Launch a dedicated cloud GPU server running Laboratory OS to download and run DeepSeek V3 using any compatible app or framework.
Direct Download
Must be used with a compatible app, notebook, or codebase. May run slowly, or not work at all, depending on local system resources, particularly GPU(s) and available VRAM.
Open WebUI is an open-source, self-hosted web interface with a polished, ChatGPT-like user experience for interacting with LLMs. Integrates seamlessly with local Ollama installation.
The most full-featured web interface for experimenting with open source Large Language Models. Featuring a wide range of configurable settings, inference engines, and plugins.
Model Report
Deepseek AI / DeepSeek V3
DeepSeek V3 is a Mixture-of-Experts language model with 671 billion total parameters and 37 billion activated per token, developed by DeepSeek-AI. The model features Multi-head Latent Attention, auxiliary-loss-free load balancing, and FP8 mixed-precision training. Trained on 14.8 trillion tokens with a 128,000-token context window, it demonstrates competitive performance across reasoning, coding, and mathematical benchmarks while supporting multilingual capabilities and long-context processing.
Explore the Future of AI
Your server, your data, under your control
DeepSeek V3 is a large-scale, open-source Mixture-of-Experts (MoE) language model introduced by DeepSeek-AI. Building on the architectures and insights of its predecessor DeepSeek V2, DeepSeek V3 introduces a series of innovations aimed at enhancing efficiency, context capabilities, and reasoning, while maintaining robust performance across a wide array of natural language understanding and generation benchmarks. The model incorporates advanced architectural features and novel load-balancing techniques, as described in its technical report.
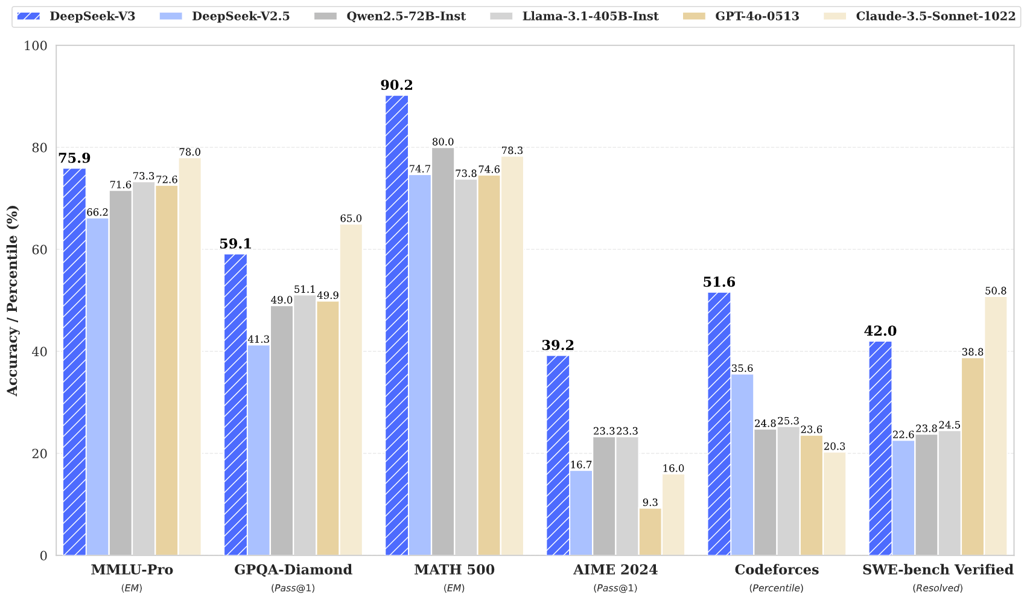
Comparative benchmark results illustrate DeepSeek V3’s performance against selected large language models on a range of reasoning, coding, and math tasks.
At its core, DeepSeek V3 employs a Transformer-based Mixture-of-Experts (MoE) architecture encompassing 671 billion total parameters, with only 37 billion parameters activated per token during inference, as detailed in the model overview. This sparse activation enables efficient compute utilization and supports both cost-effective training and high-speed deployment.
