Launch a dedicated cloud GPU server running Laboratory OS to download and run DeepSeek VL2 using any compatible app or framework.
Direct Download
Must be used with a compatible app, notebook, or codebase. May run slowly, or not work at all, depending on local system resources, particularly GPU(s) and available VRAM.
Open WebUI is an open-source, self-hosted web interface with a polished, ChatGPT-like user experience for interacting with LLMs. Integrates seamlessly with local Ollama installation.
The most full-featured web interface for experimenting with open source Large Language Models. Featuring a wide range of configurable settings, inference engines, and plugins.
Model Report
Deepseek AI / DeepSeek VL2
DeepSeek-VL2 is a series of Mixture-of-Experts vision-language models developed by DeepSeek-AI that integrates visual and textual understanding through a decoder-only architecture. The models utilize a SigLIP vision encoder with dynamic tiling for high-resolution image processing, coupled with DeepSeekMoE language components featuring Multi-head Latent Attention. Available in three variants with 1.0B, 2.8B, and 4.5B activated parameters, the models support multimodal tasks including visual question answering, optical character recognition, document analysis, and visual grounding capabilities.
Explore the Future of AI
Your server, your data, under your control
DeepSeek-VL2 is a series of large-scale Mixture-of-Experts (MoE) Vision-Language Models (VLMs) developed by DeepSeek-AI. DeepSeek-VL2 integrates vision and language understanding, with architectural and data-centric improvements over its predecessor, DeepSeek-VL. The model is optimized for various multimodal tasks, including visual question answering, optical character recognition (OCR), document analysis, visual grounding, and reasoning across both images and text. DeepSeek-VL2 was developed with objectives including performance and efficiency across multiple practical benchmarks and research challenges, as detailed in its Hugging Face Model Card and ArXiv paper.
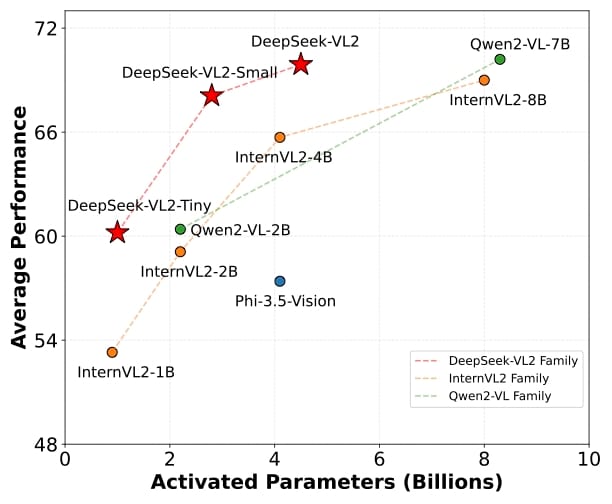
Comparison of average performance versus activated parameters among several vision-language models. DeepSeek-VL2 families (marked by red stars) are highlighted for their performance-to-size ratio.
DeepSeek-VL2 adopts a LLaVA-style decoder-only model structure, integrating a vision encoder, a vision-language adaptor, and a Mixture-of-Experts language model, as described in its model architecture. The vision encoder utilizes a single SigLIP-SO400M-384 model to process images via a dynamic tiling strategy, whereby high-resolution images are divided into local tiles of 384x384 pixels. This approach enables efficient handling of images with diverse aspect ratios while maintaining computational efficiency.
Once the vision encoder extracts features from image tiles, a vision-language adaptor compresses and projects these visual tokens into the language model's embedding space using a two-layer multilayer perceptron (MLP). Special tokens are inserted to demarcate tile and view boundaries, structuring the flow of visual data into the language model.
The language component is based on the DeepSeekMoE model series, which incorporates the Multi-head Latent Attention (MLA) mechanism. MLA facilitates the compression of key-value caches into latent vectors, substantially reducing memory and computational requirements during inference. Within the MoE framework, a global bias term per expert improves load balancing, further optimizing resource usage across multiple model variants.
