Launch a dedicated cloud GPU server running Laboratory OS to download and run Llama 3 8B using any compatible app or framework.
Direct Download
Must be used with a compatible app, notebook, or codebase. May run slowly, or not work at all, depending on local system resources, particularly GPU(s) and available VRAM.
Open WebUI is an open-source, self-hosted web interface with a polished, ChatGPT-like user experience for interacting with LLMs. Integrates seamlessly with local Ollama installation.
The most full-featured web interface for experimenting with open source Large Language Models. Featuring a wide range of configurable settings, inference engines, and plugins.
Model Report
Meta / Llama 3 8B
Llama 3 8B is an open-weights transformer-based language model developed by Meta, featuring 8 billion parameters and trained on over 15 trillion tokens. The model utilizes grouped-query attention and a 128,000-token vocabulary, supporting 8,192-token context lengths. Available in both pretrained and instruction-tuned variants, it demonstrates capabilities in text generation, code completion, and conversational tasks across multiple languages.
Explore the Future of AI
Your server, your data, under your control
Meta Llama 3 8B is a large language model (LLM) developed by Meta as part of the Llama 3 model family. Designed for advanced text and code generation, Llama 3 8B is available in both pretrained and instruction-tuned variants, supporting diverse use cases ranging from assistant-style dialogue to natural language processing research. The Llama 3 8B model emphasizes openness, scalability, and responsible AI deployment, incorporating developments in reasoning, code generation, and instruction following over previous Llama iterations, as detailed by Meta.
This introductory video provides a high-level overview of Llama 3, its design intent, and its uses across Meta's products. [Source]
Model Architecture and Technical Innovations
Llama 3 8B employs a transformer-based, auto-regressive architecture tailored for efficient inference and scalability. It utilizes a grouped-query attention mechanism to enhance inference performance across both the 8B and 70B parameter model variants, as described in the technical documentation.
The architecture utilizes a 128,000-token vocabulary tokenizer. This larger, more efficient tokenizer improves language representation and ensures that the model matches the inference efficiency of the previous Llama 2 7B model, despite handling more parameters. Llama 3 models are trained with context lengths of 8,192 tokens, with explicit masking strategies to isolate document boundaries during training.
Developments in training infrastructure and software contributed to the scalability of Llama 3. Meta leveraged its Research SuperCluster and large-scale production clusters, automating training validation and improving infrastructure reliability. The largest-scale training runs utilized up to 24,000 GPUs simultaneously, reaching over 400 TFLOPS per GPU, according to Meta's published benchmarks.
Training Data and Alignment Methods
Llama 3 8B is pretrained on a corpus exceeding 15 trillion tokens, drawn from publicly available sources. This dataset is considerably larger than those used for previous Llama models and contains approximately four times more code-related data, as documented in the Llama 3 blog post. Data curation involved heuristic filtering, semantic deduplication, and classifier-based prediction of data quality, with earlier Llama models aiding the curation process.
For multilingual capabilities, over 5% of pretraining data was sourced from high-quality datasets in more than 30 languages. However, English remains the primary language for optimal performance unless further fine-tuning is performed in other languages.
Fine-tuning employed supervised datasets and over ten million human-annotated examples, focusing instruction-tuned variants for chat and dialogue. For alignment, Llama 3 integrates supervised fine-tuning (SFT), reinforcement learning with human feedback (RLHF), and reward modeling. Post-training utilizes a mix of rejection sampling, proximal policy optimization, and direct preference optimization, combined with multiple rounds of manual quality assurance, as outlined by Meta.
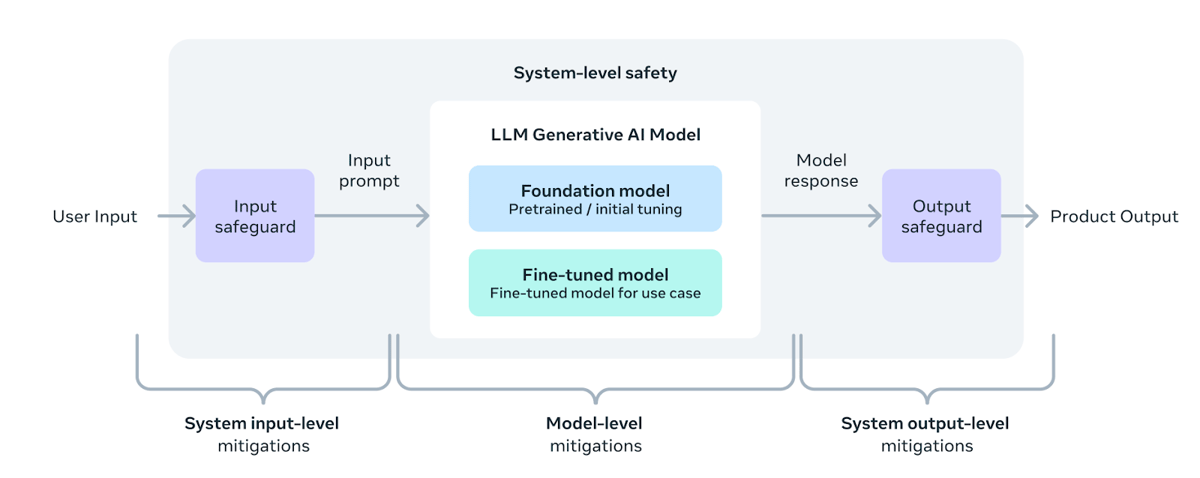
A system-level safety diagram depicting how Llama 3 models incorporate input and output safeguards with model-level mitigations to balance utility and safety in deployment.
Llama 3 8B exhibits improved performance across a wide range of language understanding, reasoning, and code generation benchmarks when compared to earlier models such as Llama 2 and other contemporary LLMs.
According to Meta's test results, the instruction-tuned Llama 3 8B achieves scores on multiple industry benchmarks, including MMLU, HumanEval, and GSM-8K. The model exhibits notably reduced false refusal rates following enhancements in post-training alignment procedures, resulting in more compliant behavior on benign prompts.
Side-by-side performance tables comparing the Llama 3 8B and 70B models against other leading language models on benchmarks like MMLU, GPQA, HumanEval, GSM-8K, and MATH.
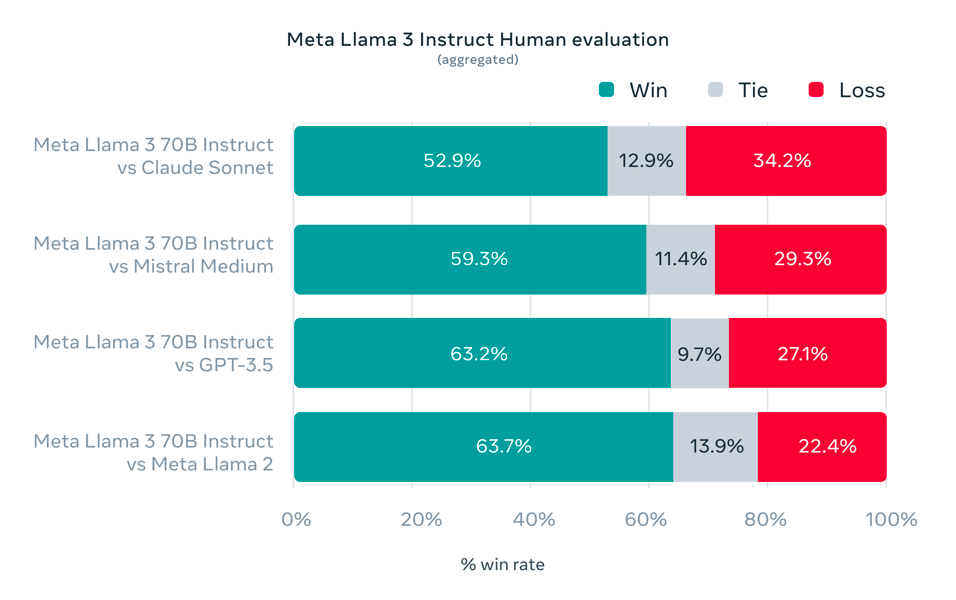
Human evaluation was conducted using a curated prompt set spanning common use cases, such as advice, brainstorming, coding, reasoning, and summarization. In human preference studies, the instruction-tuned Llama 3 70B model's performance was compared to other leading language models, as illustrated in aggregated comparisons.
Aggregated human evaluation bar chart, highlighting Meta Llama 3 70B Instruct's win, tie, and loss rates compared with Claude Sonnet, Mistral Medium, GPT-3.5, and Llama 2.
Llama 3 8B is intended for a broad spectrum of research and commercial applications. The instruction-tuned models are specifically optimized for assistant-like chat and dialogue scenarios, while pretrained models can be adapted for various natural language processing tasks, including text generation, summarization, information extraction, and code completion.
The Llama 3 technology underpins Meta's assistant, Meta AI, which integrates these models across Meta products such as Facebook, Instagram, WhatsApp, Messenger, and the web. While Llama 3 8B's core strengths currently focus on English language capability, ongoing efforts aim for enhanced multilingual performance in future iterations.
Responsible Deployment, Limitations, and Licensing
Responsible AI use is central in Llama 3's design. Meta provides a comprehensive Responsible Use Guide advising developers on best practices, including input and output filtering, content moderation, and adherence to regulatory standards. The system-level approach outlined emphasizes layered safeguards at the input, model, and output stages.
Despite these efforts, residual risks remain typical of large generative language models, such as the potential for inaccurate, biased, or unpredictable outputs. The model is static and trained on a fixed dataset, with its knowledge limited to information available prior to March 2023 for the 8B variant.
Llama 3 is released under the Meta Llama 3 Community License Agreement, which includes provisions for attribution, acceptable use, and restrictions on leveraging the model to develop other LLMs outside the Llama 3 ecosystem. Commercial usage for organizations with very large user bases may require further licensing terms, and developers are expected to comply with Meta’s Acceptable Use Policy.
Release Information and Model Variants
The Llama 3 8B and 70B models were publicly released on April 18, 2024, as detailed in Meta's official announcement. These initial releases include both base and instruction-tuned variants. Meta has indicated plans for ongoing development, including models with even larger parameter counts and expanded multilingual and multimodal capabilities.
For model iteration comparisons, Llama 3 models present performance differences over their Llama 2 counterparts in both efficiency and benchmark performance. Updated and future model releases, such as the Llama 3.1-8B, are planned with ongoing research.