Launch a dedicated cloud GPU server running Laboratory OS to download and run Qwen3 8B using any compatible app or framework.
Direct Download
Must be used with a compatible app, notebook, or codebase. May run slowly, or not work at all, depending on local system resources, particularly GPU(s) and available VRAM.
Open WebUI is an open-source, self-hosted web interface with a polished, ChatGPT-like user experience for interacting with LLMs. Integrates seamlessly with local Ollama installation.
The most full-featured web interface for experimenting with open source Large Language Models. Featuring a wide range of configurable settings, inference engines, and plugins.
Model Report
Alibaba Cloud / Qwen3 8B
Qwen3-8B is a dense transformer-based language model developed by Alibaba Cloud featuring 8.2 billion parameters across 36 layers with Grouped Query Attention and 32,768-token native context length. The model supports hybrid thinking capabilities, enabling dynamic switching between systematic reasoning and rapid response modes, and was trained on 36 trillion tokens across 119 languages using multi-stage optimization including distillation from larger Qwen3 variants.
Explore the Future of AI
Your server, your data, under your control
Qwen3-8B is a dense large language model (LLM) in the Qwen3 series, developed by the Qwen team at Alibaba Cloud. Released in 2024, Qwen3-8B is one of a suite of six dense models and two Mixture-of-Experts (MoE) variants in Qwen3, made available under the Apache 2.0 license. The model features hybrid thinking, extensive multilingual support, and agentic capabilities. Its technical report, licensing information, and documentation are all provided publicly for research and development purposes.
Official logo of the Qwen3 series, representing its branding and technological identity.
Qwen3-8B is a dense transformer-based model with 8.2 billion parameters—6.95 billion of which are non-embedding parameters—spanning 36 layers. The model employs 32 attention heads for queries and 8 for key/value, supported by Grouped Query Attention (GQA), which optimizes efficiency and scaling. Qwen3-8B natively processes contexts up to 32,768 tokens, extendable to 131,072 tokens through the Yet another RoPE extension (YaRN) approach for handling long sequences.
In terms of architectural advancements, Qwen3-8B follows the innovations introduced in Qwen2.5, such as SwiGLU activations, rotary positional embeddings (RoPE), and RMSNorm with pre-normalization. However, it diverges from its predecessors by removing QKV-bias and integrating QK-Norm into the attention mechanism, improving training stability. The tokenizer is based on Qwen's byte-level byte-pair encoding (BBPE) with a substantial vocabulary of 151,669 tokens, supporting a broad spectrum of languages and symbols, and robust encoding of diverse textual data.
A distinguishing feature is Qwen3-8B's hybrid thinking capability. The model supports dynamic switching between two operational modes: a "Thinking" mode, which enables systematic, step-by-step reasoning for complex scenarios, and a "Non-thinking" mode geared toward rapid, concise responses suitable for straightforward queries. This is facilitated via specialized chat templates and flags, enabling users to tailor model outputs based on the cognitive demands of a task.
Visualization of the Qwen3 model architecture, highlighting key components and processing workflow.
Qwen3-8B was trained on a significantly enlarged and diverse dataset compared to Qwen2.5, featuring approximately 36 trillion tokens drawn from web sources and document collections across 119 languages and dialects. The pre-training was organized into three progressive stages: a general language development stage, a specialized reasoning stage focusing on science, technology, engineering, and mathematics (STEM), and a long-context adaptation stage that incorporated RoPE optimizations for extended sequence understanding.
The post-training regimen adopted a multi-stage approach. Initial fine-tuning on curated long Chain-of-Thought (CoT) datasets instilled deep reasoning abilities. This was followed by reinforcement learning using rule-based reward systems, leveraging GRPO (Gradient-based Reinforcement Policy Optimization) for effective parameter updates. To merge the two operational modes, a mode fusion stage blended instruction-based and CoT-generated data, equipping the model with both comprehensive reasoning and quick-response capabilities. Subsequent reinforcement learning on over 20 general-domain tasks aimed to further align the model with human preferences, correct undesirable behaviors, and refine its instructional and agentic proficiency.
For smaller variants like Qwen3-8B, a strong-to-weak distillation approach was used. Here, the model distilled knowledge from larger Qwen3 architectures such as Qwen3-32B and Qwen3-235b-a22b, effectively inheriting their reasoning skills while reducing computational requirements.
Illustration of the training methodology used for Qwen3 models, showing the progression through different stages of development.
