Launch a dedicated cloud GPU server running Laboratory OS to download and run Llama 3.1 70B using any compatible app or framework.
Direct Download
Must be used with a compatible app, notebook, or codebase. May run slowly, or not work at all, depending on local system resources, particularly GPU(s) and available VRAM.
Open WebUI is an open-source, self-hosted web interface with a polished, ChatGPT-like user experience for interacting with LLMs. Integrates seamlessly with local Ollama installation.
The most full-featured web interface for experimenting with open source Large Language Models. Featuring a wide range of configurable settings, inference engines, and plugins.
Model Report
Meta / Llama 3.1 70B
Llama 3.1 70B is a transformer-based decoder language model developed by Meta with 70 billion parameters, trained on approximately 15 trillion tokens with a 128K context window. The model supports eight languages and demonstrates competitive performance across benchmarks for reasoning, coding, mathematics, and multilingual tasks. It is available under the Llama 3.1 Community License Agreement for research and commercial applications.
Explore the Future of AI
Your server, your data, under your control
The Llama 3.1 70B model is a large-scale generative language model developed by Meta as part of the Llama 3.1 model suite. Released on July 23, 2024, alongside companion models of 8B and 405B parameters, Llama 3.1 70B is designed to enable advanced natural language processing tasks across multiple languages and extended context lengths. The model is open-source under the Llama 3.1 Community License Agreement, reflecting Meta’s ongoing commitment to openness in artificial intelligence model development, as articulated in Meta’s open-source AI principles.
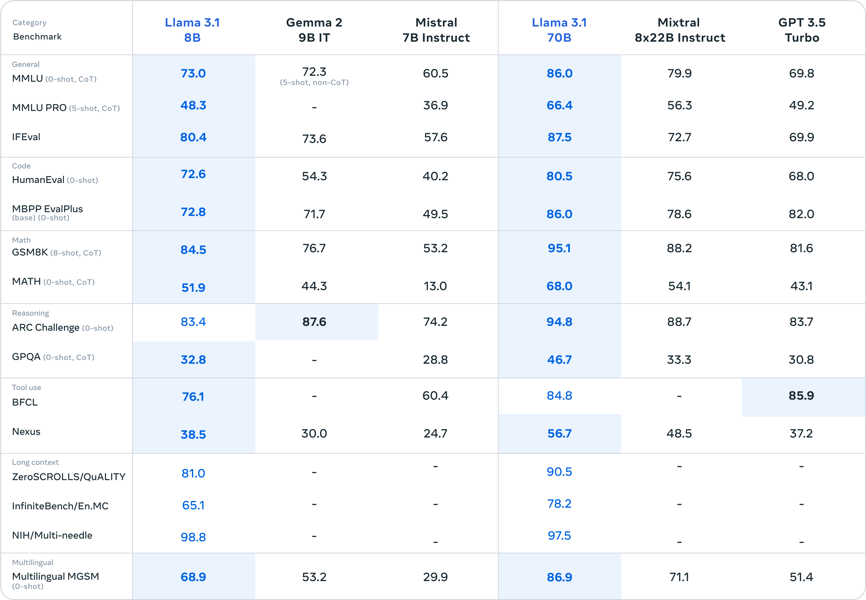
A comprehensive benchmark comparison of Llama 3.1 70B and other leading open large language models across general, code, math, reasoning, tool use, long-context, and multilingual tasks.
Llama 3.1 70B employs a transformer-based, decoder-only architecture with enhancements focused on training stability and inference scale. The model uses Grouped Query Attention (GQA) to increase inference speed and scalability, facilitating deployment in diverse research and production settings. Unlike mixture-of-experts strategies, Llama 3.1 maintains a unified architecture, which supports efficient supervised fine-tuning and alignment methodologies.
Instruction-tuned variants are aligned to human preferences for utility and safety through supervised fine-tuning (SFT), Direct Preference Optimization (DPO), and Rejection Sampling (RS). This alignment is intended to enhance the model's usefulness in dialogue and assistive applications.
