Launch a dedicated cloud GPU server running Laboratory OS to download and run Qwen3 30B A3B using any compatible app or framework.
Direct Download
Must be used with a compatible app, notebook, or codebase. May run slowly, or not work at all, depending on local system resources, particularly GPU(s) and available VRAM.
Open WebUI is an open-source, self-hosted web interface with a polished, ChatGPT-like user experience for interacting with LLMs. Integrates seamlessly with local Ollama installation.
The most full-featured web interface for experimenting with open source Large Language Models. Featuring a wide range of configurable settings, inference engines, and plugins.
Model Report
Alibaba Cloud / Qwen3 30B A3B
Qwen3-30B-A3B is a Mixture-of-Experts language model developed by Alibaba Cloud featuring 30.5 billion total parameters with 3.3 billion activated per token. The model employs hybrid reasoning modes that allow dynamic switching between step-by-step thinking for complex tasks and rapid responses for simpler queries. It supports 119 languages, extends to 131,072 tokens context length, and utilizes strong-to-weak distillation from larger Qwen3 models for efficient deployment while maintaining competitive performance on reasoning, coding, and multilingual benchmarks.
Explore the Future of AI
Your server, your data, under your control
Qwen3-30B-A3B is a small Mixture-of-Experts (MoE) large language model (LLM) developed by Alibaba Cloud's Qwen team as part of the Qwen3 series of models. Qwen3-30B-A3B stands out for its hybrid reasoning capabilities, high efficiency, and robust multilingual support. It integrates architectural, training, and algorithmic innovations aimed at improving large language model efficiency and adaptability, particularly for complex reasoning and agentic tasks.
The official Qwen3 logo, representing the model series developed by Alibaba Cloud.
At its core, Qwen3-30B-A3B employs a Mixture-of-Experts model architecture, with 30.5 billion total parameters and 3.3 billion activated parameters per token. The model is structured with 48 transformer layers, 32 Query heads, and 4 Key/Value heads per layer, and features 128 experts, of which 8 are activated during inference. Context window support extends natively to 32,768 tokens and can reach up to 131,072 tokens using the YaRN context extension technique.
Qwen3-30B-A3B builds on advances from prior Qwen and Qwen2.5 models, employing grouped query attention (GQA), SwiGLU activation, Rotary Positional Embeddings (RoPE), and pre-normalization RMSNorm. Notably, unlike its predecessor Qwen2.5-MoE, Qwen3-MoE omits expert sharing and utilizes a global-batch load balancing loss to encourage expert specialization, enhancing efficiency and reducing redundancy.
The model's tokenizer is based on byte-level byte-pair encoding with a vocabulary of 151,669 tokens, designed for high compatibility with multilingual data and structured agentic outputs.
Training Pipeline and Distillation
Qwen3-30B-A3B's training is segmented into pre-training and post-training phases, refined through a sophisticated distillation pipeline.
Pre-training leverages approximately 36 trillion tokens, nearly twice that of Qwen2.5, spanning 119 languages and dialects. The large-scale and diverse corpus is augmented with synthetic math and code data produced by specialized models from previous Qwen generations. Training proceeds through three stages: a general stage focusing on foundational skills, a reasoning stage emphasizing STEM and logic, and a long-context stage designed to boost sequence length capacity—utilizing RoPE frequency adjustment, YARN, and Dual Chunk Attention techniques.
Benchmarking Qwen models against contemporary LLMs on general, STEM, multilingual, and code tasks.
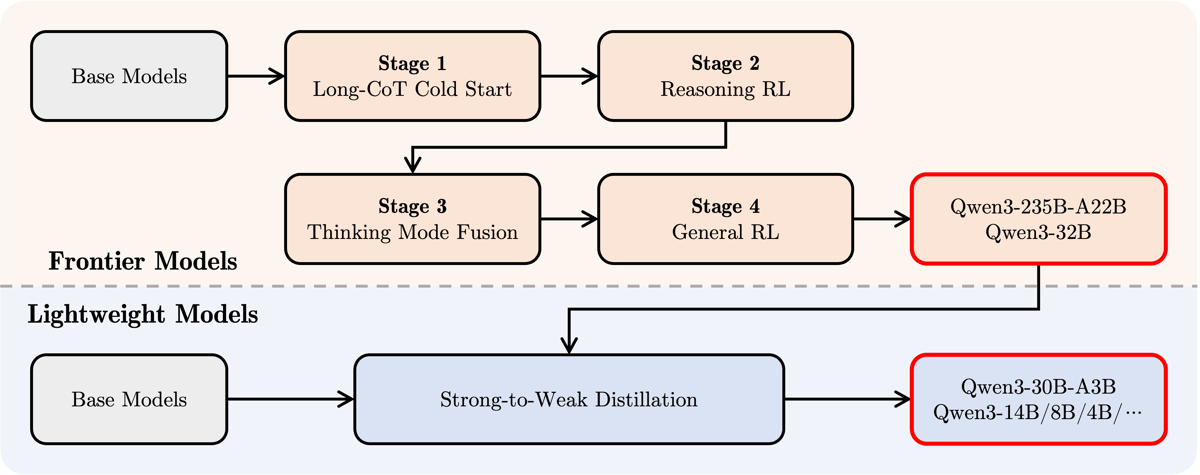
Post-training for the Qwen3 series follows a four-step strategy: Long Chain-of-Thought (CoT) cold start, reasoning-specific reinforcement learning, thinking mode fusion to allow dynamic mode switching, and general reinforcement learning for broad task alignment. However, for efficient deployment on smaller models such as Qwen3-30B-A3B, a strong-to-weak distillation pipeline is used. This approach distills capabilities from larger Qwen3 models (e.g., Qwen3-235B-A22B and Qwen3-32B) into more compact variants like Qwen3-30B-A3B, maintaining high reasoning and instruction-following performance with a reduced computational footprint.
Qwen3's model development flow: multi-stage post-training for frontier models, and strong-to-weak distillation yielding lightweight variants like Qwen3-30B-A3B.
A key innovation of Qwen3-30B-A3B lies in its hybrid reasoning modes. The model dynamically switches between "thinking mode"—which enables explicit step-by-step reasoning for complex tasks—and "non-thinking mode," which favors rapid responses for simpler queries. Users can control reasoning depth via tokenizer parameters or prompt flags, providing fine-grained adaptability to latency and quality requirements.
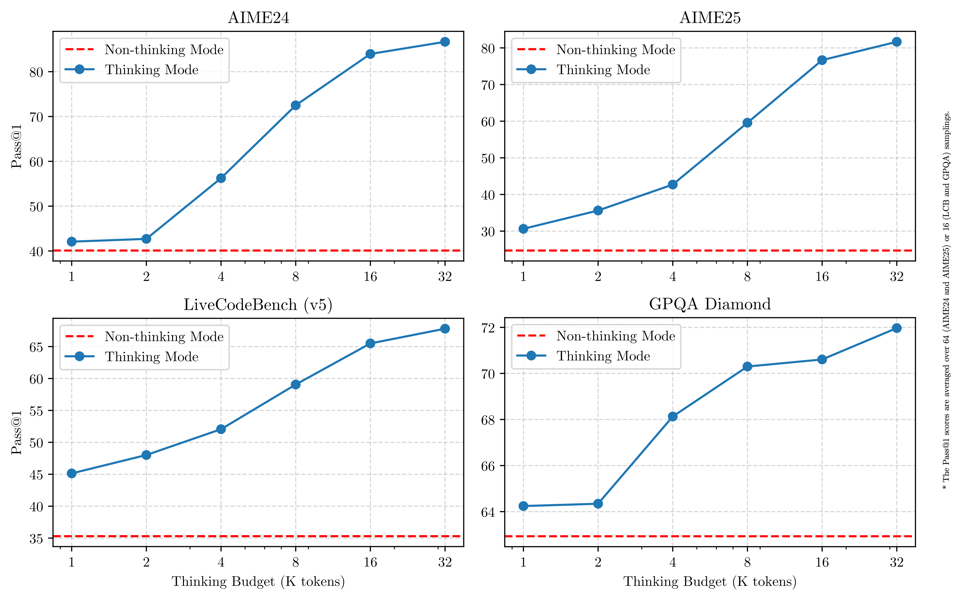
Another significant feature is the "thinking budget" mechanism, which allows users to set a computational limit for reasoning steps. Performance increases as the thinking budget rises, with diminishing returns beyond a certain threshold.
Effect of increasing 'thinking budget'—the number of tokens allotted for step-by-step reasoning—on Pass@1 performance across multiple benchmarks.
Qwen3-30B-A3B is optimized for both agentic tasks (such as multi-step tool use and coding) and a broad array of conversational applications, strengthened further by Qwen-Agent, which provides structured parsing and tool-calling templates. The model supports 119 languages and dialects, enhancing its applicability for global and multilingual scenarios.
Demonstration of Qwen3's agentic capabilities, showcasing its reasoning and environment-interaction functions in a tool-using context. [Source]
Benchmark Performance and Evaluation
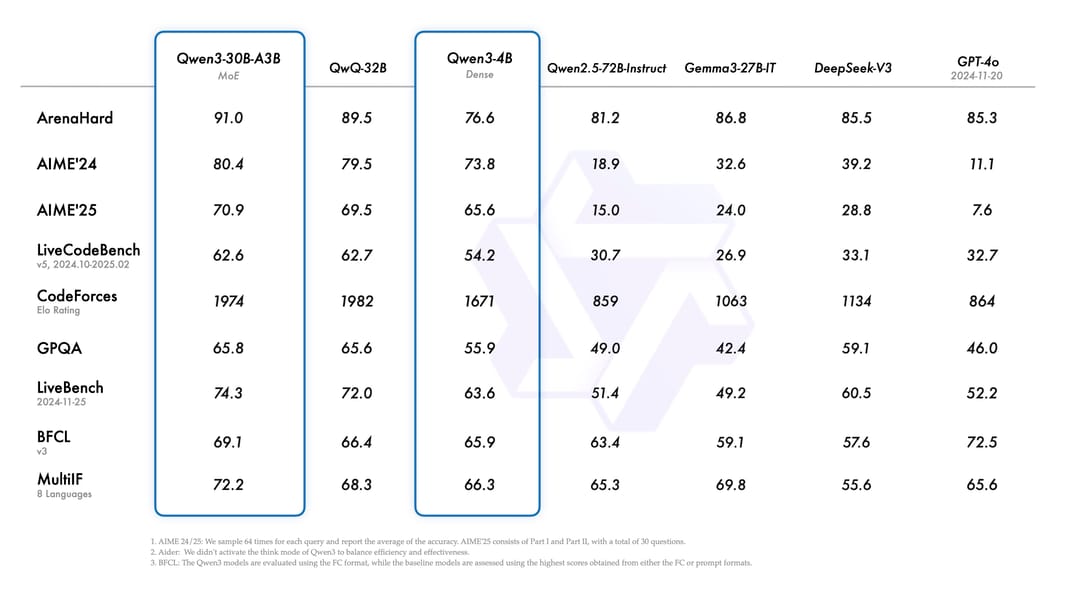
Qwen3-30B-A3B demonstrates strong performance on a variety of standard benchmarks, both during pre-training evaluation and after instruct tuning. Leveraging the strong-to-weak distillation pipeline, it achieves results approaching or surpassing much larger dense models on tasks spanning general knowledge, multi-step reasoning, coding, and mathematics.
Detailed performance comparison of Qwen3-30B-A3B (MoE) and other leading language models across multiple evaluation tasks.
Evaluations on MMLU, GSM8K, EvalPlus, and MATH show that Qwen3-30B-A3B attains competitive or superior accuracy relative to comparable compact models. For instance, on MMLU, it scores 81.38 in base configuration and achieves high rankings on agentic and coding-oriented leaderboards. Multilingual proficiency is reflected in strong results on the Belebele benchmark.
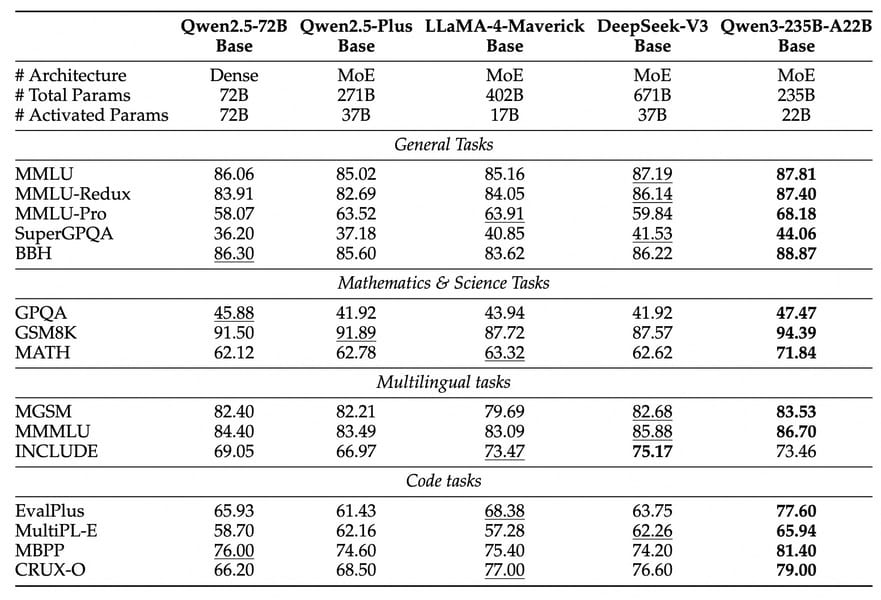
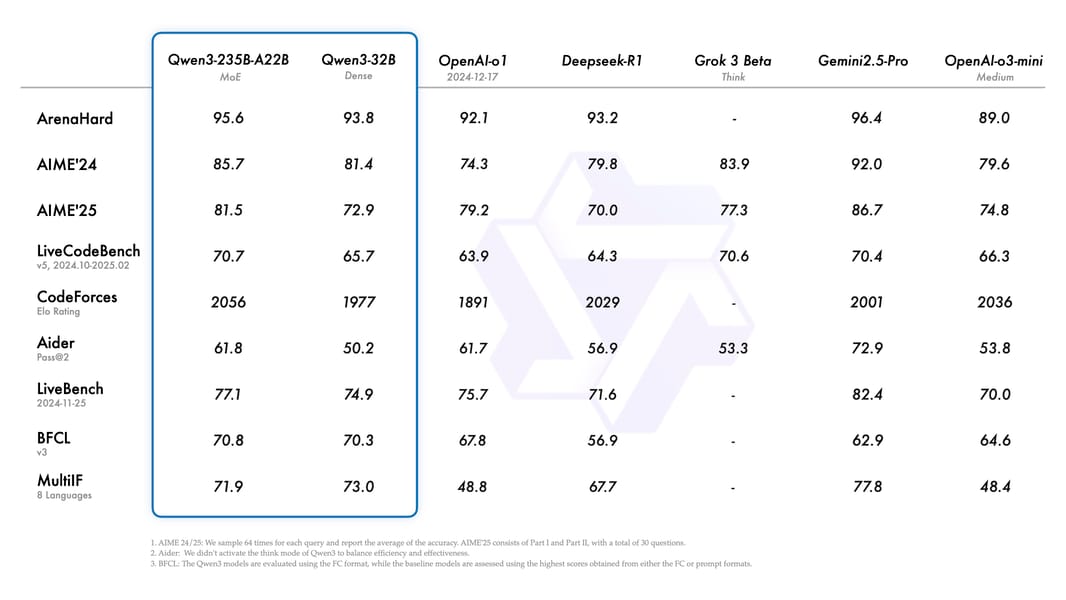
Table comparing Qwen3-235B-A22B and Qwen3-32B to peer models across reasoning, math, coding, and multilingual tasks.
Qwen3-30B-A3B is intended for a variety of applications including general chatbots, multi-turn dialogue, agentic tool use, programming and mathematics reasoning, instruction following, and multilingual conversation. Its hybrid reasoning system makes it adaptable to both simple and complex workflows.
Despite these capabilities, certain trade-offs exist. For example, "thinking mode" may not always confer benefits on retrieval-focused tasks, and adjustments made during post-training for general ability could sometimes reduce top-end performance on highly specialized benchmarks. Practical deployment may require parameter tuning and context-length configuration (such as enabling YaRN for longer sequences), as well as thoughtful integration of agentic routines and output formats. The model is distributed under the Apache 2.0 license, ensuring transparent access for research and development.
Model Family and Related Variants
Qwen3-30B-A3B is part of the broader Qwen3 model family, which includes both large MoE systems—such as Qwen3-235B-A22B—and several dense models at sizes from 1.7B to 32B parameters. These models share a consistent underlying architecture, but are differentiated by parameter scaling, MoE routing, and training objectives. Improvements in Qwen3 are based on experiences developing earlier Qwen and Qwen2.5 series, and new variants often employ strong-to-weak distillation for computational efficiency.
External Resources
For further information, the following resources are available: