Note: Mistral Large 2 weights are released under a Mistral AI Research License, and cannot be utilized for commercial purposes. Please read the license to verify if your use case is permitted.
Laboratory OS
Launch a dedicated cloud GPU server running Laboratory OS to download and run Mistral Large 2 using any compatible app or framework.
Direct Download
Must be used with a compatible app, notebook, or codebase. May run slowly, or not work at all, depending on local system resources, particularly GPU(s) and available VRAM.
Open WebUI is an open-source, self-hosted web interface with a polished, ChatGPT-like user experience for interacting with LLMs. Integrates seamlessly with local Ollama installation.
The most full-featured web interface for experimenting with open source Large Language Models. Featuring a wide range of configurable settings, inference engines, and plugins.
Model Report
Mistral AI / Mistral Large 2
Mistral Large 2 is a dense transformer-based language model developed by Mistral AI with 123 billion parameters and a 128,000-token context window. The model demonstrates strong performance across multilingual tasks, code generation in 80+ programming languages, mathematical reasoning, and function calling capabilities. It achieves 84% on MMLU, 92% on HumanEval, and 93% on GSM8K benchmarks while maintaining concise output generation.
Explore the Future of AI
Your server, your data, under your control
Mistral Large 2 is a dense generative large language model (LLM) developed by Mistral AI and released in July 2024. Designed for general-purpose language modeling, Mistral Large 2 is characterized by an extensive parameter count, a substantial context window, comprehensive multilingual abilities, and high performance in tasks involving code generation and mathematical reasoning. This model is a subsequent offering from Mistral AI, with observed improvements in accuracy, efficiency, and agentic capabilities compared to its predecessors, while remaining publicly available under a dedicated research license as outlined by Mistral AI.
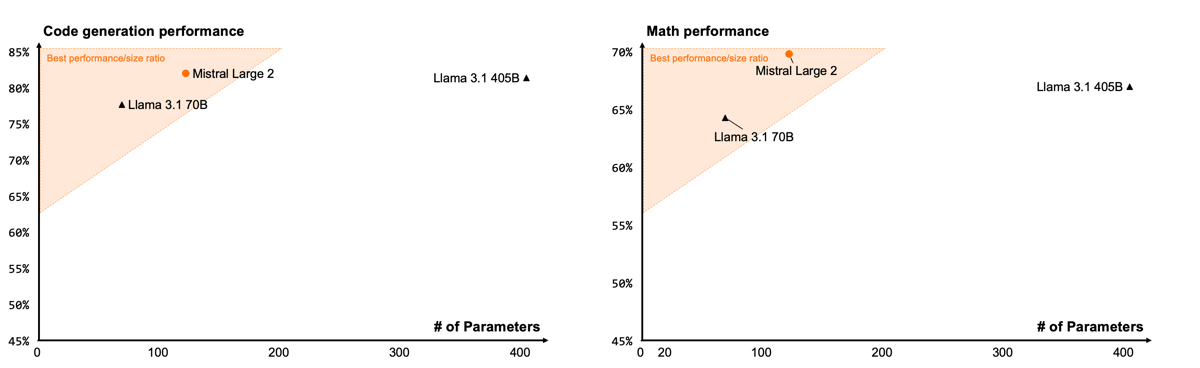
Comparison of code and math performance for Mistral Large 2 and peer models, showing performance relative to parameter count.
Mistral Large 2 is constructed as a dense transformer-based language model, comprising 123 billion parameters. It features a context window of 128,000 tokens, enabling it to handle extended documents and complex dialogue scenarios. The model was trained on a large proportion of multilingual texts and a substantial corpus of source code, leveraging advancements in both data curation and architecture engineering, as described in the official release blog.
Mistral Large 2’s architecture is optimized for single-node inference, supporting large-throughput operations. Special attention was given to mitigating hallucination, enhancing mathematical reasoning, and instruct-following performance through targeted fine-tuning regimens. Training data emphasized diversity in language and code domain coverage, supporting both general and specialized tasks.
Multilingual and Coding Capabilities
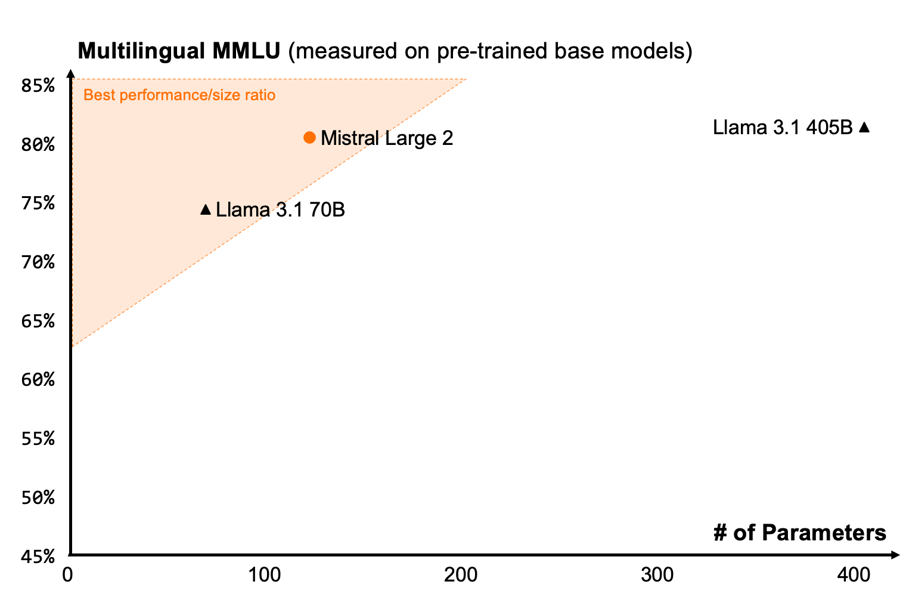
One of the defining characteristics of Mistral Large 2 is its robust multilingual proficiency. The model supports dozens of languages, including but not limited to English, French, German, Spanish, Italian, Dutch, Russian, Chinese, Japanese, Korean, Arabic, and Hindi. Performance on multilingual evaluation benchmarks such as MMLU demonstrates strong results across a wide range of languages, positioning the model as a versatile tool for global applications. This multilingual support is highlighted in direct comparisons with other large open models, as shown in benchmarking data from the Mistral Large 2 release.
Performance of Mistral Large 2 on multilingual MMLU benchmarks, illustrating efficiency relative to model size.
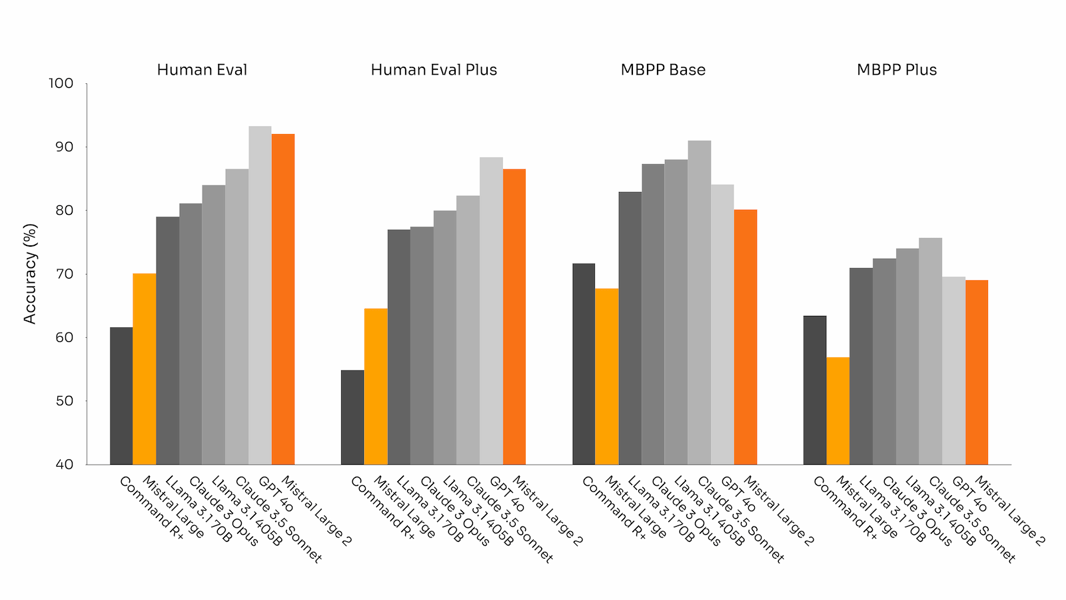
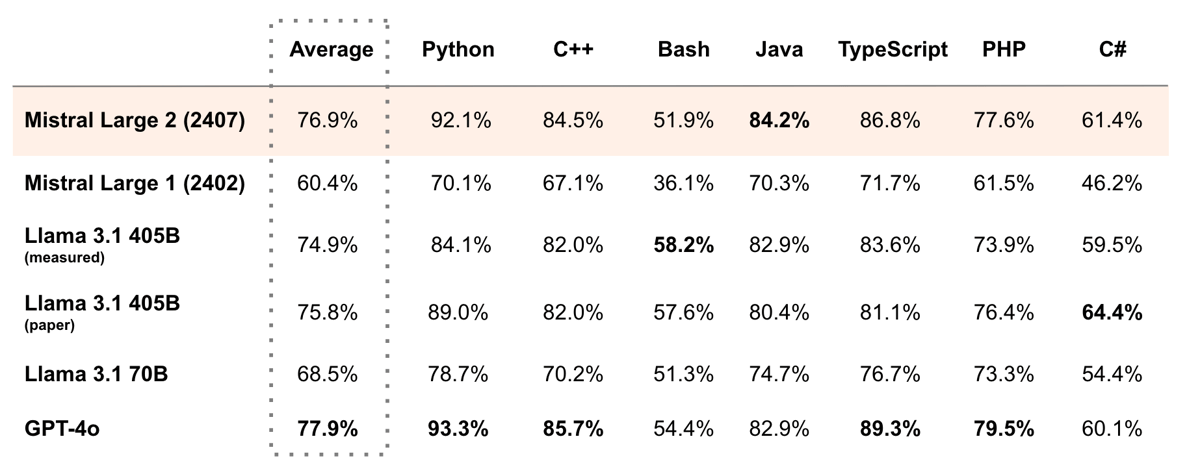
In addition, Mistral Large 2 exhibits high proficiency in code-related tasks. Trained on at least 80 distinct programming languages—including Python, Java, C++, JavaScript, Bash, Swift, and Fortran—it demonstrates high capabilities in both code generation and completion, consistently outperforming prior Mistral models and performing competitively with contemporary models in code-focused benchmarks.
Code generation accuracy across different models, with Mistral Large 2 performing competitively on Human Eval and MBPP benchmarks.
Mistral Large 2 demonstrates performance across a variety of standardized language modeling tasks, as evidenced by publicly reported evaluations in code generation, mathematical reasoning, general instruction following, and multilingual benchmarks.
For general knowledge and logic, the model attains an MMLU accuracy of 84%. It positions itself relative to competing open models. On code-generation tasks, it reports 92% on the HumanEval benchmark and high results on HumanEval Plus and MBPP datasets. In mathematical reasoning, Mistral Large 2’s GSM8K score is 93%, and it achieves high marks on zero- and few-shot problem-solving tasks.
Comparison of Mistral Large 2 and other models on GSM8K and Math Instruct benchmarks for mathematical reasoning.
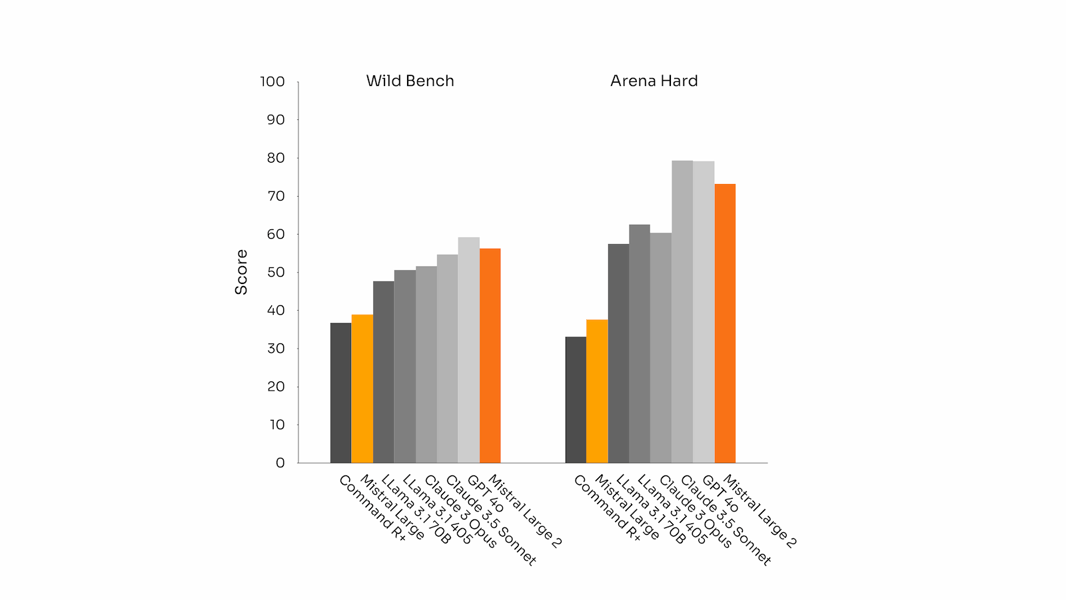
Instruction tuning has resulted in high alignment and conversational capacities. The model’s WildBench and Arena Hard results reflect its capacity for robust handling of open-ended dialogue and challenging prompts.
Performance on alignment and instruction benchmarks Wild Bench and Arena Hard, demonstrating Mistral Large 2’s conversational capabilities.
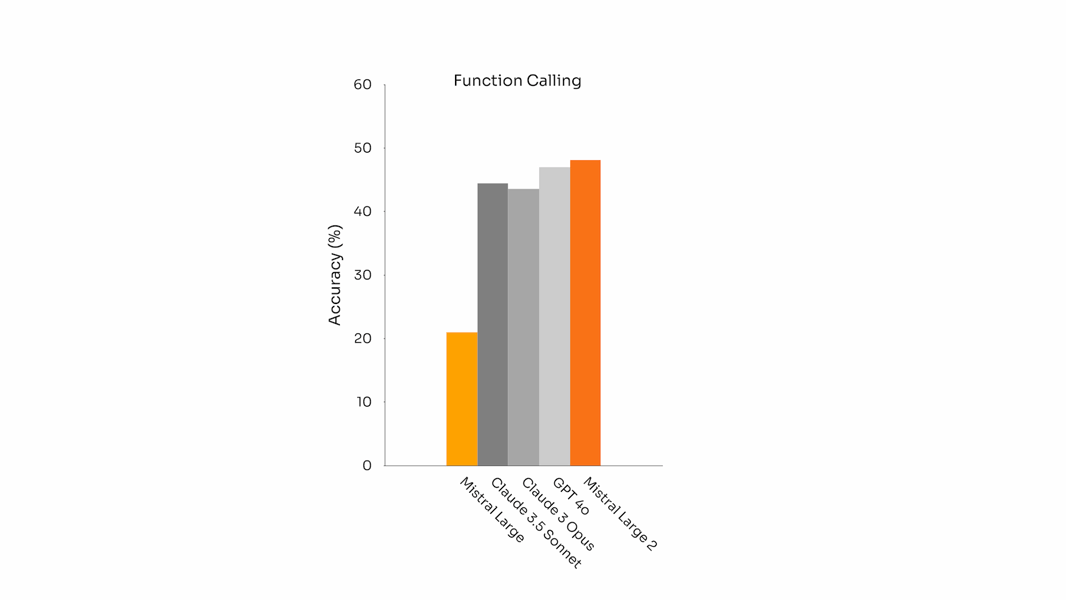
Mistral Large 2 also introduces refinements in agentic and function-calling abilities. The model is equipped for both parallel and sequential native function execution, and is capable of outputting structured responses in JSON format. Its accuracy on function-calling tasks is on par with other models, facilitating use in complex retrieval and integration scenarios.
Function calling benchmark accuracy for Mistral Large 2 and peer models, indicating strong agentic capabilities.
