Launch a dedicated cloud GPU server running Laboratory OS to download and run Qwen3 4B using any compatible app or framework.
Direct Download
Must be used with a compatible app, notebook, or codebase. May run slowly, or not work at all, depending on local system resources, particularly GPU(s) and available VRAM.
Open WebUI is an open-source, self-hosted web interface with a polished, ChatGPT-like user experience for interacting with LLMs. Integrates seamlessly with local Ollama installation.
The most full-featured web interface for experimenting with open source Large Language Models. Featuring a wide range of configurable settings, inference engines, and plugins.
Model Report
Alibaba Cloud / Qwen3 4B
Qwen3-4B is a 4.0 billion parameter transformer language model developed by Alibaba Cloud, featuring dual reasoning modes that allow users to toggle between detailed step-by-step thinking and rapid response generation. Released under Apache 2.0 license, the model supports 32,768 token contexts, demonstrates strong performance across mathematical reasoning and coding benchmarks, and incorporates advanced training techniques including strong-to-weak distillation from larger teacher models.
Explore the Future of AI
Your server, your data, under your control
Qwen3-4B is a dense large language model (LLM) developed by Alibaba Cloud's Qwen team, constituting one of several open-weight models in the Qwen3 series. Released on April 29, 2025, and distributed under the Apache 2.0 License, Qwen3-4B incorporates advanced training techniques, supports a wide range of languages, and is notable for its dual-mode reasoning design. With a parameter count of 4.0 billion, it addresses diverse applications requiring both rapid inference and complex reasoning capabilities.
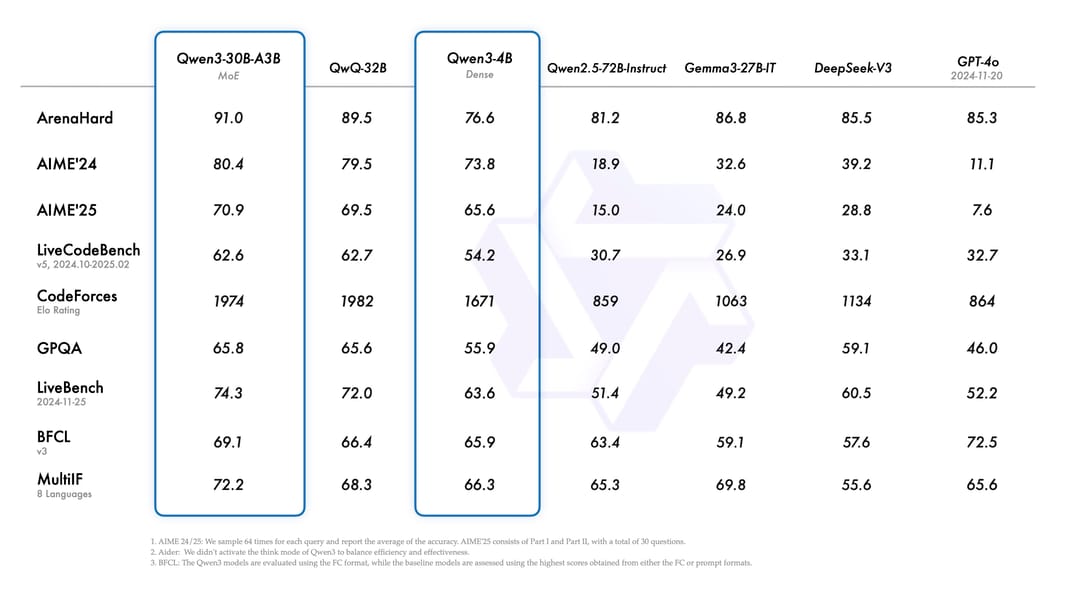
Performance benchmarks comparing Qwen3-4B to other LLMs across tasks, including math, coding, critical reasoning, and multi-turn dialogue.
Qwen3-4B is architected as a 36-layer transformer model employing 4.0 billion total parameters (of which 3.6 billion are non-embedding). Its core architecture builds upon recent advancements and improvements made over previous Qwen models. Notable features include Grouped Query Attention (GQA) for efficient attention computation, the SwiGLU activation function, and pre-normalization using RMSNorm, all contributing to stable and scalable training.
The model utilizes byte-level byte-pair encoding (BBPE) for tokenization with a vocabulary of 151,669 entries, facilitating robust multilingual representation. Rotary positional embeddings (RoPE) are extended using the ABF technique for increased base frequency, supporting context lengths up to 32,768 tokens by default and up to 131,072 tokens through YaRN scaling. Attention stability is further bolstered by the introduction of QK-Norm, and the design omits QKV-bias for streamlined computation.
Training Methodology and Data
Qwen3-4B is pretrained on a vast corpus of approximately 36 trillion tokens sourced from diverse web documents, programming code, STEM content, and curated text from 119 languages and dialects, doubling the scale of its predecessor, Qwen 2.5. A three-stage pretraining regimen is implemented: an initial general language acquisition stage, a reasoning-focused phase targeting knowledge-intensive tasks, and a final long-context training phase to extend effective context window size.
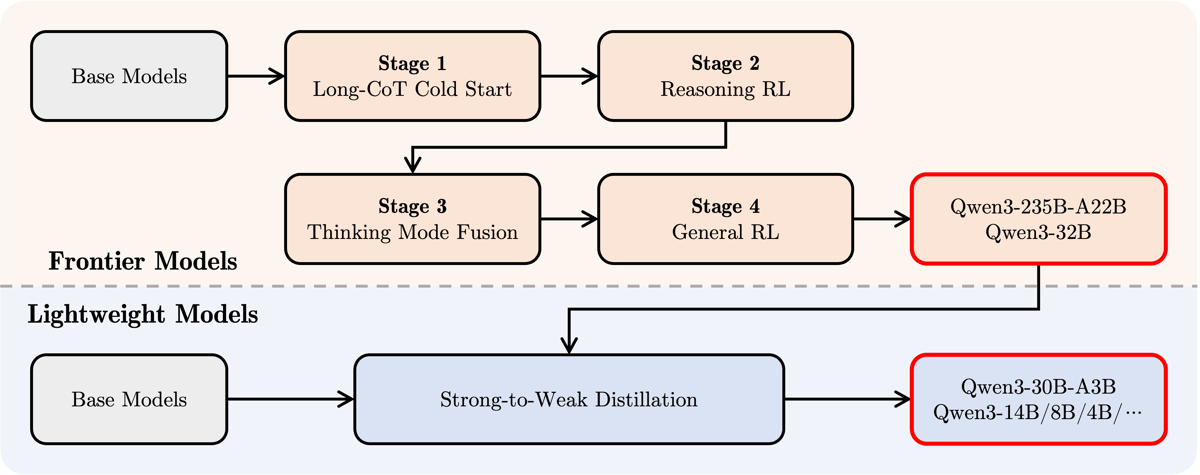
During post-training, flagship models undergo four refinement steps: long chain-of-thought (CoT) cold start, reinforcement learning (RL) with reasoning-based rewards, thinking mode fusion to integrate instruction following and reasoning, and general RL on broad task sets. Due to their smaller sizes, models like Qwen3-4B use a strong-to-weak distillation pipeline, leveraging teacher models for knowledge transfer and efficient post-training. Both off-policy and on-policy distillation are applied to maximize performance in reasoning and general instruction following.
Diagram of Qwen3 post-training processes: top section shows comprehensive RL-based refinement for flagship models, while the lower section illustrates strong-to-weak distillation used for smaller models like Qwen3-4B.
A defining innovation of Qwen3-4B and the broader Qwen3 series is the integration of dual "thinking modes" within a single model, allowing flexible adaptation between analytic reasoning and rapid response generation. The default "thinking mode" generates intermediate reasoning, wrapping it in <think>...</think> tags prior to emitting a final answer. This is suitable for complex problem-solving, logical reasoning, mathematics, and coding tasks. In contrast, the "non-thinking mode" offers near-instant responses for straightforward queries by disabling explicit step-by-step reasoning.
Users can dynamically control the mode via prompt tags such as /think and /no_think or via configuration, with the model adhering to the most recent directive in interactive contexts. This approach allows fine-grained budget management for reasoning-intensive workflows, enhancing computational efficiency and offering a unified solution for tasks of varying difficulty.
Qwen3-4B also supports task-specific alignment and agentic capabilities—such as tool-calling—through integration with frameworks like Qwen-Agent. The instruction set and chat template enable nuanced response formatting and tool interaction, supporting complex multi-turn dialogue and utility-oriented workflows.
Qwen3-4B showcased executing advanced agentic reasoning—demonstrating its dynamic tool-calling capability and 'thinking mode' output structure. [Source]
Performance and Benchmarks
Evaluation across multiple benchmarks indicates that Qwen3-4B delivers competitive results relative to models with higher parameter counts. On tasks demanding logical reasoning, mathematics, coding, and multilingual understanding, Qwen3-4B matches or exceeds prior generations such as Qwen 2.5 7B, and demonstrates leadership among similarly sized models. Notable scores include 83.7 on MMLU-Redux, 77.5 on C-Eval, 97.0 on MATH-500, and 65.9 on MLogiQA, with strong showings in both thinking and non-thinking modes.
On extended context tasks, Qwen3-4B achieves an average RULER benchmark score of 85.2 in non-thinking mode, with performance gracefully diminishing as sequence lengths approach 128,000 tokens. Although thinking mode slightly reduces retrieval-oriented accuracy for long-range input, it maintains robust reasoning ability for tasks benefiting from detailed intermediate steps.
The model's multilingual performance reflects extensive pretraining coverage, enabling strong results in language understanding, translation, and multi-lingual benchmarks. STEM and code evaluation results are elevated through targeted data synthesis and alignment techniques.
Limitations
While Qwen3-4B offers diverse capabilities, certain limitations are observed. Performance on lengthy retrieval tasks is marginally reduced when operating in thinking mode, which may introduce extraneous generation not beneficial to information extraction. The use of greedy decoding strategies can result in repetitive or degraded responses, thus sampling parameters such as temperature and top-p should be carefully tuned as recommended. The static YaRN scaling, available in many open frameworks, can affect response quality for shorter sequences when enabled unnecessarily, so configuration should match application needs.
Strong-to-weak distillation, while computationally efficient, may result in modest reductions in specialized reasoning compared to full RL post-training, particularly for challenging problems introduced after thinking mode fusion. However, this is partially offset by overall gains in model versatility and general ability.
Model Family and Comparisons
Qwen3-4B belongs to a family of both dense and Mixture-of-Expert (MoE) models covering parameter scales from 0.6B up to 235B. Dense Qwen3 variants, such as Qwen3 0.6B, Qwen3 1.7B, Qwen3 8B, Qwen3 14B, and Qwen3 32B, are directly comparable to and often outperform previous Qwen2.5 models with larger footprints, highlighting architectural and scaling improvements. The MoE models, like Qwen3-30B-A3B and Qwen3-235B-A22B, further optimize performance-per-activation and minimize inference costs at larger scales.
Release Timeline
Qwen3-4B and the Qwen3 series were officially launched on April 29, 2025. The comprehensive technical report was published on arXiv on May 14, 2025, detailing methodologies, benchmarks, and best practices for deployment and research.