Launch a dedicated cloud GPU server running Laboratory OS to download and run Qwen3 32B using any compatible app or framework.
Direct Download
Must be used with a compatible app, notebook, or codebase. May run slowly, or not work at all, depending on local system resources, particularly GPU(s) and available VRAM.
Open WebUI is an open-source, self-hosted web interface with a polished, ChatGPT-like user experience for interacting with LLMs. Integrates seamlessly with local Ollama installation.
The most full-featured web interface for experimenting with open source Large Language Models. Featuring a wide range of configurable settings, inference engines, and plugins.
Model Report
Alibaba Cloud / Qwen3 32B
Qwen3-32B is a 32.8 billion parameter dense language model developed by Alibaba Cloud, featuring hybrid "thinking" modes that enable step-by-step reasoning for complex tasks or rapid responses for routine queries. The model supports 119 languages, extends to 32K token context length, and was trained on 36 trillion tokens using a four-stage post-training pipeline incorporating reinforcement learning and reasoning enhancement techniques.
Explore the Future of AI
Your server, your data, under your control
Qwen3-32B is a dense large language model (LLM) developed by the Qwen team at Alibaba Cloud and released as part of the Qwen3 model family on April 29, 2025. Featuring 32.8 billion parameters, Qwen3-32B integrates advances in architectural design, hybrid reasoning capabilities, and multilingual support. This model serves as both a general-purpose and a reasoning-specialized LLM, utilizing novel hybrid "thinking" modes and refined training methodologies to address a variety of linguistic, reasoning, and coding tasks. The Qwen3 series incorporates lessons learned from earlier generations and introduces expanded modes of operation, improved data diversity, and enhanced context length capabilities, as documented in the official blog post, technical report, and GitHub repository.
Official Qwen3 logo, representing the Qwen3 model series created by the Qwen team at Alibaba Cloud.
Qwen3-32B is structured as a dense causal language model, consisting of 64 transformer layers and employing 64 attention heads for queries and 8 for keys/values via grouped query attention (GQA), as detailed in the technical report. Its architecture draws upon previous Qwen2.5 models by incorporating SwiGLU activations, rotary positional embeddings (RoPE), and RMSNorm with pre-normalization. The QKV-bias component present in earlier versions has been removed, and QK-Norm has been introduced to improve training stability. The model leverages a custom tokenizer utilizing byte-level byte-pair encoding (BBPE) with a vocabulary of 151,669 tokens, offering robust support for a wide array of scripts.
A distinctive feature of Qwen3-32B is its hybrid "thinking mode" framework. In thinking mode (enabled by default and through explicit prompts), the model executes step-by-step reasoning, well-suited for complex problem-solving in domains such as mathematics, programming, and logical deduction. Non-thinking mode provides rapid responses for routine inquiries where speed and efficiency are prioritized. Dynamic mode switching is supported, allowing users to adjust the computational "thinking budget," thereby balancing performance and latency. This hybrid approach is intended to enable more granular control over the reasoning depth and inference speed, as described in the Qwen3 blog post.