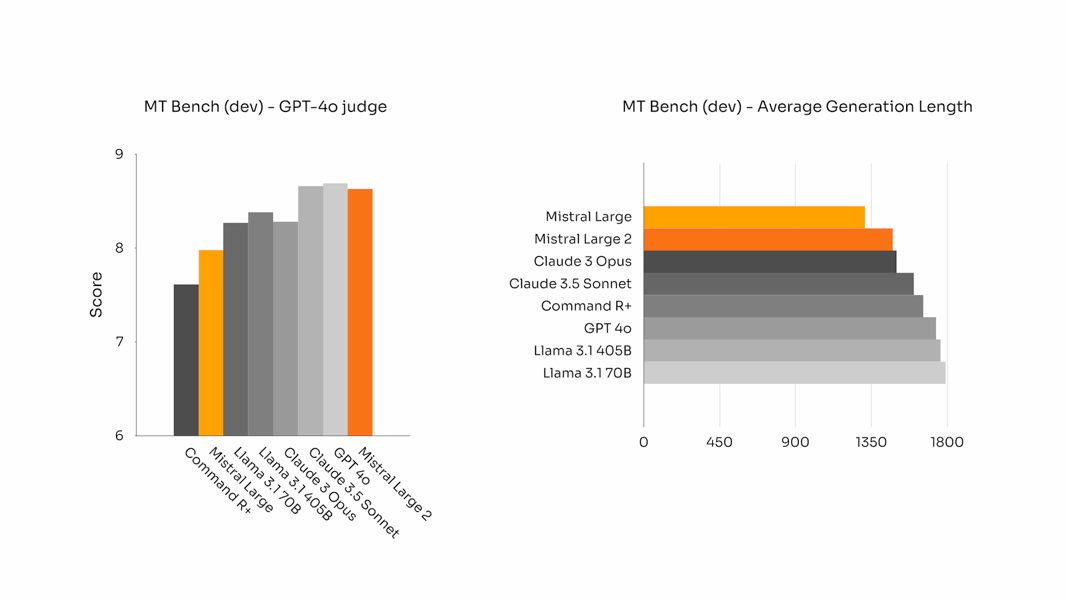
The design also emphasizes concise outputs. Benchmark results from MT Bench reveal that Mistral Large 2 produces succinct and relevant responses, an attribute useful for enterprise and high-throughput applications.
Left: MT Bench evaluation by GPT-4o, showing high score for Mistral Large 2. Right: average generation length chart, illustrating the model’s tendency for concise outputs.
The advanced feature set of Mistral Large 2 enables a wide range of applications. Its strong coding skills are leveraged in software engineering and data analysis workflows, while mathematical reasoning supports domains such as scientific research and education. General-purpose language capabilities facilitate summarization, translation, knowledge retrieval, content generation, and instructional dialogue across multiple languages.
The model’s support for agentic workflows—native function calling and complex reasoning—enables integration into business process automation, virtual assistants, and research platforms. Function calling and structured JSON output are particularly oriented towards use in enterprise data pipelines and interactive applications.
Limitations and Licensing
Mistral Large 2, as released, does not include integrated moderation mechanisms. The developers encourage community engagement to establish appropriate guardrails for use in environments requiring output moderation, as stated in the official release materials.
The model is distributed under the Mistral AI Research License, which authorizes non-commercial research, personal, or academic use. Commercial usage, including commercial deployment or business-related development, requires a dedicated commercial license from Mistral AI. The license clarifies attribution, derivative works, distribution requirements, and provides no warranty. Users are solely responsible for content generated using the model, and must not imply endorsement by Mistral AI.
Model Availability and Ecosystem
Mistral Large 2 is available for research purposes with downloadable weights and integration support across frameworks such as transformers and mistral_inference.
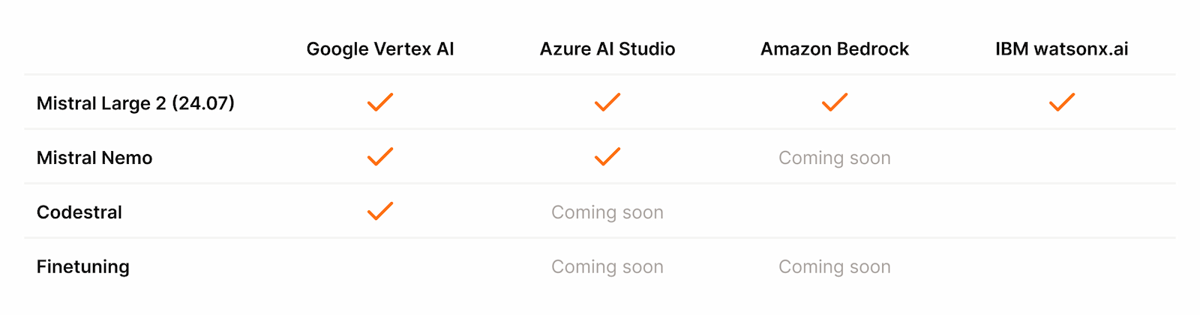
Within the broader Mistral model family, Mistral Large 2 builds on techniques pioneered in earlier models, such as Codestral and Mistral Nemo, and consolidates previous innovations into a single advanced architecture. Existing specialist models, general-purpose models, and fine-tuning workflows remain accessible for non-commercial research and are progressively updated in line with new releases.
External Resources
For additional details and the most current resources, refer to the following: