Launch a dedicated cloud GPU server running Laboratory OS to download and run DeepSeek Coder V2 using any compatible app or framework.
Direct Download
Must be used with a compatible app, notebook, or codebase. May run slowly, or not work at all, depending on local system resources, particularly GPU(s) and available VRAM.
Open WebUI is an open-source, self-hosted web interface with a polished, ChatGPT-like user experience for interacting with LLMs. Integrates seamlessly with local Ollama installation.
The most full-featured web interface for experimenting with open source Large Language Models. Featuring a wide range of configurable settings, inference engines, and plugins.
Model Report
Deepseek AI / DeepSeek Coder V2
DeepSeek Coder V2 is an open-source Mixture-of-Experts code language model developed by DeepSeek AI, featuring 236 billion total parameters with 21 billion active parameters. The model supports 338 programming languages and extends up to 128,000 token context length. Trained on 10.2 trillion tokens of code, mathematics, and natural language data, it demonstrates competitive performance on code generation benchmarks like HumanEval and mathematical reasoning tasks.
Explore the Future of AI
Your server, your data, under your control
DeepSeek-Coder-V2 is an open-source, Mixture-of-Experts (MoE) code language model developed by DeepSeek-AI. It was designed for advanced code and mathematical reasoning that supports a variety of programming languages and problem domains, and has been evaluated for performance against models such as GPT-4 Turbo in code-centric tasks. Details of its model architecture, training scale, and evaluation methodologies are documented in the arXiv paper and official model repositories.
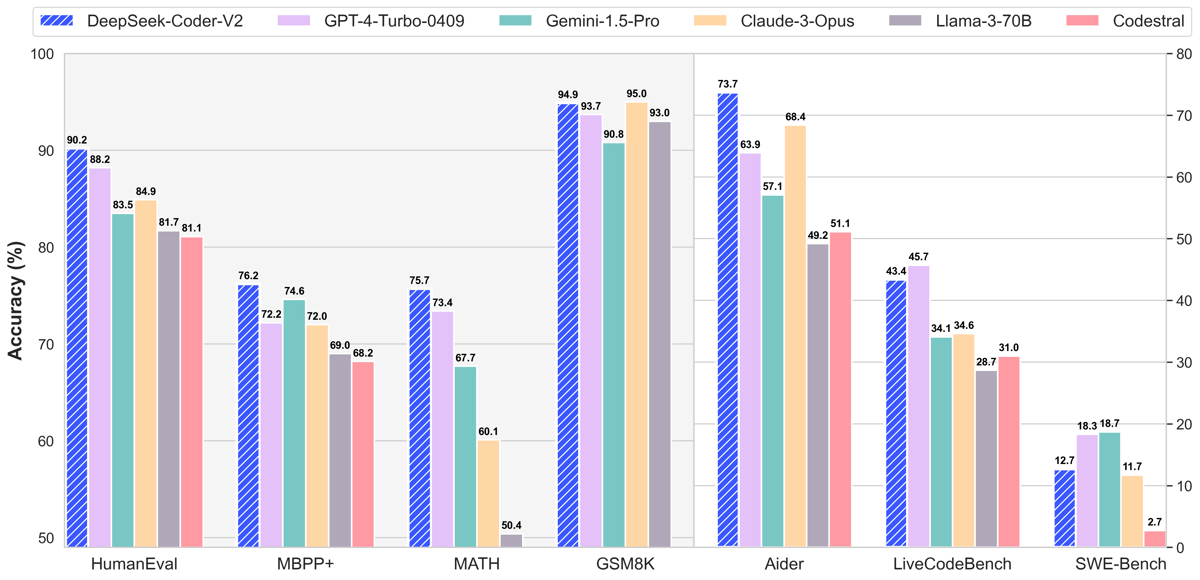
DeepSeek-Coder-V2 performance benchmarked against other leading models (GPT-4-Turbo, Claude 3 Opus, Gemini 1.5 Pro, Llama-3-70B, Codestral) across HumanEval, MBPP+, MATH, GSM8K, Aider, LiveCodeBench, and SWE-Bench.
DeepSeek-Coder-V2 leverages a Mixture-of-Experts (MoE) architecture, with two principal variants: DeepSeek-Coder-V2 (236 billion total parameters, 21 billion active) and DeepSeek-Coder-V2-Lite (16 billion total parameters, 2.4 billion active). The model is built atop an intermediate checkpoint of DeepSeek-V2, inheriting its DeepSeekMoE framework and extending it for coding and mathematical domains. Improvements include resolving previous training instabilities and gradient spikes by reverting to conventional normalization schemes within the transformer blocks.