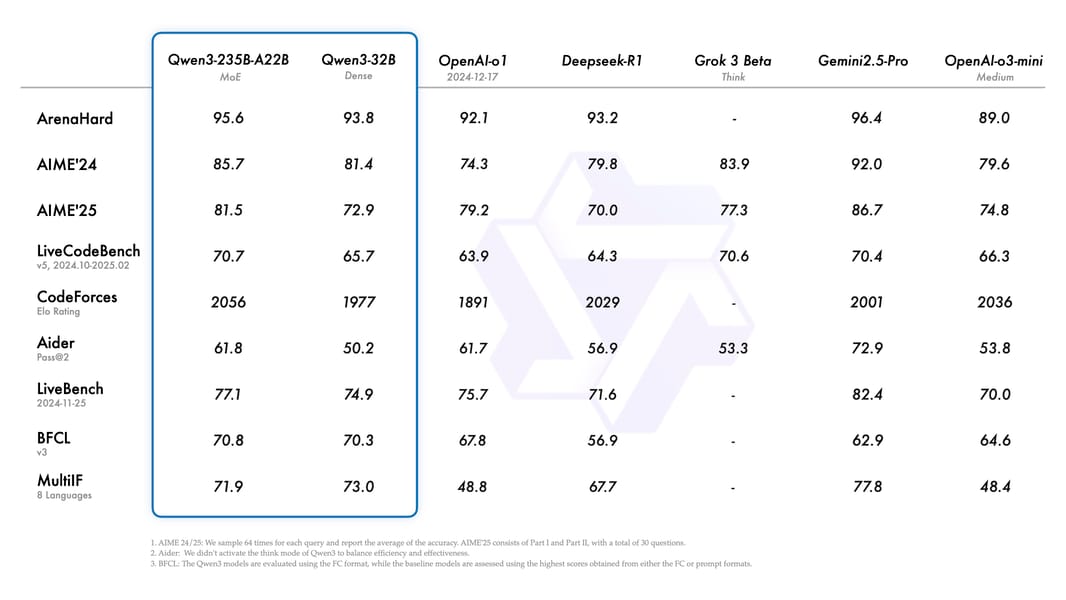
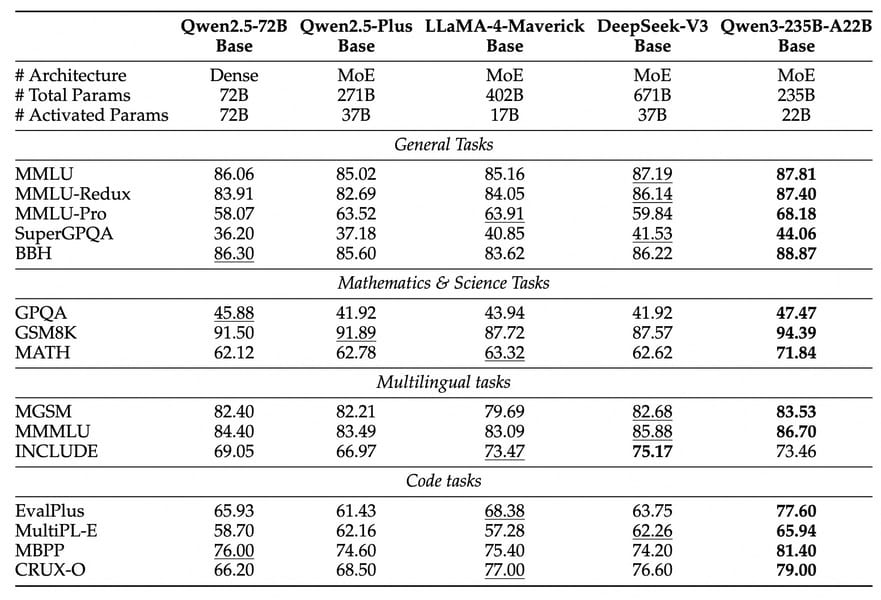
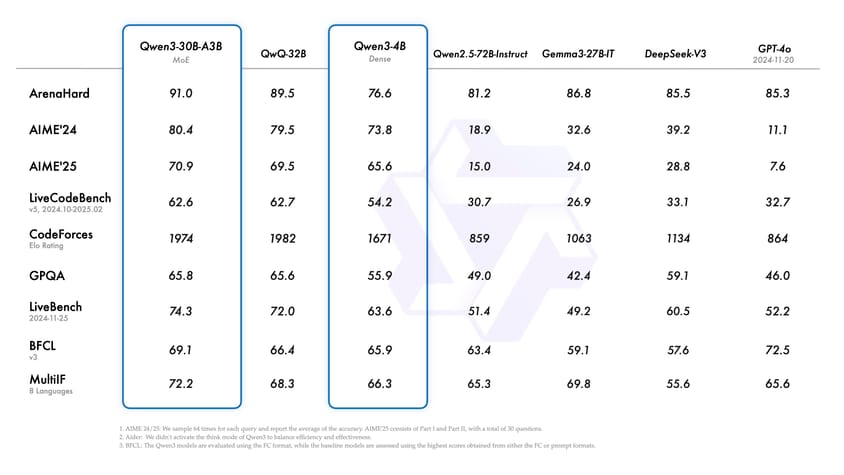
Qwen3-8B performs well in benchmarks compared to similarly-sized and larger models in both the Qwen2.5 family and other open-source models. In pre-training evaluations, Qwen3-8B compares favorably with models such as Qwen2.5-14B-Base across general tasks (including MMLU, MMLU-Redux, SuperGLUE), STEM reasoning (GPQA, GSM8K, MATH), coding benchmarks (EvalPlus, MBPP, CRUX-O), and multilingual capabilities.
Post-training results highlight the advantage of Qwen3-8B's hybrid thinking paradigm. In "Thinking" mode, it performs well in tasks requiring chain-of-thought and logical deduction when compared to other models from different families in specialized benchmarks. In "Non-thinking" mode, it delivers rapid outputs, maintaining competitive performance on standard retrieval and comprehension benchmarks. The model's long-context capabilities, as measured by the RULER benchmark, are robust, with the 8B variant achieving average scores over 89 in non-thinking mode—indicative of its sequence memory and retrieval capabilities.
Comprehensive benchmark results comparing Qwen3-8B and related models to other leading architectures across general language, STEM, multilingual, and coding tasks.
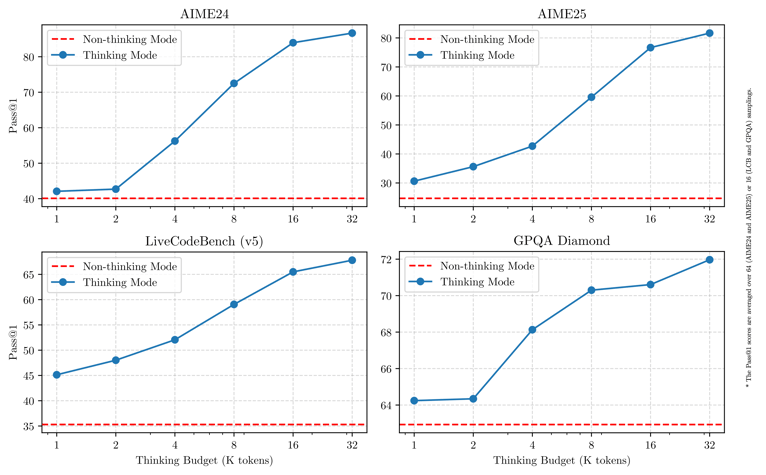
The hybrid thinking budget, which determines the amount of reasoning allocated per query, affects performance across different types of tasks, as shown in analyses of tasks such as AIME24 and LiveCodeBench.
Applications and Use Cases
Qwen3-8B's design supports a breadth of practical applications. Its reasoning capabilities enable performance in complex problem solving, including advanced mathematics, structured logical deduction, and code generation. The fast-response non-thinking mode is particularly suited for conversational agents, real-time chat applications, and situations where latency is a concern.
The model's coverage of 119 languages and dialects opens opportunities in multilingual instruction, translation, and global applications. Enhanced agentic abilities facilitate its integration into systems requiring autonomous tool usage or multi-step task management. Due to its architecture and distillation techniques, Qwen3-8B is also appropriate for resource-constrained or local environments, allowing deployment across a variety of platforms.
Demonstration of Qwen3's agentic capabilities, exemplifying its multi-step planning and tool interaction in a simulated environment. [Source]
Limitations
Despite its broad capabilities, Qwen3-8B presents several trade-offs. In some retrieval-focused tasks, the inclusion of thinking-mode content can marginally impair extraction accuracy compared to non-thinking mode outputs. The fusion of general reinforcement learning and hybrid thinking can also result in slight decreases in performance on highly specialized benchmarks, reflecting a compromise with overall versatility. Additionally, most open-source deployments utilize static YaRN, where scaling factors for long context handling remain constant, potentially affecting short-document performance. It is recommended to enable rope scaling only when processing exceptionally long sequences.
Model Family and Licensing
Qwen3-8B is part of a broader ecosystem, including both dense (Qwen3-0.6B, Qwen3-1.7B, Qwen3-4B, Qwen3-8B, Qwen3-14B, Qwen3-32B) and Mixture-of-Expert models (Qwen3-235B-A22B, Qwen3-30B-A3B). Dense models are comparable in performance to earlier Qwen2.5 variants of higher parameter counts, while MoE models achieve similar results with fewer activated parameters due to architectural efficiencies. The Qwen3 model weights and code are openly available under the Apache 2.0 license, facilitating unrestricted academic and industrial research.
Overview of the complete Qwen3 model family, showing the relationship between different variants and their key characteristics.