Launch a dedicated cloud GPU server running Laboratory OS to download and run DeepSeek R1 using any compatible app or framework.
Direct Download
Must be used with a compatible app, notebook, or codebase. May run slowly, or not work at all, depending on local system resources, particularly GPU(s) and available VRAM.
Open WebUI is an open-source, self-hosted web interface with a polished, ChatGPT-like user experience for interacting with LLMs. Integrates seamlessly with local Ollama installation.
The most full-featured web interface for experimenting with open source Large Language Models. Featuring a wide range of configurable settings, inference engines, and plugins.
Model Report
Deepseek AI / DeepSeek R1
DeepSeek R1 is a large language model developed by DeepSeek AI that employs a Mixture-of-Experts architecture with 671 billion total parameters and 37 billion activated during inference. The model utilizes reinforcement learning and supervised fine-tuning to enhance reasoning capabilities across mathematics, coding, and logic tasks, achieving competitive performance on benchmarks including 90.8 on MMLU and 97.3 on MATH-500.
Explore the Future of AI
Your server, your data, under your control
DeepSeek-R1 is a large language model (LLM) designed to advance reasoning abilities in natural language processing applications. Developed through a training strategy centered on large-scale reinforcement learning, DeepSeek-R1 introduces methodical incentives to enhance complex reasoning skills across diverse domains such as mathematics, coding, logic, and general knowledge tasks. The model builds upon an earlier version, DeepSeek-R1-Zero, and integrates additional supervised fine-tuning stages for improved reliability, coherence, and language consistency, as detailed in the DeepSeek-R1 technical report and on the DeepSeek-R1 Hugging Face page.
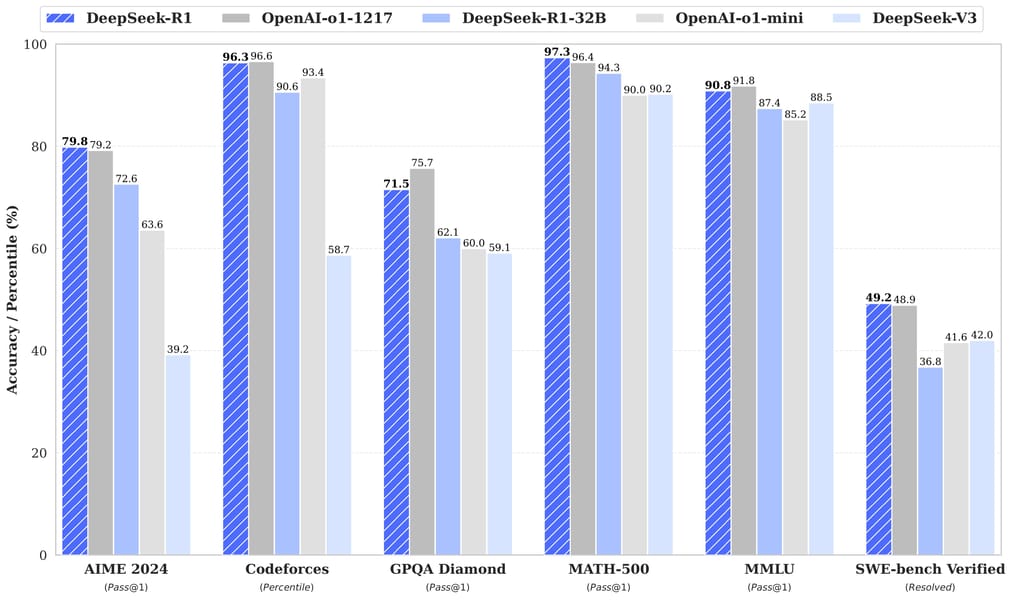
Benchmark comparison of DeepSeek-R1 with OpenAI-o1 and other prominent models, showing evaluation results across reasoning, coding, and math tasks.
DeepSeek-R1 is structured on the DeepSeek-V3 model, employing a Mixture-of-Experts (MoE) architecture that comprises 671 billion total parameters, with 37 billion parameters activated during inference. The model supports a context length of up to 128,000 tokens, facilitating the processing of extended prompts and documents, as described in the DeepSeek-R1 model card and its technical details.
The training process is organized into several key stages. Initially, DeepSeek-R1-Zero is produced through reinforcement learning directly applied to DeepSeek-V3-Base, demonstrating the viability of RL-based reasoning incentives on language models. However, DeepSeek-R1-Zero experienced issues such as reduced readability and language mixing.
To address these shortcomings, DeepSeek-R1 introduces a "cold start" phase where supervised fine-tuning (SFT) is conducted using a dataset of long chain-of-thought (CoT) examples curated for readability and accuracy. This is followed by large-scale RL, utilizing rule-based and language consistency rewards targeted at reasoning performance. Subsequent supervised fine-tuning incorporates datasets generated via RL and rejection sampling to further generalize the model's abilities, with additional RL alignment steps designed to optimize helpfulness and harmlessness in responses, according to the DeepSeek-R1 technical report.
A notable innovation in the DeepSeek-R1 training pipeline is the use of Group Relative Policy Optimization (GRPO), a reinforcement learning framework that omits the need for a critic model and estimates baselines from group scores to improve training efficiency. The reward system is primarily rule-based, assessing accuracy, output format adherence, and language consistency, especially within chain-of-thought reasoning, as discussed in the technical documentation.
Benchmark Performance and Evaluation
Comprehensive evaluation indicates that DeepSeek-R1 achieves competitive results, and in several cases, strong results on a range of publicly recognized benchmarks for reasoning, coding, mathematics, and multilingual tasks. Assessments are conducted with a maximum generation length of 32,768 tokens, a temperature setting of 0.6, and a top-p value of 0.95, generating multiple responses for robust estimation, as shown in the benchmark data.
In reasoning benchmarks, the model achieves a MMLU (Massive Multitask Language Understanding) score of 90.8 in Pass@1 accuracy, and 92.9 on MMLU-Redux (EM), frequently matching or exceeding results from models such as OpenAI-o1-1217 and GPT-4o.
On mathematical tasks, DeepSeek-R1 attains 79.8 on AIME 2024 (Pass@1) and 97.3 on MATH-500 (Pass@1), ranking among other leading models.
Coding capabilities are reflected in a 65.9 score on LiveCodeBench (Pass@1-COT) and a 96.3 percentile ranking on Codeforces.
The model also performs strongly on Chinese NLP benchmarks, including 92.8 on CLUEWSC and 91.8 on C-Eval. Detailed results are available on the DeepSeek-R1 Hugging Face page and in the technical report.
Training Methodology and Datasets
DeepSeek-R1’s advancement in reasoning stems from its emphasis on reinforcement learning and carefully curated training datasets. The cold-start data stage utilizes thousands of long chain-of-thought examples, collected via advanced prompting techniques and output refinement, as initial supervised fine-tuning material. This ensures the model acquires not just technical problem-solving abilities but also human-readable and logically organized responses.
The main RL phase applies GRPO with rule-based rewards. Accuracy is measured through answer formats (such as boxed answers in mathematics or passing code tests), while special format constraints, like enclosing reasoning within tags, are enforced. Language consistency is specifically incentivized to prevent undesirable language mixing, which had been an issue in earlier iterations, as outlined in the reward modeling discussion.
As RL converges, rejection sampling is used to gather a new batch of high-quality SFT data, combining approximately 600,000 reasoning-focused and 200,000 non-reasoning samples, covering tasks such as creative writing, factual question answering, and translation. These stages are supplemented with alignment steps to enhance overall interaction quality and response safety, as described in the data and pipeline details.
Model Family and Distilled Variants
The DeepSeek-R1 family includes precursor and derived models optimized for various scales and applications:
DeepSeek-R1-Zero is the pure RL-based precursor that validated the efficacy of reward-driven reasoning but exhibited readability limitations, as specified on its Hugging Face page.
DeepSeek-R1-Distill models are a collection of compact, dense models distilled from DeepSeek-R1, based on architectures such as Qwen and Llama. These models effectively transfer reasoning patterns from the original large-scale model into architectures with 1.5B to 70B parameters. Distilled models achieve notable results on memory, math, and code tasks, demonstrating the feasibility of large-model distillation for deployment efficiency, as detailed in the model overview and results and the technical report.
Limitations
Despite its advancements, DeepSeek-R1 has certain limitations. Compared to DeepSeek-V3, it may underperform in extended multi-turn conversations, function calling, intricate role-playing, and exact structured outputs (like JSON). While trained to operate in both Chinese and English, instances of language mixing remain, particularly for queries issued in less commonly supported languages. The model also exhibits prompt sensitivity; performance depends on precise, zero-shot instruction formulation, and routine use of few-shot prompting can degrade response quality. In addition, improvements in software engineering benchmarks are constrained by long evaluation cycles limiting RL efficiency, and the model demonstrates higher refusal rates in certain safety-aligned settings, as discussed in the limitations section.
Licensing and Publication
The DeepSeek-R1 series—including its codebase and pre-trained model weights—is released under the MIT License, permitting both commercial and academic use, as well as modification and further model distillation. License details are available on GitHub and the DeepSeek-R1 Hugging Face page. Variants distilled from other architectures (such as Qwen or Llama) inherit their respective upstream licenses, including Apache 2.0 for Qwen-based models and Llama’s custom agreements for Llama-derived variants.
DeepSeek-R1 is introduced in the research publication “DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning,” slated for 2025 release with the preprint available on arXiv.