Note: Codestral 22B v0.1 weights are released under a Non-Production License, and cannot be utilized for commercial purposes. Please read the license to verify if your use case is permitted.
Laboratory OS
Launch a dedicated cloud GPU server running Laboratory OS to download and run Codestral 22B v0.1 using any compatible app or framework.
Direct Download
Must be used with a compatible app, notebook, or codebase. May run slowly, or not work at all, depending on local system resources, particularly GPU(s) and available VRAM.
Open WebUI is an open-source, self-hosted web interface with a polished, ChatGPT-like user experience for interacting with LLMs. Integrates seamlessly with local Ollama installation.
The most full-featured web interface for experimenting with open source Large Language Models. Featuring a wide range of configurable settings, inference engines, and plugins.
Model Report
Mistral AI / Codestral 22B v0.1
Codestral 22B v0.1 is an open-weight code generation model developed by Mistral AI with 22.2 billion parameters and support for over 80 programming languages. The model features a 32k token context window and operates in both "Instruct" and "Fill-in-the-Middle" modes, enabling natural language code queries and token prediction between code segments for IDE integration and repository-level tasks.
Explore the Future of AI
Your server, your data, under your control
Codestral 22B v0.1 is an open-weight generative AI model for code generation developed by Mistral AI. Released on May 29, 2024, Codestral is designed to assist with automated software development tasks, supporting more than 80 programming languages, and is aimed at both research and practical applications in coding and software engineering.
Model Architecture and Training
At its core, Codestral 22B v0.1 is a causal language model comprising 22.2 billion parameters and utilizing BF16 tensor precision for efficient computation. The architecture and technology are tailored for programming-related tasks, allowing it to predict and generate syntactically correct code across a wide array of programming environments. As detailed by Mistral AI, the model was trained on a comprehensive dataset curated from publicly available codebases, encompassing over 80 programming languages. Notable languages include Python, Java, C, C++, JavaScript, Bash, as well as more specialized environments such as Swift and Fortran.
Codestral employs two distinctive modes of operation: "Instruct", where the model is prompted with natural language queries about code, and "Fill-in-the-Middle" (FIM), which enables token prediction between user-provided code prefixes and suffixes. The FIM capability is particularly valuable for integrated development environment (IDE) plug-ins and code-editing scenarios.
Benchmark Performance and Evaluation
Codestral 22B demonstrates competitive performance across industry-standard code generation and completion tasks. Its 32k token context window enables the model to handle long-range dependencies in extended codebases, which is especially beneficial for repository-level editing or completion tasks.
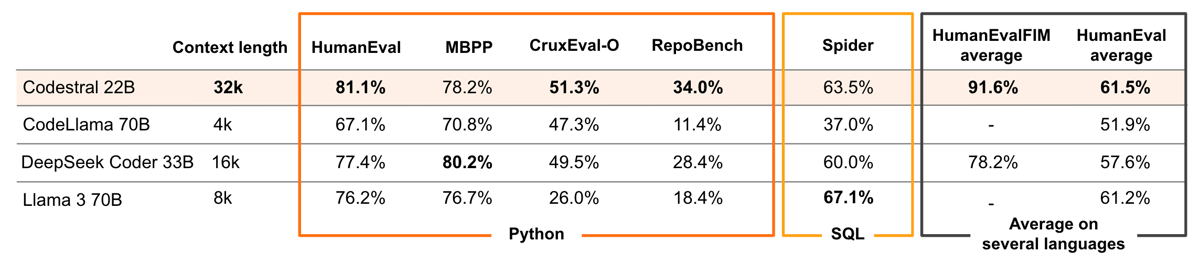
Codestral 22B compared to other large language models across code generation benchmarks, highlighting performance in RepoBench, HumanEval, and other tasks. The large context window supports advanced repository-level completion.
On the RepoBench evaluation, Codestral 22B achieves high scores facilitated by its extended context window. It outperforms comparably sized and even larger models, such as DeepSeek Coder 33B and CodeLlama 70B, across evaluation suites including HumanEval, MBPP, and CruxEval-O, as well as long-range tasks.
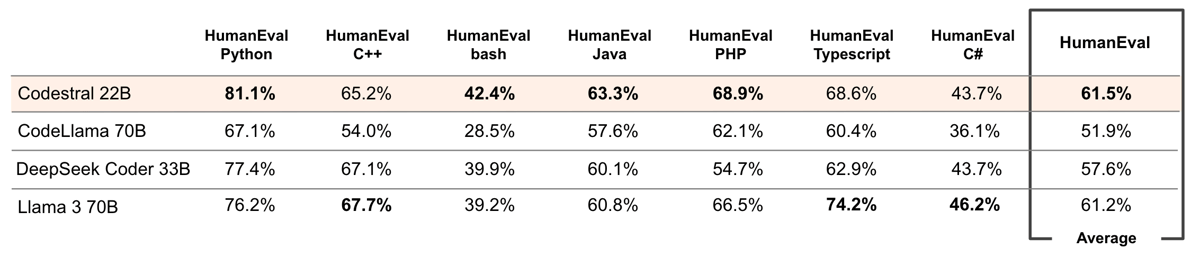
Codestral 22B's HumanEval performance across Python, C++, Bash, Java, PHP, TypeScript, and C#, showing competitive results compared to other leading code models.
In benchmark assessments specifically for code synthesis, Codestral achieves notable results on tests such as HumanEval for Python and other languages, as well as the MBPP (Mostly Basic Python Problems) and Spider (SQL) benchmarks. For example, on the Kotlin-HumanEval benchmark, the model achieved a pass@1 rate of 73.75 at temperature 0.2, marginally surpassing performance observed with GPT-4-Turbo and GPT-3.5-Turbo.
Codestral’s FIM capability also demonstrates strong outcomes, as highlighted by detailed HumanEval FIM scores in Python, JavaScript, and Java.
Fill-in-the-Middle (FIM) HumanEval pass@1 scores for Codestral 22B, demonstrating strong code completion abilities in Python, JavaScript, and Java.
Codestral 22B is engineered for a wide range of programming applications. It can generate both complete functions and partial code snippets based on user instructions, facilitate automated writing of unit and integration tests, and execute explanatory or refactoring tasks over code samples. Its proficiency with fill-in-the-middle queries makes it well-suited for integration with modern IDEs, supporting workflow features such as real-time code completion, inline code editing, and interactive conversational coding assistance.
The FIM interface enables developers to prompt the model with incomplete code blocks, efficiently filling gaps between known code segments—an approach that accelerates bug fixing, documentation, and collaborative programming efforts.
Codestral is incorporated into several third-party frameworks and applications, enhancing agentic application development within environments such as LlamaIndex and LangChain. The model’s fluency in natural language also allows it to answer code-related queries, explain program logic, and support developers in understanding unfamiliar codebases.
Limitations and Responsible Use
While offering broad support for code generation and understanding tasks, Codestral 22B v0.1 does not include integrated moderation mechanisms or safety filters. As such, Mistral AI encourages community involvement in developing downstream guardrails to ensure responsible use and to adapt the model for deployment in production contexts.
The model is openly distributed under the Mistral AI Non-Production License (MNPL-0.1), which restricts its use to research and non-commercial settings unless separate, explicit licensing is acquired. This open-weight approach supports scientific transparency and reproducibility but also places a responsibility on downstream users to manage and monitor outputs appropriately.
Release, Availability, and Comparative Position
Codestral 22B v0.1 was officially introduced on May 29, 2024, adding to the expanding ecosystem of AI-driven code generation tools. The model is the subject of direct comparison with a variety of both code-specialized and generalist large language models, such as CodeLlama 70B, DeepSeek Coder 33B, and GPT-4-Turbo, across a range of public benchmarks.
Its strong performance in long-context and language-diverse tasks positions it distinctively among open-weight code generation models, particularly with respect to FIM operations and repository-scale completions.
External Resources
Further information and resources for Codestral 22B v0.1 can be found at: