3.1 models offering a context window of up to 128,000 tokens, suitable for tasks such as long-form summarization and extended dialogue. The model is pretrained on a corpus of approximately 15 trillion tokens sourced from publicly available data, with a knowledge cutoff date of December 2023.
Post-pretraining, the Llama 3.1 8B Instruct variant undergoes supervised fine-tuning (SFT) and reinforcement learning with human feedback (RLHF) to better align responses with human preferences for helpfulness and safety. Techniques such as iterative SFT, Rejection Sampling, Direct Preference Optimization (DPO), and the utilization of over 25 million synthetically generated instruction-following examples are employed to improve the model’s alignment and usability, as detailed in Meta’s research publication.
The pretraining and alignment processes benefit from updated data curation and filtering pipelines, emphasizing rigorous quality assurance for both the initial training and the fine-tuning stages. Training for the 8B model specifically involved an estimated 1.46 million GPU hours, accumulating to a total of 39.3 million GPU hours across all Llama 3.1 models.
Technical Capabilities and Multilingual Support
Llama 3.1 8B supports both multilingual input and output, optimized for natural language understanding and generation across eight explicitly supported languages, including English, German, French, Italian, Portuguese, Hindi, Spanish, and Thai. While the model’s instruction-tuned version is designed for assistant-style conversational interactions, the base model can be further adapted for a wide range of use cases, such as code generation, long text synthesis, summarization, and agentic system deployments.
A distinguishing feature of the Llama 3.1 series is the use of model outputs—including synthetic data generation and model distillation—to further improve performance, particularly in instruction-following and coding tasks. This bootstrapped approach allows the generation of large, high-quality datasets that augment supervised alignment with human feedback.
Benchmark Performance
Llama 3.1 8B demonstrates competitive results across numerous benchmarks commonly used for evaluating large language models. For general domain knowledge, the base pretrained model achieves a score of 66.7 in 5-shot MMLU, 47.8 in AGIEval English, and 75.0 in CommonSenseQA. On reasoning and reading comprehension, the model reaches 77.6 on TriviaQA-Wiki, 77.0 on SQuAD, and 75.0 on BoolQ.
The instruction-tuned variant, Llama 3.1 8B Instruct, shows further improvements, with scores such as 69.4 on MMLU 5-shot, 73.0 on zero-shot MMLU with chain-of-thought, and 48.3 on MMLU-Pro. Notably, coding benchmarks are strong, with a 72.6 score on HumanEval and 72.8 on MBPP EvalPlus (base version) in the zero-shot setting. Math and reasoning are also well-represented, with the model obtaining 84.5 on GSM-8K (CoT, 8-shot) and 51.9 on MATH (CoT, 0-shot).
On multilingual MMLU evaluations, the 8B model achieves macro average scores above 60 in several Romance and Germanic languages (e.g., 62.12 in Portuguese, 62.34 in French, 61.63 in Italian, 60.59 in German), while Hindi and Thai scores are around 50. These results reflect the deliberate multilingual optimization of the model, as documented in the Llama 3.1 paper.
Across instruction-tuned benchmarks, Llama 3.1 8B generally outperforms its predecessor, Llama 3 8B, with improvements on tasks such as MMLU (Instruct: 69.4 vs. 68.5), MMLU (CoT: 73.0 vs. 65.3), MMLU-Pro (CoT: 48.3 vs. 45.5), and HumanEval (72.6 vs. 60.4).
Applications and Use Cases
Llama 3.1 8B can be employed for both academic and commercial purposes. Its versatility enables a wide spectrum of applications, including multilingual conversational agents, code synthesis tools, knowledge retrieval systems, and content generation across supported languages. The instruction-tuned models are targeted toward assistant-style dialogue and chatbot services, providing robust instruction following and safe, helpful responses.
The base model serves as a foundation that can be fine-tuned or distilled for specific downstream tasks, from research exploration to customized enterprise workflows. Moreover, outputs from Llama 3.1 can be used in synthetic data pipelines or as a source for knowledge distillation, facilitating further model development and transfer learning scenarios, as described in the model documentation.
Limitations and Responsible Use
Despite extensive safety alignment and red teaming—addressing areas such as child safety and prevention of harmful code—the Llama 3.1 8B model inherits the general risks associated with large language models. These include the possibility of generating inaccurate, biased, or otherwise undesirable content, especially in scenarios not comprehensively covered during development and testing. Developers are advised to conduct thorough safety evaluations tailored to their specific deployment contexts, integrating additional safety guardrails as recommended in the Responsible Use Guide.
The model explicitly supports eight languages; usage in other languages without task-specific fine-tuning or additional controls is discouraged. Meta’s Acceptable Use Policy outlines restrictions, prohibiting deployment scenarios that violate applicable laws or risk user safety, and requiring clear end-user disclosures of known risks in AI-powered applications.
Licensing and Model Access
Llama 3.1 8B is distributed under the Llama 3.1 Community License, which permits use, reproduction, modification, and distribution, provided users adhere to provisions regarding attribution, responsible deployment, and license compliance. Key terms include non-exclusive, worldwide rights, attribution requirements ("Built with Llama"), and rules surrounding redistribution, trademark usage, and commercial scale thresholds. The model and associated materials are provided "as is" without warranty, with Meta retaining all intellectual property while derivative works remain with licensees, as detailed in the Community License documentation.
Related Models in the Llama Family
Llama 3.1 8B is part of a broader ecosystem that includes the Llama 3.1 70B and 405B parameter models. All leverage the Grouped-Query Attention (GQA) mechanism and share the architectural and alignment advances present in the Llama 3.1 series. The largest, 405B, is positioned as an open "frontier" model, while the 8B and 70B variants serve use cases requiring smaller model sizes and faster inference, as discussed in the Llama 3.1 release announcement.