Three major variants are available, distinguished by their activated parameter count: DeepSeek-VL2-Tiny (1.0 billion activated, 3 billion total parameters), DeepSeek-VL2-Small (2.8 billion activated, 16 billion total), and DeepSeek-VL2 (4.5 billion activated, 27 billion total). Additional information on these variants is available through their respective Hugging Face Models, DeepSeek-VL2-Small, and DeepSeek-VL2.
Training Methodology and Data
DeepSeek-VL2 is trained with a multi-stage pipeline designed to align, pretrain, and supervise the model on a diverse array of multimodal tasks, with training details available in its documentation. The initial alignment stage synchronizes the vision encoder with the pretrained language model using datasets such as ShareGPT4V. This step trains the vision-language adaptor, while the language model remains frozen.
In the vision-language pretraining phase, all model parameters are jointly optimized with a large-scale dataset comprising approximately 800 billion image-text tokens. The training sample mix is roughly 70% vision-language and 30% text-only, drawn from open-source repositories (e.g., WIT, OBELICS, WikiHow), in-house captioning pipelines, broad OCR datasets spanning both English and Chinese, visual question answering sources, and specialized datasets for visual grounding. Quality control mechanisms filter and augment training samples for robust multimodal learning.
Supervised fine-tuning further refines the model’s conversational and instruction-following abilities. This phase leverages curated multimodal datasets encompassing general VQA, OCR/document understanding, table/chart reasoning, mathematical problem-solving, visual grounding, and grounded conversation, in addition to text-only dialogue sources from DeepSeek-V2. During this stage, detailed reasoning steps and consistent answer formats are introduced, with further augmentation from in-house and public datasets to cover cultural, artistic, and real-world image knowledge.
Model training utilized the HAI-LLM platform, employing a combination of pipeline, tensor, and expert parallelism, alongside a dynamic load balancing scheme for handling image tiles. Training durations ranged from one to two weeks across model sizes.
Technical Capabilities
DeepSeek-VL2 exhibits various technical proficiencies across established multimodal tasks, with benchmark results available in its documentation. Its architecture enables high-resolution visual processing, document and chart understanding, and advanced visual grounding—where the model localizes objects within images based on category labels, descriptions, or even abstract concepts. A special <|grounding|> token allows the model to return grounded responses that include object locations, which is particularly valuable for applications in embodied AI and agent navigation.
The model maintains proficiency in optical character recognition, graphical user interface perception, multi-image reasoning, visual storytelling, and meme interpretation. DeepSeek-VL2 conducts cross-image reasoning by identifying objects of the same class in different visual contexts and supports web-to-code and plot-to-Python generation. Sparse computation enabled by the Mixture-of-Experts structure, the MLA mechanism, and the dynamic tiling strategy together allow it to manage complex visual inputs efficiently, balancing scale with performance.
Evaluation and Benchmarks
Evaluations compare DeepSeek-VL2 against other open-source vision-language models with equivalent or fewer activated parameters, as measured against benchmarks in OCR, general VQA, mathematics, and visual grounding, as detailed in the DeepSeek-VL2 ArXiv Paper. On DocVQA, ChartQA, InfoVQA, and TextVQA, DeepSeek-VL2-Tiny outperforms other models of its size, while DeepSeek-VL2-Small and the full DeepSeek-VL2 model achieve high scores relative to their respective parameter classes and peers.
Performance on classic grounding datasets like RefCOCO, RefCOCO+, and RefCOCOg is notable, exhibiting proficiency in object localization and contextual understanding. The design is effective for both English and Chinese tasks, and the use of in-house and public data sources in fine-tuning contributes to consistent generalization across domains.
Limitations
DeepSeek-VL2 retains some notable restrictions, which are detailed in its limitations and future work section. The model’s context window supports only a limited number of images per session—a characteristic slated for future expansion. It may encounter difficulty with blurry visual data or previously unseen objects, and continued improvements in reasoning and creative storytelling are areas of focus.
As common in VLM research, generating narratives with nuanced or genre-specific attributes remains challenging. Complex safety and alignment requirements can constrain the model's creative flexibility. Nevertheless, ongoing development aims to address these areas in subsequent versions.
Licensing and Release
DeepSeek-VL2 code is distributed under the MIT License, while the pre-trained model weights are subject to the DeepSeek Model License. Both licenses are publicly available, supporting research and commercial applications.