The architecture supports an extended context window of up to 128,000 tokens—facilitated through the Yarn technique—enabling the model to process and reason over lengthy codebases and documents. Moreover, DeepSeek-Coder-V2-Lite-Base is trained with a fill-in-the-middle (FIM) objective, enhancing its ability to insert code segments given surrounding content and improving code completion flexibility.
Training Data and Methodology
The training of DeepSeek-Coder-V2 encompasses a substantial dataset, accumulating 10.2 trillion tokens, building on DeepSeek-V2's pretraining (4.2T tokens) with an additional 6T tokens specifically curated for code, mathematics, and natural language content. The final dataset composition is approximately 60% source code (spanning 338 programming languages), 10% mathematical corpus, and 30% natural language text. Code sources are drawn primarily from GitHub and CommonCrawl, subjected to rigorous filtering to eliminate low-quality and duplicate instances. The mathematical dataset leverages resources such as Math StackExchange and Odyssey-math.
Pretraining objectives consist of next-token prediction for all model sizes, while the 16B model also utilizes FIM (Prefix, Suffix, Middle) masking, set at a 50% application rate. The optimizer of choice is AdamW, with hyperparameters $\beta_1 = 0.9$, $\beta_2 = 0.95$, and a cosine decay learning rate schedule. For alignment, a multi-phase process includes supervised fine-tuning on a 300M token instruction dataset, combining code, math, and general instruction data, followed by reinforcement learning via the Group Relative Policy Optimization (GRPO) algorithm. Feedback for reward modeling incorporates compiler outputs and test case results, ensuring alignment with human and functional coding preferences.
Performance Evaluation
Evaluations of DeepSeek-Coder-V2 span a suite of code generation, completion, code editing, reasoning, and math benchmarks. On code synthesis, the model achieves 90.2% accuracy on HumanEval (Python) and 76.2% on MBPP+, outperforming both open-source and multiple proprietary models on these measures. Notably, the model attains 43.4% on LiveCodeBench and 12.7% on SWE-Bench (the first time an open-source model exceeded 10% for SWE-Bench).
On multilingual code generation, DeepSeek-Coder-V2-Instruct achieves a 75.3% average across multiple languages on Multilingual HumanEval, yielding high results in Java and PHP and competitive performance across Python, C++, C#, TypeScript, and JavaScript. For competitive programming, the model matches the highest available scores among large models on USACO.
Code completion tasks evaluated by RepoBench v1.1 show that the Lite variant, despite its smaller active parameter count, maintains parity with the 33B variant in Python and the 7B variant in Java. Fill-in-the-middle evaluation yields 86.4% mean accuracy.
In code fixing, DeepSeek-Coder-V2 achieves 21.0% on Defects4J and leads all models with 73.7% on Aider. For code understanding and reasoning, results include 70.0% on CRUXEval-I-COT and 75.1% on CRUXEval-O-COT.
Finally, in general language understanding, DeepSeek-Coder-V2 remains on par with DeepSeek-V2 across benchmarks like MMLU (79.2% using OpenAI simple-eval pipeline), Arena-Hard (65.0%), MT-Bench (8.77), and Alignbench (7.84).
Limitations
Despite its robust capabilities, DeepSeek-Coder-V2 exhibits certain limitations. Instruction following can lag behind proprietary models such as GPT-4 Turbo, especially in complex, multi-step tasks like those found in SWE-Bench. The Lite variant is also less effective on knowledge-intensive evaluations like TriviaQA, due in part to limited pretraining on web-scale text. While outperforming open-source peers on code reasoning (e.g., CRUXEval), there remain measurable performance gaps compared to the largest closed-source models, a difference partly attributable to active parameter counts and training scale.
Applications and Licensing
DeepSeek-Coder-V2 is suitable for a broad array of code-oriented applications, including code completion, code generation, code insertion, code fixing, and mathematical problem solving. It also powers conversational assistants for technical disciplines.
The model and codebase are available under permissive terms: code is distributed via the MIT License, and model weights are governed by the DeepSeek Model License. The full series—including Base and Instruct variants—are available for commercial use in accordance with these licensing terms.