Launch a dedicated cloud GPU server running Laboratory OS to download and run Qwen3 235B A22B using any compatible app or framework.
Direct Download
Must be used with a compatible app, notebook, or codebase. May run slowly, or not work at all, depending on local system resources, particularly GPU(s) and available VRAM.
Open WebUI is an open-source, self-hosted web interface with a polished, ChatGPT-like user experience for interacting with LLMs. Integrates seamlessly with local Ollama installation.
The most full-featured web interface for experimenting with open source Large Language Models. Featuring a wide range of configurable settings, inference engines, and plugins.
Model Report
Alibaba Cloud / Qwen3 235B A22B
Qwen3-235B-A22B is a Mixture-of-Experts language model developed by Alibaba Cloud's Qwen team, featuring 235 billion total parameters with 22 billion activated per inference step. The model offers dual operational modes—"thinking" for complex reasoning and "non-thinking" for rapid responses—enabling users to balance computational depth with inference speed. Trained on 36 trillion tokens across 119 languages, it supports advanced agentic workflows and demonstrates competitive performance on mathematical, coding, and multilingual benchmarks.
Explore the Future of AI
Your server, your data, under your control
Qwen3-235B-A22B is a flagship large language model (LLM) from the Qwen3 series, developed by the Qwen team at Alibaba Cloud. Released on April 29, 2025, this model employs a Mixture-of-Experts (MoE) architecture to efficiently balance high-performance reasoning and rapid, low-latency inference. Distinctively, Qwen3-235B-A22B offers both "thinking" and "non-thinking" operational modes, enabling users to tailor computational resource allocation and model depth according to the complexity of their tasks. The model features advanced multilingual and agentic support, extensive pretraining, and a strong alignment with human preferences, situating it at the forefront of open-weight LLMs Qwen blog announcement.
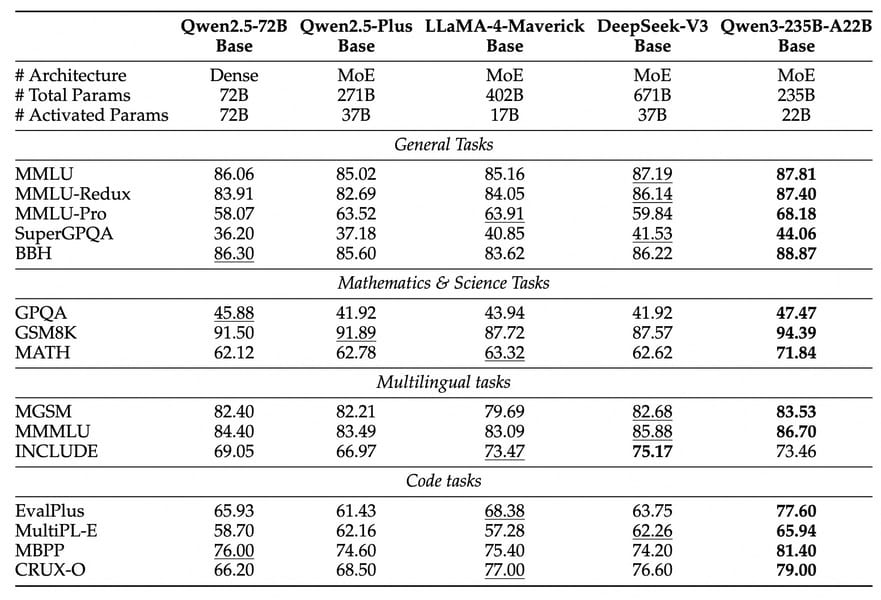
A comprehensive benchmark table showing Qwen3-235B-A22B's performance across tasks such as general language understanding, mathematics, and coding in comparison with other state-of-the-art models.
Qwen3-235B-A22B is built as a causal language model with a Mixture-of-Experts (MoE) foundation, containing 235 billion total parameters, with 22 billion activated per inference step Qwen3 GitHub. The network consists of 94 transformer layers, utilizing 128 experts—eight of which are chosen dynamically for each input token. This structure enables efficient scaling by activating only a fraction of the parameters per input, dramatically reducing computational overhead while maintaining robust performance.
The model integrates several modern architectural components, including Grouped Query Attention (GQA), SwiGLU activation, Rotary Positional Embeddings (RoPE) with an advanced frequency scaling method, and RMSNorm pre-normalization. Unlike previous Qwen2.5-MoE iterations, Qwen3-MoE omits shared experts and employs global-batch load balancing to encourage specialized expert behaviors. The attention mechanism introduces QK-Norm for improved stability during training. The tokenizer is based on byte-level byte-pair encoding (BBPE) with a vocabulary of over 151,000 tokens, supporting native context windows of 32,768 tokens, extendable to 131,072 tokens using the Yet another RoPE (YaRN) method Qwen ReadTheDocs.