Training Data and Procedures
Llama 3.1 70B was trained on approximately 15 trillion tokens collected from a wide array of publicly available online sources, with the dataset cut off at December 2023. The pre-training corpus emphasizes data diversity and quality, encompassing multiple languages and domains. Fine-tuning incorporates instruction datasets amassed from both human and synthetic sources, with more than 25 million synthetically generated samples used for refinement.
The iterative post-training process leverages SFT and DPO to generate increasingly high-quality synthetic data and adjust the balance between short- and long-context performance, supporting the model’s expanded 128K context window. This context length enables advanced use-cases such as long-document summarization and codebase analysis.
On widely recognized metrics such as MMLU, IFEval, HumanEval, GSM8K, and various multilingual and reasoning datasets, the model performs on par with, or above, many other open-source peers of comparable scale. For instance, in the published benchmarks, Llama 3.1 70B Instruct achieves:
83.6 on 5-shot MMLU macro-average,
80.5 on 0-shot HumanEval pass@1 (code generation),
95.1 on 8-shot GSM8K for grade-school math,
86.9 on multilingual MGSM for math reasoning in diverse languages.
These results reflect the model's aptitude for complex, real-world tasks, including code synthesis, multilingual conversation, robust reasoning, and effective tool manipulation. The model’s multilingual training covers English, German, French, Italian, Portuguese, Hindi, Spanish, and Thai, though coverage outside these languages is not officially supported by Meta without further fine-tuning and appropriate safeguards.
Applications and Use Cases
Llama 3.1 70B is suited for both research and production in a broad spectrum of natural language processing applications. Its enhanced instruction-following aligns well with assistant-style dialogue, chatbots, and virtual agents. The expanded context window facilitates tasks such as summarization of lengthy texts, complex document question-answering, and maintaining context over extended conversations.
Other prominent uses include code generation, scientific Q&A, data extraction, and knowledge retrieval. The model supports synthetic data generation and distillation workflows, enabling developers to build or refine smaller models using its outputs. Community-built applications have utilized preceding Llama models for educational bots, medical decision support (e.g., Meditron developed with Yale Medicine and EPFL), and organizing health records for secure communication in clinical settings.
Limitations and Responsible Use
As with all large language models, Llama 3.1 70B presents specific limitations and risks. High computational requirements may challenge individual developers seeking to fine-tune or deploy the model at scale. As a static model with a fixed training cutoff, Llama 3.1 does not incorporate real-time knowledge updates.
Meta advises that the model is only officially supported for eight languages, and use in other languages necessitates rigorous additional tuning and risk assessment. Model outputs, while filtered and aligned, may contain inaccuracies, biases, or potentially harmful content. Meta recommends employing the model as a component of a broader AI system with safety guardrails such as Llama Guard 3, Prompt Guard, and policy-based overlays.
Developers remain responsible for downstream system safety, including integration with tools, enforcing usage policies, and continued risk monitoring, particularly in areas such as CBRNE, child safety, and cybersecurity.
Licensing
Llama 3.1 70B is distributed under the Llama 3.1 Community License Agreement, which grants free, worldwide, non-exclusive rights for usage, reproduction, modification, and redistribution subject to attribution and compliance requirements. The license mandates clear labeling (e.g., "Built with Llama") and stipulates additional terms for platforms with over 700 million monthly users. It prohibits use in activities violating laws or ethical standards, mandates compliance with the Acceptable Use Policy, and restricts redistribution in sensitive domains. Derivative works created using Llama outputs must include “Llama” in the model name.
Related Models
Within the broader Llama 3.1 release, Meta introduced three models: 8B, 70B, and 405B parameters. The Llama 3.1 8B and 70B models are designed for accessibility and resource-efficient experimentation, while the 405B model represents a larger-scale research baseline. Each variant benefits from the same training improvements and architectural design.