The model extends several innovations first seen in DeepSeek V2, including Multi-head Latent Attention (MLA) and the DeepSeekMoE expert routing system. MLA introduces low-rank joint compression for attention keys and values, substantially reducing inference memory requirements without sacrificing model capacity. DeepSeekMoE utilizes 256 routed experts per MoE layer (with 8 experts active per token), and node-limited routing ensures that tokens do not incur excessive cross-node communication, maintaining inference efficiency at scale.
A distinctive feature of DeepSeek V3 is its auxiliary-loss-free load balancing mechanism. Unlike traditional MoE models that rely on explicit auxiliary loss to encourage even expert utilization, DeepSeek V3 implements adaptive expert bias terms, dynamically learned to encourage specialization and maintain load balance. Additionally, a sequence-wise balancing loss is introduced to prevent imbalances within individual input sequences.
DeepSeek V3 also pioneers auxiliary Multi-Token Prediction (MTP) objectives, enabling the model to predict multiple sequential tokens from each context position during training. This approach densifies the learning signal and may enhance the model's ability to build more forward-looking representations. For training and inference, the model leverages an FP8 mixed-precision computing framework, supported by fine-grained quantization and high-precision accumulation strategies. This enables both reduced memory consumption and accelerated training, with stable and effective FP8-based training described in detail in the FP8 details.
Training Data and Methods
For pre-training, DeepSeek V3 was exposed to a diversified corpus comprising 14.8 trillion high-quality tokens. Special emphasis was placed on enriching mathematical and programming data and expanding multilingual coverage. To ensure variance, novel tokenization strategies were introduced, employing a byte-level BPE with a 128,000-token vocabulary and randomly splitting composite tokens to decrease token boundary bias.
A fill-in-middle (FIM) objective, previously characterized in DeepSeekCoder-V2, was employed for approximately 10% of training samples. The training regimen followed a two-stage context extension schedule, first extending the context window to 32,000 tokens and then to 128,000 tokens using the Yet another RoPE foRN (YaRN) methodology for context extension. The aggregate training process—including supervised instruction tuning and reinforcement learning for post-training—was completed in under two months, accumulating roughly 2.79 million H800 GPU hours, which is detailed in the training resource utilization metrics.
During supervised fine-tuning, 1.5 million instructional examples were curated, spanning diverse domains. For reasoning-intensive tasks, outputs from internal DeepSeek-R1 models were used to augment the training set, whereas other domains incorporated outputs verified by human annotators. Reinforcement learning further improved alignment, using a combination of rule-based and model-based reward models, with Group Relative Policy Optimization (GRPO) in lieu of a critic.
Performance and Evaluation
DeepSeek V3 demonstrates competitive performance relative to both open-source and proprietary language models. In evaluations across standardized benchmarks—including MMLU, BBH, DROP, HumanEval, GSM8K, and Arena-Hard—the model's scores are presented in the benchmark summary.
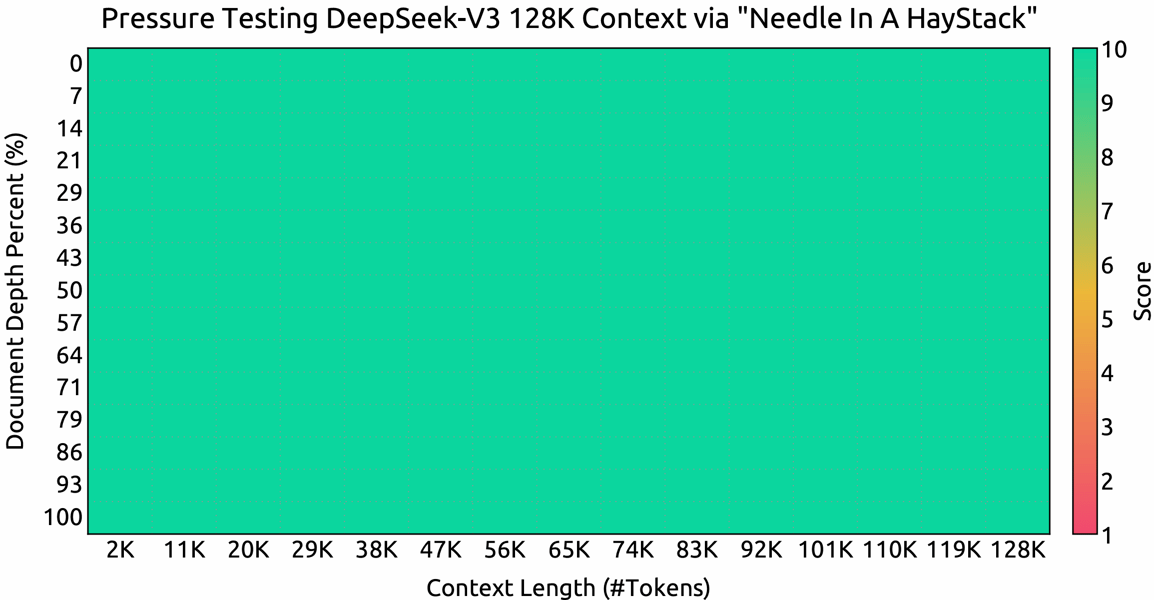
Needle In A Haystack test: DeepSeek V3 maintains high accuracy across context windows from 2K to 128K tokens, demonstrating its long-context capabilities.
In open-ended generation, the model attains an Arena-Hard score exceeding 85% and performs better than its predecessors on instruct-following and question-answering assessments such as AlpacaEval 2.0. In the role of a generative reward model, DeepSeek V3 exhibits performance levels comparable to certain other models, providing reliable automated reward labeling, as shown in the reward benchmarking data. Notably, its long-context capacities are validated through Needle In A Haystack (NIAH) tests, where it sustains high retrieval accuracy even at the upper limit of 128,000 tokens.
Applications and Use Cases
DeepSeek V3’s architecture and training pipeline are designed to maximize applicability across a variety of domains. The model supports general-purpose natural language understanding and generation, including but not limited to complex instruction following, document summarization, and conversational AI. Its high scores on coding and mathematical reasoning benchmarks—such as HumanEval (code synthesis), MATH (complex mathematical reasoning), and Codeforces (programming competition problems)—qualify it for advanced engineering, educational, and algorithmic problem-solving applications.
With its ability to process and retain context over extremely long input sequences, DeepSeek V3 is well-suited for retrieval-augmented generation, exhaustive content summarization, and legal or scientific analysis that requires referencing large volumes of text. The model’s strong alignment and reward modeling capacity also enable its use as an evaluator or automated judge in reinforcement learning from human feedback pipelines.
Model Family and Evolution
DeepSeek V3 belongs to a lineage of models developed by DeepSeek-AI. Its design incorporates improvements and innovations from both DeepSeek V2 and the DeepSeek-R1 series, as described in the model family overview. While DeepSeek V2 (236B parameters, 21B activated per token) introduced foundational architectural changes such as MLA and MoE routing, DeepSeek V3 expands these capabilities to a larger parameter count, introduces auxiliary-loss-free load balancing, and adopts FP8 mixed-precision training at a significant scale.
Additionally, DeepSeek V3 benefits from knowledge distillation procedures using the DeepSeek-R1 (long-chain-of-thought) models, aiming to inherit advanced reasoning skills while maintaining brevity and coherence in generated responses. Techniques like FIM and context extension strategies echo methods utilized in both DeepSeekCoder-V2 and the DeepSeek-R1 series.
Limitations and Licensing
Despite its wide-ranging capabilities, there are several operational considerations for DeepSeek V3. Due to its size and parallelization design, deployment units tend to be large, which may pose challenges for smaller teams or those with limited infrastructure. While the inference system demonstrates speed improvements over prior models, further optimizations are possible—particularly for distributed and low-latency settings. Native support within the HuggingFace Transformers library remains pending, necessitating the use of specialized frameworks for deployment.
In specific factual knowledge benchmarks, notably SimpleQA in English, DeepSeek V3 is marginally outperformed by certain alternative LLMs. This is in part attributable to resource prioritization during training, which favored multilingual diversity and Chinese content coverage, as discussed in the limitations section.
The codebase is made available under the MIT License, and the model weights are licensed to allow commercial application according to the terms outlined in the model's technical report.