Training Regime and Data Sources
Qwen3-235B-A22B underwent a multi-phase pretraining and post-training process to achieve both advanced reasoning and versatile instruction-following capabilities Qwen3 technical overview. Pretraining spanned approximately 36 trillion tokens, double the data size of its predecessor, and included text from diverse web sources and documents extracted via Qwen2.5-VL. The dataset spans 119 languages and dialects, substantially expanding the model's multilingual applicability.
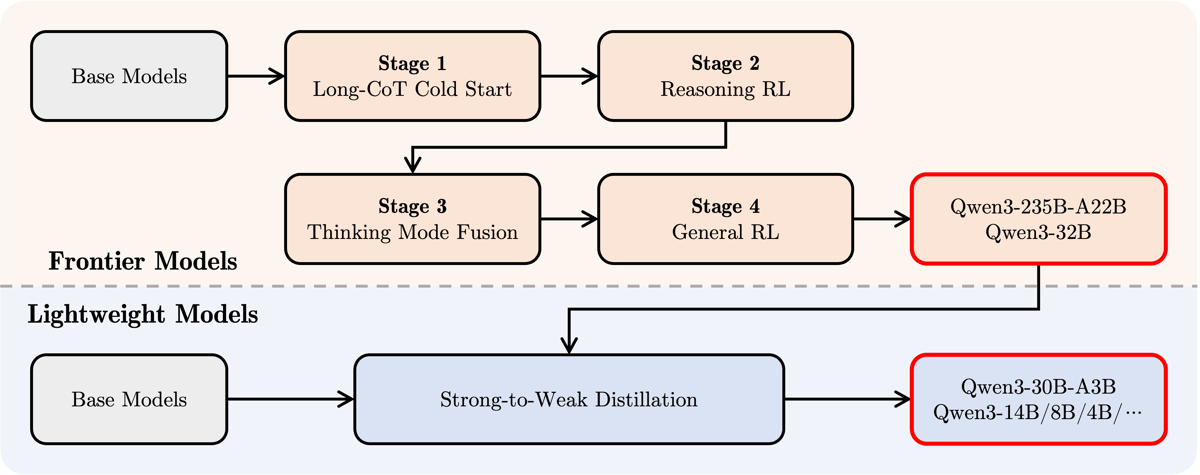
The pretraining was divided into three stages: a general language modeling phase to build foundational skills, a reasoning-focused phase emphasizing STEM, math, and coding, and a long-context phase increasing the model's ability to manage and reason over extended sequences. Post-training included four distinct stages: cold start on long chain-of-thought (CoT) data, reinforcement learning centered on reasoning, "thinking mode fusion" to harmonize step-by-step and rapid-response behaviors, and a final general RL pass for further alignment and correction of undesirable outputs.
A specialized "strong-to-weak" distillation process was employed to efficiently transfer knowledge from larger models, such as Qwen3-235B-A22B, into the smaller Qwen3 variants, maximizing training efficiency and preserving advanced reasoning capabilities.
Flowchart illustrating the two major Qwen3 training pipelines: multi-stage post-training for 'Frontier' models, and strong-to-weak distillation for 'Lightweight' models. This diagram outlines the processes producing both Qwen3-235B-A22B and its smaller model variants.
A defining feature of Qwen3-235B-A22B is its dual operational paradigm: "thinking mode" and "non-thinking mode" Qwen ReadTheDocs. In thinking mode, the model generates intermediate step-by-step reasoning before finalizing its response, making it highly suitable for complex problem-solving, such as mathematics, logic puzzles, or multi-step code generation. Non-thinking mode, in contrast, provides instantaneous, direct answers optimized for fast, interactive applications. Users can control this behavior at inference time, either globally or within specific conversation turns using prompt tokens (e.g., /think or /no_think). An adjustable "thinking budget" mechanism allows for dynamic trade-offs between inference time and output quality.
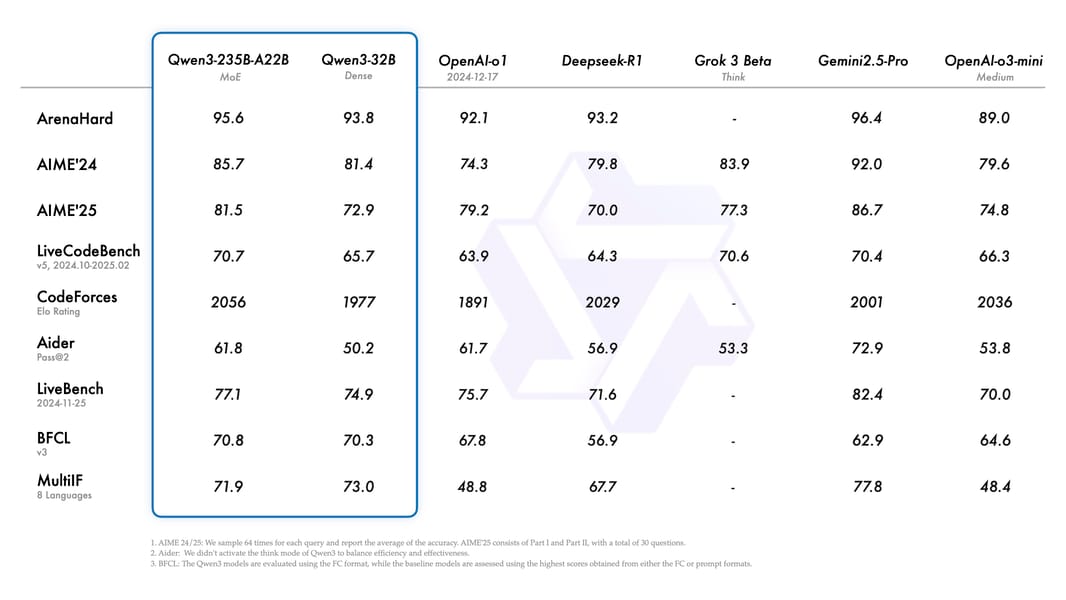
Detailed chart summarizing benchmark evaluations of Qwen3-235B-A22B and related models, demonstrating its performance on a range of reasoning, agentic, and language tasks.
Qwen3-235B-A22B is also equipped for advanced agentic workflows and multi-agent cooperation. Enhanced tool-calling and integration capabilities are supported through its cooperation with the Multi-Agent Cooperation Platform (MCP), expanding usability in automated reasoning, coding, and dynamic process automation.
Demonstration of Qwen3's agentic capabilities, illustrating how the model dynamically interacts with external tools and handles reasoning within an MCP environment. [Source]
Evaluation, Benchmarks, and Limitations
In standardized evaluations, Qwen3-235B-A22B demonstrated leading performance among open-weight models, matching or exceeding the results of proprietary systems such as DeepSeek-R1, OpenAI-o1, Grok-3 Beta, and Gemini2.5-Pro, especially on benchmarks testing complex reasoning, mathematics, and programming skills Qwen3 benchmark data. On the AIME'24 mathematics competition, for example, Qwen3-235B-A22B achieved a score of 85.7, and on LiveCodeBench v5 it attained a score of 70.7. Non-thinking mode benchmarks further establish its competitive rapid-response capabilities.
The model's multilingual proficiency spans 119 languages. On the Belebele benchmark, covering 80 languages, Qwen3 models performed comparably to other leading multilingual foundations.
Limitations of Qwen3-235B-A22B include potential performance degradation when using greedy decoding in thinking mode and trade-offs in areas such as STEM or code following the fusion of thinking and non-thinking behaviors. Additionally, static use of the YaRN context extension method may negatively impact results on short texts unless carefully configured.
Applications and Use Cases
Qwen3-235B-A22B's hybrid thinking framework, agentic capabilities, and broad language support enable a wide range of applications. These include complex mathematical reasoning and logic, competitive programming and code generation, agent-based workflows requiring tool integration, general-purpose conversational chat, creative writing, and multilingual instruction following Qwen3 technical overview. The versatile operation modes ensure suitability for both latency-sensitive environments and tasks that demand rigorous step-wise reasoning.
Model Family and Development
The Qwen3 series comprises both MoE and dense variants. The MoE line includes Qwen3-235B-A22B (235B total, 22B active parameters) and Qwen3-30B-A3B, while dense models are offered at parameter scales from 0.6B up to 32B. Strong-to-weak distillation has been utilized to create lightweight variants capable of outperforming larger baseline models in several domains.
The official Qwen3 logo, representing the visual identity of the model family across documentation and repositories.
Qwen3-235B-A22B and its associated models are released under the Apache 2.0 License, supporting open research, development, and deployment. Extensive documentation, code, and model checkpoints are available through the official Qwen3 GitHub, Hugging Face, ModelScope, and related repositories.