Launch a dedicated cloud GPU server running Laboratory OS to download and run DeepSeek V2 using any compatible app or framework.
Direct Download
Must be used with a compatible app, notebook, or codebase. May run slowly, or not work at all, depending on local system resources, particularly GPU(s) and available VRAM.
Open WebUI is an open-source, self-hosted web interface with a polished, ChatGPT-like user experience for interacting with LLMs. Integrates seamlessly with local Ollama installation.
The most full-featured web interface for experimenting with open source Large Language Models. Featuring a wide range of configurable settings, inference engines, and plugins.
Model Report
Deepseek AI / DeepSeek V2
DeepSeek V2 is a large-scale Mixture-of-Experts language model with 236 billion total parameters, activating only 21 billion per token. It features Multi-head Latent Attention for reduced memory usage and supports context lengths up to 128,000 tokens. Trained on 8.1 trillion tokens with emphasis on English and Chinese data, it demonstrates competitive performance across language understanding, code generation, and mathematical reasoning tasks while achieving significant efficiency improvements over dense models.
Explore the Future of AI
Your server, your data, under your control
DeepSeek-V2 is a large-scale Mixture-of-Experts (MoE) language model developed by DeepSeek-AI, with an emphasis on economical training and efficient inference. Introduced in 2024, it utilizes an advanced MoE architecture and innovative attention mechanisms to achieve high performance while substantially reducing computing demands. DeepSeek-V2 is designed for multilingual capabilities, particularly excelling in both English and Chinese, and supports extended context lengths for advanced natural language processing tasks.
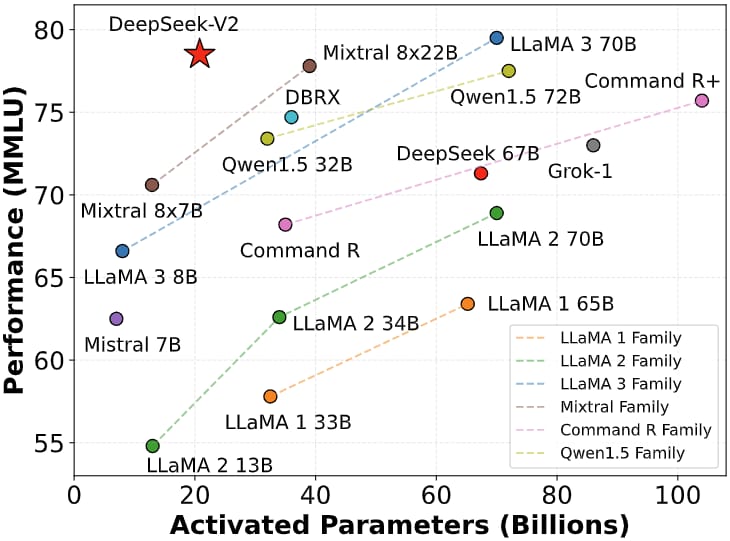
DeepSeek-V2 achieves high performance with fewer activated parameters per token, reflecting its architectural efficiency compared to other leading language models.
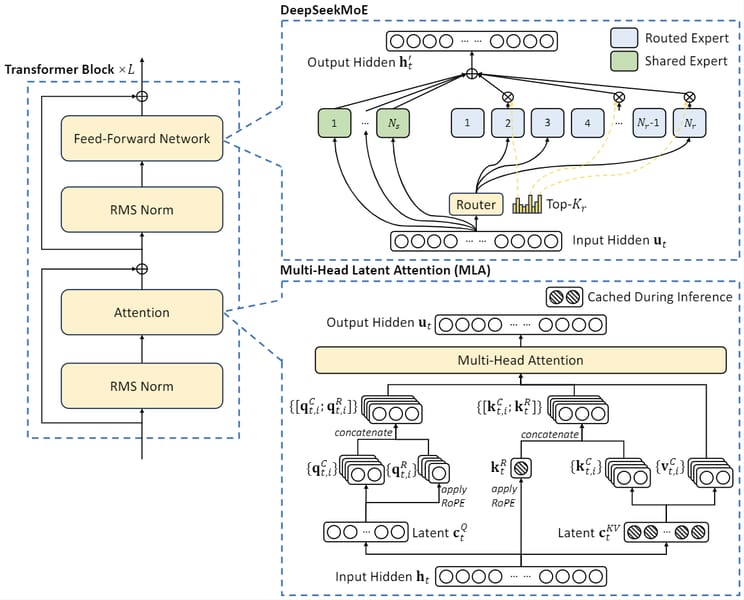
DeepSeek-V2 is built upon the Transformer framework but introduces several novel components aimed at maximizing efficiency and specialization. The model employs a sophisticated Mixture-of-Experts structure, known as DeepSeekMoE, which divides experts into finer segments and isolates shared experts to minimize redundancy. For each token, only a subset of the model's 236 billion total parameters—specifically, 21 billion parameters—are activated, optimizing both computational costs and memory requirements as detailed in the technical report.
A key innovation is the Multi-head Latent Attention (MLA) mechanism, which leverages low-rank key-value union compression techniques to significantly reduce the Key-Value (KV) cache required during inference. Unlike standard attention mechanisms, MLA achieves robust performance on par with multi-head attention but requires much less memory, resulting in faster and more scalable inference. The MLA is compatible with a decoupled Rotary Position Embedding (RoPE), enabling the model to handle long-context extensions efficiently.
DeepSeek-V2 incorporates device-limited routing, allocating experts across a fixed number of devices per token to control communication overhead. Auxiliary training losses—including expert-level, device-level, and communication balance losses—are used to ensure a balanced distribution of computation and mitigate potential bottlenecks. Furthermore, a training-time token-dropping strategy discards low-affinity tokens to keep the computational load within target budgets without undermining learning consistency.
Training Data, Procedures, and Optimization
DeepSeek-V2 is pretrained on a broad and diverse corpus comprising 8.1 trillion tokens, with deliberate emphasis on enhancing the quality and quantity of both English and Chinese data. The corpus is filtered for quality and contentious material, aiming to reduce data bias and improve downstream performance. Tokenization is handled using a Byte-level Byte-Pair Encoding (BBPE) tokenizer with a 100K vocabulary, designed to balance linguistic representation—Chinese tokens make up roughly 12% more of the corpus than English tokens, according to the DeepSeek GitHub.
Supervised fine-tuning (SFT) follows the initial pretraining and involves 1.5 million multi-domain conversational samples. Further preference alignment leverages reinforcement learning, employing Group Relative Policy Optimization (GRPO) to guide the model toward helpful, safe, and preference-aligned outputs. The optimization pipeline includes customized CUDA kernels, efficient routing algorithms, and techniques such as KV cache quantization (to FP8 or 6-bit average) to facilitate deployment and inference.
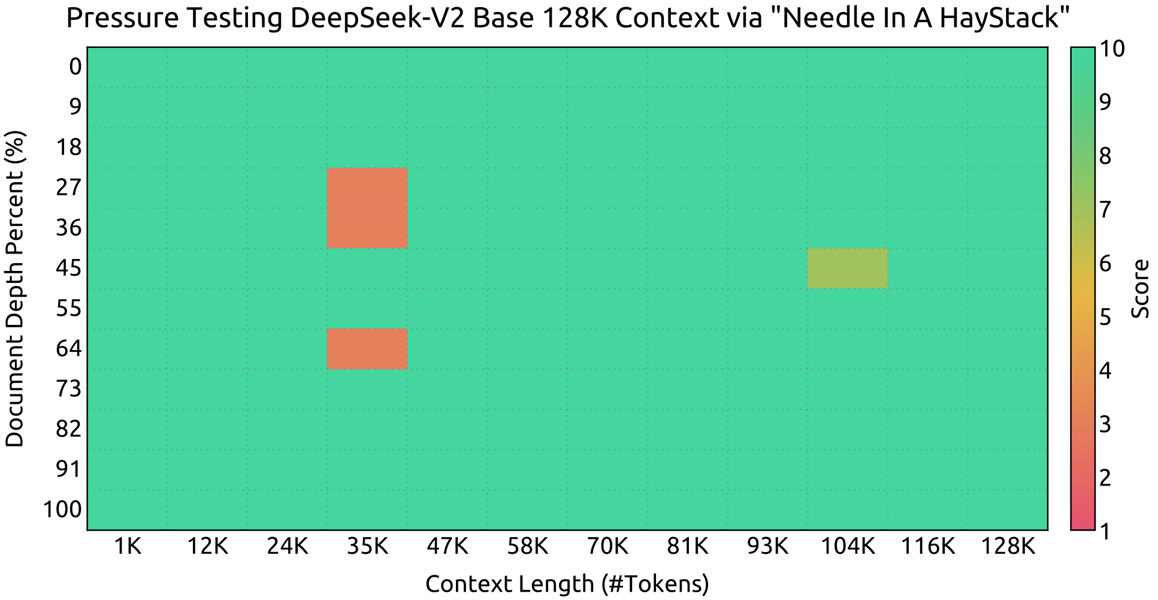
To expand the model's context capabilities, DeepSeek-V2 integrates YaRN, a RoPE variant, allowing it to process context windows up to 128,000 tokens. This is especially validated via "Needle In A Haystack" (NIAH) tests, where the model demonstrates robust retrieval across long contexts.
Pressure testing results reveal DeepSeek-V2's strong and consistent performance on the Needle In A Haystack (NIAH) benchmark across context windows up to 128K tokens.
DeepSeek-V2 demonstrates competitive results on standard benchmarks, outperforming its predecessor DeepSeek 67B and ranking highly among open-source models in both English and Chinese tasks. On the MMLU benchmark for general knowledge, DeepSeek-V2 matches the performance of state-of-the-art alternatives, while on Chinese-specific tasks (C-Eval and CMMLU) it achieves leading scores.
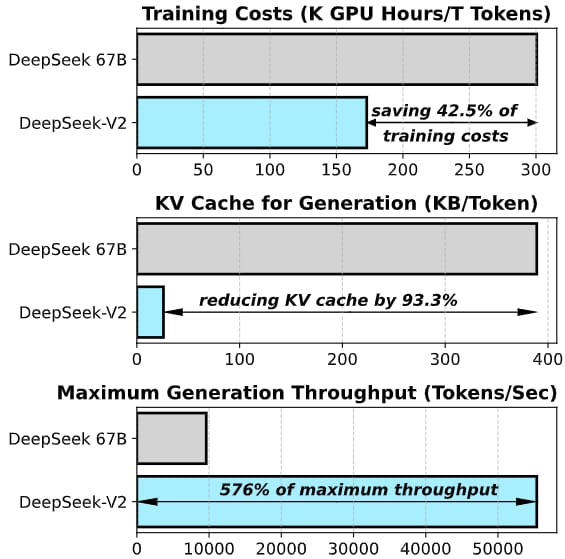
Efficiency improvements are a core focus. When compared to DeepSeek 67B, DeepSeek-V2 reduces training costs by 42.5%, cuts KV cache requirements by 93.3%, and boosts generation throughput by more than fivefold, as detailed in benchmark results. This enables higher token input and output rates, supporting large-scale deployments and extended context tasks.
DeepSeek-V2 significantly reduces training costs and resource consumption while achieving greater throughput than DeepSeek 67B, highlighting gains in parameter efficiency and inference speed.
Open-ended generation evaluation shows that DeepSeek-V2-Chat (RL version) delivers competitive results on benchmarks such as AlpacaEval 2.0 and MT-Bench—achieving a 38.9 length-controlled win rate and an 8.97 overall score, respectively. In Chinese, the model attains a 7.91 score on AlignBench, placing it above many open- and closed-source models for language understanding.
DeepSeek-V2 Chat RL demonstrates competitive open-ended generation abilities on MTBench and AlpacaEval 2.0 benchmarks.
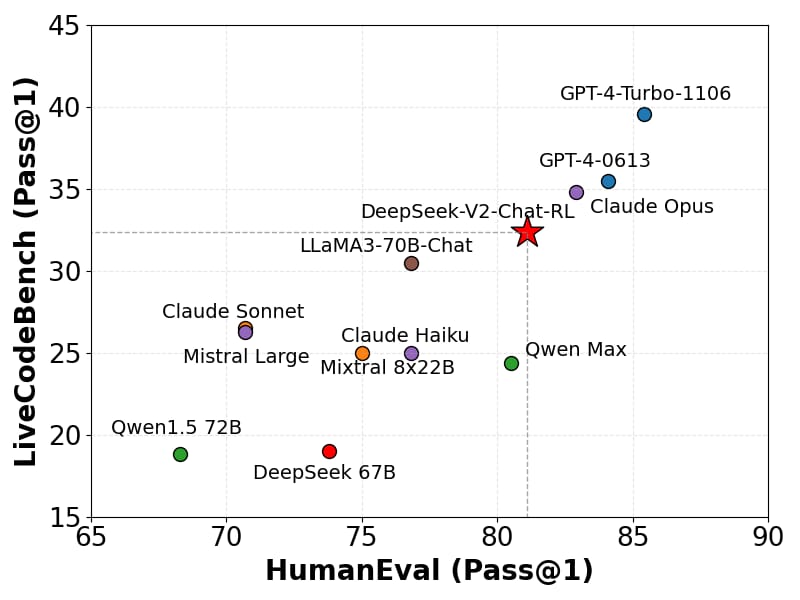
Coding proficiency is likewise robust, with DeepSeek-V2-Chat RL achieving strong Pass@1 scores on both LiveCodeBench and HumanEval, closely matching leading models in code generation and reasoning.
Performance of DeepSeek-V2 Chat RL on code benchmarks demonstrates parity with top-tier models on HumanEval and LiveCodeBench tasks.
DeepSeek-V2 is applied in a range of language tasks, including text and chat completion, general language understanding, reading comprehension, closed-book question answering, reference disambiguation, code synthesis, and mathematical problem solving. Its bilingual training on a large-scale, high-quality corpus ensures strong adaptability for tasks in both English and Chinese, according to DeepSeek official documentation.
The DeepSeek model suite also includes DeepSeek 67B, a dense predecessor, and DeepSeek-V2-Lite, a smaller variant with 15.7 billion parameters and similar core innovations targeting research and lightweight applications.
Limitations and Licensing
DeepSeek-V2, like most large language models, is restricted by its training cutoff and may generate unverified or inaccurate information. Its capabilities outside English and Chinese are limited, reflecting the language composition of its training dataset. While open-ended reasoning is strong, certain tasks—especially those requiring world knowledge beyond 2024 or languages not represented in training—may pose challenges. The alignment process can marginally reduce performance on some standard benchmarks, a phenomenon recognized as “alignment tax.” As of its 2024 release, DeepSeek-V2 is text-only and does not process images or other modalities.
The model is released with an MIT License for code and is subject to a dedicated Model Agreement for weights and commercial use. The model supports commercial applications under the specified terms.