Launch a dedicated cloud GPU server running Laboratory OS to download and run Qwen 2.5 7B using any compatible app or framework.
Direct Download
Must be used with a compatible app, notebook, or codebase. May run slowly, or not work at all, depending on local system resources, particularly GPU(s) and available VRAM.
Open WebUI is an open-source, self-hosted web interface with a polished, ChatGPT-like user experience for interacting with LLMs. Integrates seamlessly with local Ollama installation.
The most full-featured web interface for experimenting with open source Large Language Models. Featuring a wide range of configurable settings, inference engines, and plugins.
Model Report
Alibaba Cloud / Qwen 2.5 7B
Qwen 2.5 7B is a transformer-based language model developed by Alibaba Cloud with 7.61 billion parameters, trained on up to 18 trillion tokens from multilingual datasets. The model features grouped query attention, 128,000 token context length, and supports over 29 languages. As a base model requiring further fine-tuning, it provides capabilities for text generation, structured data processing, and multilingual applications under Apache 2.0 licensing.
Explore the Future of AI
Your server, your data, under your control
Qwen2.5-7B is a foundational large language model (LLM) developed by the Qwen Team at Alibaba Group as part of the Qwen2.5 series. Released on September 19, 2024, Qwen2.5-7B occupies a key position among a suite of multilingual and multimodal models designed for a broad range of natural language processing tasks. Distinguished by its transformer architecture and extensive pretraining, Qwen2.5-7B is intended as a base model for further post-training or adaptation. The Qwen2.5 series also features specialized models targeting domains like code generation (Qwen2.5-Coder) and mathematics (Qwen2.5-Math).
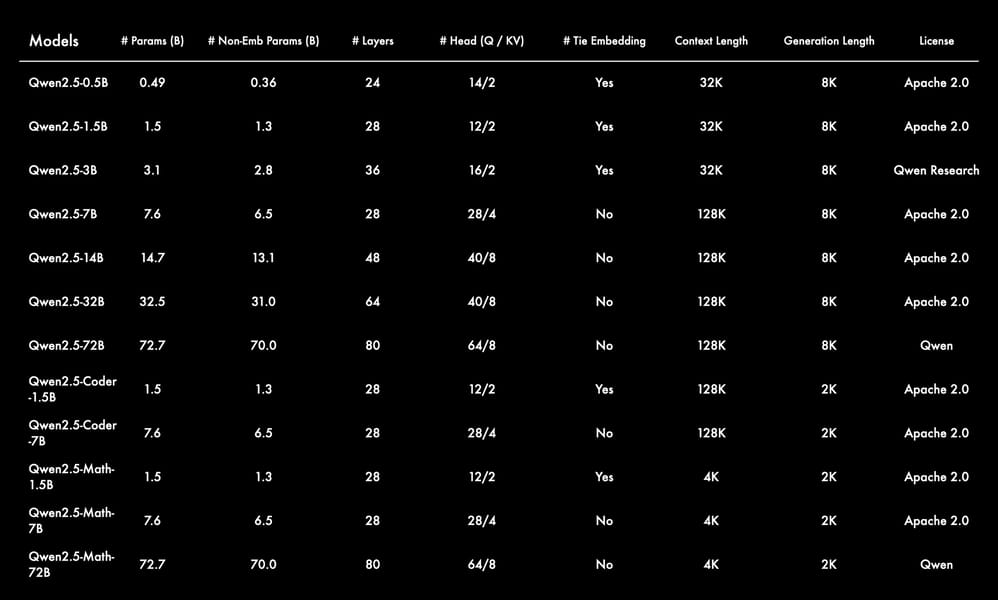
Specifications for the Qwen2.5 model family, including base, Coder, and Math variants, such as model size, architecture, context length, and license.
Overview video introducing the features and scope of the Qwen2.5 project. [Source]
Architecture and Training
At its core, Qwen2.5-7B is a transformer-based causal language model, comprising approximately 7.61 billion total parameters, with 6.53 billion allocated to non-embedding roles. The model utilizes 28 layers, a grouped query attention (GQA) mechanism—featuring 28 attention heads for queries and 4 for key/value—and incorporates advanced architectural features such as rotary position embeddings (RoPE), SwiGLU activation functions, root mean square normalization (RMSNorm), and attention QKV bias to enhance performance and efficiency. These enhancements support robust multilingual capabilities and improved generalization.
Qwen2.5-7B was trained on a dataset encompassing up to 18 trillion tokens, sourced from a diverse collection of large-scale multilingual and multimodal data, as described in the Qwen2.5 technical report. Post-training refinement is conducted through alignment with human preferences to enhance the model’s applicability in real-world tasks.
Technical Features and Capabilities
Qwen2.5-7B is designed as a base model, not instruction-tuned, making it suitable for fine-tuning and further adaptation across specialized applications. With support for context lengths up to 128,000 tokens and output sequences up to 8,000 tokens, the model is suitable for long-form text generation and contextual understanding. It provides broad multilingual support across more than 29 languages, including but not limited to Chinese, English, French, Spanish, Russian, Japanese, Arabic, Vietnamese, and Thai.
The Qwen2.5 series introduces several enhancements over its predecessor, Qwen2, as documented in the release blog. These enhancements include an increased scope of world knowledge, advancements in coding and mathematical problem solving, improved robustness to various system prompts, refined structured data understanding, and the generation of structured outputs such as JSON. The model design also supports prompt engineering scenarios, contributing to role-play and dialog management.
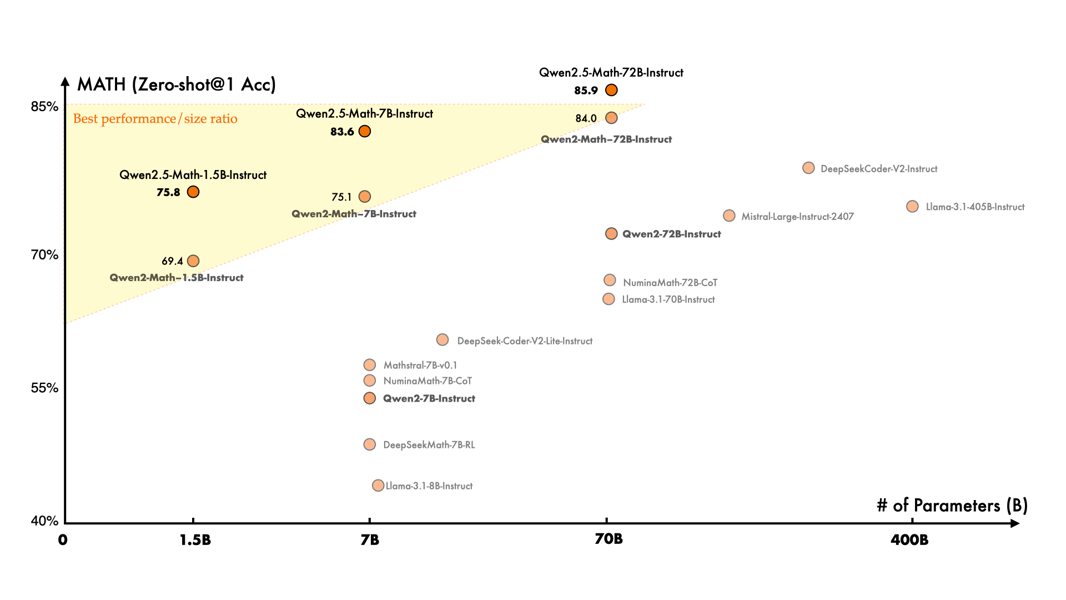
Math accuracy of Qwen2.5-Math models—including 7B—in comparison with other models, showing performance relative to parameter size. (Prompt: MATH zero-shot accuracy evaluation)
Benchmarking results for the Qwen2.5 series, including the 7B variant, are detailed in the Qwen2.5 release post. The family's performance on standard academic and industry evaluations is documented:
On MMLU (Massive Multitask Language Understanding), Qwen2.5 series models achieve scores above 85.
On HumanEval (code generation tasks), scores also surpass 85 for the series as a whole.
For mathematical reasoning, as evaluated on MATH, accuracies above 80 are reported.
Comparative analysis against other open-source models—such as Llama-3.1-70B and Mistral-Large-V2—indicates that larger Qwen2.5 variants exhibit performance characteristics reported as comparable to or surpassing these models.
Specialized expert models within the Qwen2.5 family, such as Qwen2.5-Coder and Qwen2.5-Math, achieve high performance on coding and mathematical problem sets in their respective benchmark evaluations.
Applications and Use Cases
As a base model, Qwen2.5-7B is designed predominantly for further post-training and development, rather than direct conversational deployment. Typical application areas include:
Natural language understanding and long-form text generation, supported by extended context handling and contextual understanding.
Multilingual applications such as translation and instruction following in over 29 languages.
Structured data processing, including the extraction, completion, and generation of tabular or JSON-formatted outputs.
Advanced tool integration and function calling for building AI agents, as supported by frameworks and toolkits.
Specialized reasoning tasks, including coding (through Qwen2.5-Coder expert models) and mathematical problem solving (using Qwen2.5-Math).
Its architecture and design support performance in agent-based environments, role-play scenarios, and settings that involve prompt engineering and persona management.
Model Family and Development Timeline
The Qwen2.5 series comprises a range of models—both base and instruction-tuned—from 0.5B to 72B parameters, with expert offshoots like Qwen2.5-Coder and Qwen2.5-Math optimizing for code and mathematical domains, respectively. Key milestones include the Qwen2.5 release in September 2024, Qwen2 in June 2024, and the subsequent introduction of Qwen3 in April 2025, which includes additional capabilities in reasoning and agent integration as detailed in the Qwen3 technical report.
Limitations and Licensing
Qwen2.5-7B is distributed as a base model and is specifically not recommended for direct end-user conversation tasks without further post-training or fine-tuning. Within its parameter class, there are inherent limitations compared to larger LLMs, particularly in handling complex tasks or nuanced dialog. Licensing for Qwen2.5-7B follows the Apache 2.0 standard, providing permissive access for research and development.