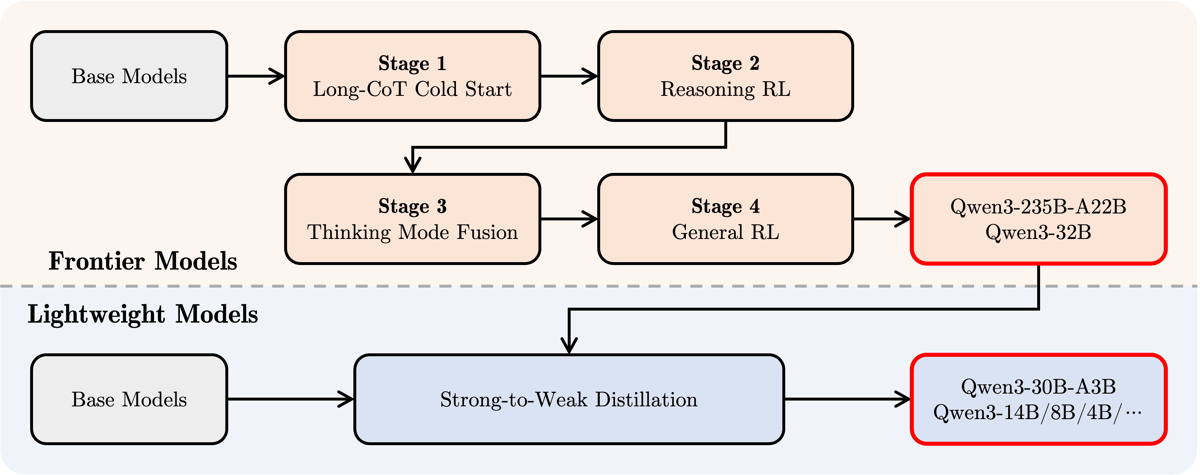
Diagram of the Qwen3 post-training pipeline, highlighting the progression from base models through advanced reasoning and distillation stages to the release of both frontier and lightweight Qwen3 models.
Training Data, Methodology, and Multilingual Support
Qwen3-32B was pretrained on approximately 36 trillion tokens, covering 119 languages and dialects. Data sources include an expanded mixture of web content, PDF-like documents, and high-quality synthetic data for mathematics and programming, generated with preceding models such as Qwen2.5-Math and Qwen2.5-Coder. The pretraining phase was divided into three stages: an initial general language phase (over 30 trillion tokens, 4K-context), a reasoning-rich phase (an additional 5 trillion tokens emphasizing STEM, coding, and logic), and a long-context phase extending training context up to 32,768 tokens by employing long-form datasets and adjusting RoPE base frequency via the ABF technique.
Post-training involves a four-stage pipeline that instills advanced reasoning and hybrid thought processes:
Long Chain-of-Thought (CoT) Cold Start: Fine-tuning on diverse long CoT datasets targeting math, coding, and STEM tasks.
Reasoning-Based Reinforcement Learning: Enhancement of reasoning through rule-based reinforcement.
Thinking Mode Fusion: Integration of both thinking and non-thinking capabilities to optimize performance across task types.
General Reinforcement Learning: Final alignment and corrections across a spectrum of real-world benchmarks.
For compact models, strong-to-weak distillation techniques are leveraged to efficiently transfer reasoning and general knowledge from larger models into smaller ones. This enables high performance even at reduced parameter counts, according to the design described in the technical report.
Qwen3-32B's multilingual support has been substantially expanded, with annotation and quality-control systems covering Indo-European, Sino-Tibetan, Afro-Asiatic, Austronesian, Dravidian, Turkic, and a wide range of additional language families.
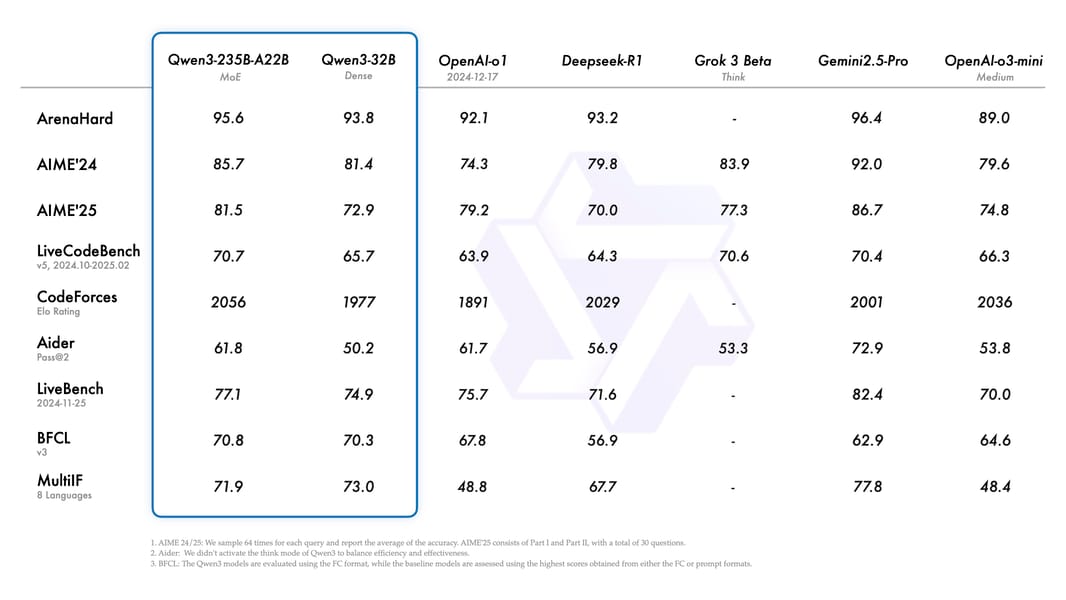
Comprehensive benchmark chart for Qwen3-32B and other large models across diverse tasks, including ArenaHard, AIME, LiveCodeBench, and more.
Benchmark evaluations of Qwen3-32B demonstrate robust performance in both reasoning-intense and general-purpose tasks. In "thinking mode," Qwen3-32B shows strong results among 32B-parameter models across a wide battery of public benchmarks, such as MMLU-Redux, GPQA-Diamond, C-Eval, LiveBench, and MATH-500. In non-thinking mode, it delivers high-speed, high-accuracy performance for general and multilingual uses. Performance data published in the technical report and blog show that Qwen3-32B performs competitively on diverse metrics, especially in code generation, mathematical reasoning, and multi-turn dialogue.
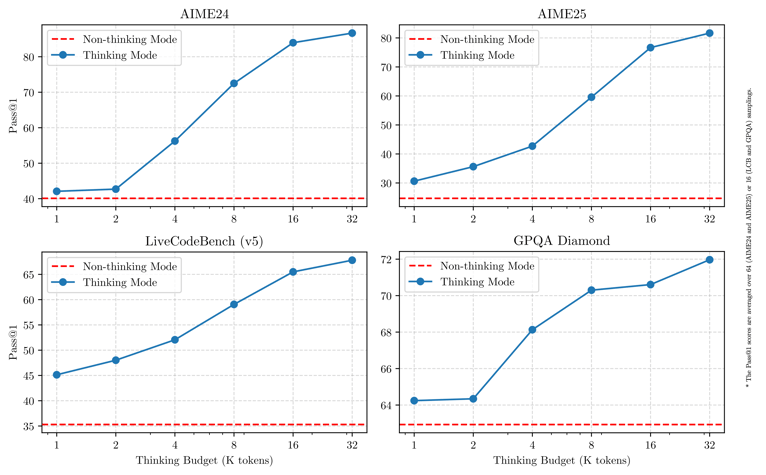
Qwen3-32B natively supports a context length of 32,768 tokens, extendable up to 131,072 tokens using the YaRN approach, with empirical validation on the RULER benchmark for long-context retrieval. In thinking mode, detailed step-wise outputs may slightly degrade retrieval performance as additional reasoning content is included in the response stream, a tradeoff noted in evaluations.
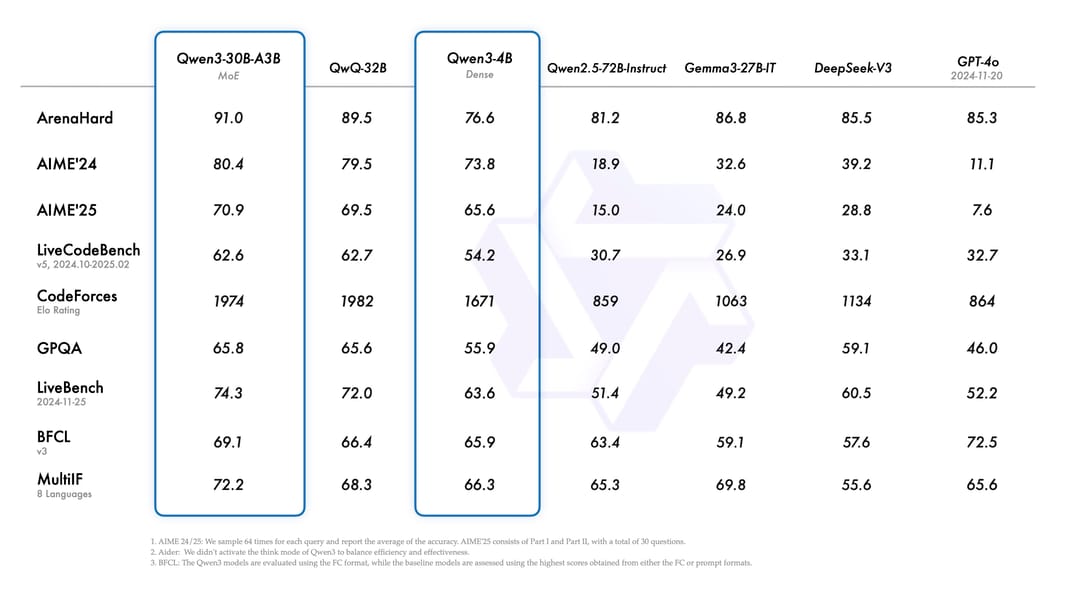
Table providing side-by-side benchmark scores of Qwen3, QwQ, Gemma, DeepSeek, and GPT-4o on tasks such as ArenaHard, AIME, and coding evaluations.
Qwen3-32B is optimized for agentic applications, providing precise tool-calling and external tool integration functionalities through the Qwen-Agent system. Its hybrid thinking modes are particularly effective for agent-style operations, enabling complex multi-step reasoning, function execution, and information retrieval.
Video demonstration of Qwen3-32B's agentic capabilities and its ability to interact with external environments using advanced reasoning. [Source]
Additional prominent applications include:
Advanced logical reasoning and problem-solving tasks, particularly in mathematics and programming.
Efficient, high-quality general-purpose chat and multi-turn dialogue systems.
Multilingual instruction following, creative writing, and role-playing.
The model's flexible operation modes and intentional design for multilingualism enable a diverse set of global and domain-specific use cases, supported by in-depth experimental results.
Line charts showing how Pass@1 scores for reasoning tasks (AIME24, AIME25, LiveCodeBench, GPQA Diamond) vary with the 'thinking budget' for Qwen3-32B, demonstrating tradeoffs between reasoning depth and computational cost.
Despite its broad capabilities, Qwen3-32B has several noted limitations. In thinking mode, retrieval performance for long-context tasks can be reduced due to interleaved reasoning content. While the hybrid mode fusion and general reinforcement learning enhance versatility, they may lead to reduced performance on certain specialized benchmarks such as AIME'24 and Live-CodeBench. Static YaRN context window extensions, as currently supported in most open-source libraries, can negatively affect short-text processing.
Greedy decoding is not recommended, particularly in thinking mode, as it can result in degraded output quality and repetition. Furthermore, aggressive presence penalty settings, while effective at reducing repetition, may cause language mixing and modest performance drops.
Qwen3-32B and all Qwen3 open-weight models are licensed under Apache 2.0, supporting open research, adaptation, and downstream development.
Model Variants, Family, and Evolution
Qwen3 is a diverse model family featuring both dense and Mixture-of-Experts (MoE) architectures, ranging from 0.6 to 235 billion parameters. Qwen3-32B is the largest dense variant; the flagship MoE model is Qwen3-235B-A22B, which activates a 22B expert subset per inference. Smaller dense models (Qwen3-14B, 8B, 4B, 1.7B, 0.6B) are released in parallel, all using similar training pipelines and benefiting from strong-to-weak distillation.
Compared to earlier Qwen2.5 models, the Qwen3 base models match or exceed their predecessors at corresponding or even smaller parameter sizes, an improvement visible across standard benchmarks and outlined in the technical report.