Launch a dedicated cloud GPU server running Laboratory OS to download and run Qwen3 0.6B using any compatible app or framework.
Direct Download
Must be used with a compatible app, notebook, or codebase. May run slowly, or not work at all, depending on local system resources, particularly GPU(s) and available VRAM.
Open WebUI is an open-source, self-hosted web interface with a polished, ChatGPT-like user experience for interacting with LLMs. Integrates seamlessly with local Ollama installation.
The most full-featured web interface for experimenting with open source Large Language Models. Featuring a wide range of configurable settings, inference engines, and plugins.
Model Report
Alibaba Cloud / Qwen3 0.6B
Qwen3-0.6B is a dense language model with 0.6 billion parameters developed by Alibaba Cloud, featuring a 28-layer transformer architecture with Grouped Query Attention. The model supports dual thinking modes for adaptive reasoning and general dialogue, processes up to 32,768 tokens context length, and demonstrates multilingual capabilities across over 100 languages. It utilizes strong-to-weak distillation from larger Qwen3 models and is released under Apache 2.0 license.
Explore the Future of AI
Your server, your data, under your control
Qwen3-0.6B is a dense language model within the Qwen3 series, developed by Alibaba Cloud's Qwen team. As part of the third generation of Qwen models, Qwen3-0.6B is designed to advance capabilities in reasoning, instruction-following, agent-based interactions, and multilingual processing. Officially released as part of the broader Qwen3 family on April 29, 2025, this model emphasizes a balance between efficient deployment and sophisticated language understanding across a wide array of domains.
Banner from the official Qwen3 announcement, introducing the latest models in the series.
Qwen3-0.6B features a causal language model architecture with 0.6 billion total parameters, of which 0.44 billion are non-embedding parameters. The model consists of 28 transformer layers utilizing Grouped Query Attention (GQA) with 16 query and 8 key/value heads, enabling efficient scaling and attention mechanisms. The implementation incorporates advanced techniques, including SwiGLU activation, Rotary Positional Embeddings (RoPE), and RMSNorm with pre-normalization strategies. Notably, architectural innovations such as the removal of QKV-bias and the adoption of QK-Norm in the attention layer have been introduced to stabilize training.
The tokenizer for Qwen3-0.6B is based on byte-level byte-pair encoding (BBPE) and supports a vocabulary of 151,669 tokens, allowing for extensive multilingual capability.
A distinctive feature of the Qwen3 series is its capacity for "hybrid thinking modes." The default thinking mode supports complex reasoning, mathematics, and code generation, outputting content in <think>...</think> tags. The non-thinking mode, conversely, delivers efficient, general-purpose dialogue. Users can switch between these modes dynamically—either programmatically or by including specific tokens such as /think and /no_think in their prompts. This dual-mode architecture enables adaptive allocation of computational resources and enhances performance flexibility for a variety of language tasks.
Training Methodology
Qwen3-0.6B is trained through a comprehensive pipeline involving both pretraining and specialized post-training strategies. During pretraining, the model is exposed to an extensive corpus comprising approximately 36 trillion tokens from 119 languages and dialects, nearly double that of its predecessor Qwen2.5. The dataset aggregates diverse sources, including web data, document corpora, and synthetic examples for mathematics and programming generated by earlier Qwen models.
The pretraining phase is implemented in three main stages. The general pretraining stage imparts broad language competence and world knowledge. The reasoning stage focuses on knowledge-intensive data, including STEM, mathematics, and reasoning-specific queries. The final pretraining stage extends context capability up to 32,768 tokens, leveraging long-form data and employing methods such as Adaptive Base Frequency, YARN, and Dual Chunk Attention for enhanced sequence length management.
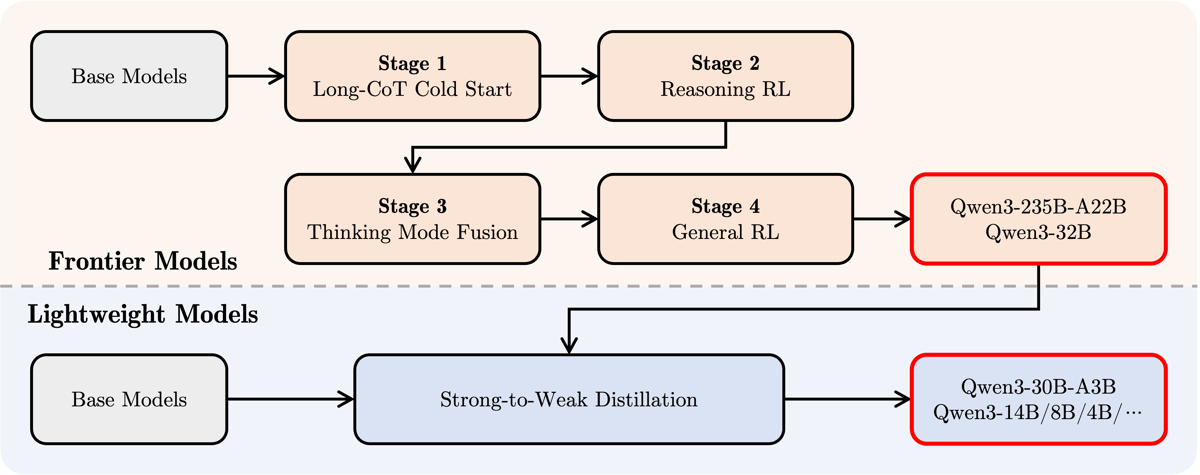
Diagram of the post-training and distillation process for Qwen3 models, showing frontier and lightweight models' training trajectories.
In post-training, larger Qwen3 models undergo four stages: long chain-of-thought (CoT) cold start, reinforcement learning with reasoning-based rules, fusion of thinking and non-thinking modes, and a general reinforcement learning phase that tunes performance across more than 20 general-domain tasks. For compact models such as Qwen3-0.6B, a strong-to-weak distillation process is employed. This distills knowledge and mode-switching abilities from larger parent models—namely, Qwen3-32B and Qwen3-235B-A22B—directly into the smaller variants, ensuring efficient learning without the need for the full post-training regimen.
Evaluation and Benchmark Results
Qwen3-0.6B undergoes extensive evaluation against a suite of benchmarks, demonstrating marked improvements over similarly sized predecessors and strong competitiveness even against larger models. Notable pretraining benchmark scores include MMLU (52.81), GSM8K for math (59.59), and encoding tasks such as EvalPlus for code (36.23). Post-training, the model exhibits enhanced performance due to advanced alignment and reasoning training.
The hybrid thinking mode supports improved results in reasoning-intensive benchmarks, with metrics such as MMLU-Redux (55.6) and MATH-500 (77.6) in thinking mode. General dialogue and alignment are also strengthened, as reflected in IFEval and Creative Writing v3 scores. Moreover, Qwen3-0.6B demonstrates robust multilingual proficiency, achieving competitive results on Belebele multilingual benchmarks, spanning diverse language families beyond Indo-European and Sino-Tibetan groupings.
The model is capable of handling samples with context lengths up to 32,768 tokens, with tests on the RULER benchmark affirming that performance remains stable for long-context retrieval and reasoning, although slight degradation is observed in thinking mode for tasks relying exclusively on retrieval.
Applications, Use Cases, and Model Family
Qwen3-0.6B is engineered for a wide range of use cases, including logical reasoning, mathematical problem-solving, code synthesis, creative writing, role-play, and natural dialogue across multiple turns. Its agentic abilities are enhanced through integration with external toolchains, making it suitable for automation and complex workflow orchestration tasks. The model's strong multilingualism supports instruction following, translation, and dialogue across a spectrum of over 100 languages and dialects.
Demonstration of Qwen3's agentic capabilities, highlighting interaction and reasoning in an applied context. [Source]
Qwen3-0.6B belongs to a broader family of models, spanning dense and Mixture-of-Experts (MoE) variants at larger parameter scales, including Qwen3-1.7B, Qwen3-4B, Qwen3-8B, Qwen3-14B, Qwen3-32B, and flagship MoE models such as Qwen3-235B-A22B. The strong-to-weak distillation strategy used for lightweight models enables them to inherit key capabilities of larger models, particularly the flexible mode-switching and advanced reasoning features.
Limitations and Licensing
Despite robust performance, Qwen3-0.6B displays some known limitations. Repetitive outputs can occur, especially if greedy decoding is mistakenly employed during inference in thinking mode. This can often be alleviated by careful adjustment of sampling hyperparameters such as temperature and presence penalty. Retrieval accuracy in long-context scenarios can slightly decline in thinking mode, likely attributable to interference from auxiliary reasoning tokens. Additionally, general reinforcement learning stages may introduce performance trade-offs, occasionally diminishing results for highly specialized tasks like competitive mathematics or complex code generation.
Qwen3-0.6B and its open-weights counterparts are distributed under the Apache 2.0 license, supporting open research and adaptation. For technical specifications, usage guidelines, and ongoing research updates, refer to the model's official documentation and the full technical report.