Launch a dedicated cloud GPU server running Laboratory OS to download and run CodeLlama 70B using any compatible app or framework.
Direct Download
Must be used with a compatible app, notebook, or codebase. May run slowly, or not work at all, depending on local system resources, particularly GPU(s) and available VRAM.
Open WebUI is an open-source, self-hosted web interface with a polished, ChatGPT-like user experience for interacting with LLMs. Integrates seamlessly with local Ollama installation.
The most full-featured web interface for experimenting with open source Large Language Models. Featuring a wide range of configurable settings, inference engines, and plugins.
Model Report
Meta / CodeLlama 70B
CodeLlama 70B is a generative AI model developed by Meta for code synthesis and programming tasks, built on the Llama 2 transformer architecture with 70 billion parameters. The model supports up to 100,000 tokens of input context and was trained on 1 trillion tokens of code data across multiple programming languages including Python, C++, Java, and others, with specialized variants available for Python-specific tasks and instruction-following capabilities.
Explore the Future of AI
Your server, your data, under your control
Code Llama 70B is a generative AI model developed by Meta AI for code synthesis, understanding, and related tasks. As part of the Code Llama family, it utilizes large language model technology, building upon the Llama 2 architecture for applications in software engineering and programming assistance. Released in January 2024, Code Llama 70B is accessible for both research and commercial use under a community license. This article presents an in-depth review of its architecture, training techniques, capabilities, benchmarks, and limitations.
Code Llama 70B demonstrates live debugging: after receiving a prompt to ‘fix the bug in the code above and explain the fix’, the model provides a corrected Python snippet and a detailed explanation.
Code Llama 70B is based on a transformer architecture similar to Llama 2, with adaptations for code-centric tasks. The 70B parameter count refers to the number of trainable weights; it is the largest member of the Code Llama suite. Its design emphasizes compatibility with long-context operations, supporting up to 100,000 tokens of input for tasks such as understanding and generating large codebases.
The model family is available in several variants: the foundational Code Llama 70B, a Python-specialized version fine-tuned on extensive Python data, and an instruction-following variant, Code Llama 70B-Instruct, specifically adjusted to interpret and respond to natural language directions in code-related contexts.
Training of Code Llama 70B was conducted on a corpus comprising 1 trillion tokens of code and code-related data, with the Python variant undergoing additional fine-tuning on over 100 billion Python tokens. Instruction-following versions were optimized with datasets pairing natural language instructions with corresponding code outputs, intended to improve the model’s comprehension of developer queries and alignment with user intent, as documented in the Code Llama research paper.
Capabilities: Code Generation and Comprehension
As a generative model, Code Llama 70B produces source code from both natural language and code prompts. Its abilities cover a spectrum of programming tasks, including code generation, code completion, debugging, and the translation of code snippets into natural language explanations. The model is proficient across several programming languages, including Python, C++, Java, PHP, TypeScript, C#, and Bash.
Code Llama 70B interprets and explains a Python function, showcasing its ability to generate natural language descriptions from code.
The model’s long-context capability enables it to manage and analyze extended codebases, facilitating applications such as refactoring, documentation generation, and multi-part code reviews. Specialized instruction-tuning further enhances usefulness for scenarios where developers require step-by-step guidance or safe, helpful outputs on programming problems.
Using a code snippet as input, Code Llama 70B summarizes the code’s purpose in natural language, reflecting code comprehension skills.
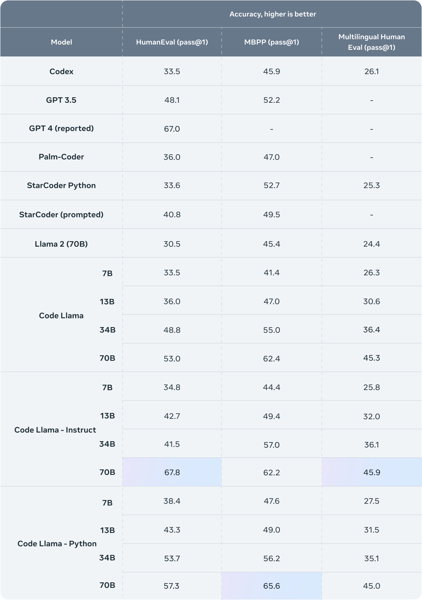
Benchmark evaluations place Code Llama 70B as a model with competitive performance among open source models for coding tasks. Its performance has been assessed using widely recognized metrics such as HumanEval and Mostly Basic Python Programming (MBPP). HumanEval measures the accuracy of code completion based on function docstrings, while MBPP evaluates the model’s ability to synthesize correct code from natural language descriptions.
Quantitative comparison of Code Llama models and other large language models on HumanEval, MBPP, and Multilingual HumanEval—demonstrating Code Llama 70B’s competitive coding accuracy.
On these benchmarks, Code Llama 70B-Instruct and Code Llama 70B-Python achieve high scores among open models. For example, the Code Llama 34B parameter variant achieves a 53.7% pass@1 rate on HumanEval and a 56.2% pass@1 on MBPP. The 70B models surpass these metrics, particularly on Python-specific tasks, as outlined in the official benchmark comparisons.
Applications and Model Variants
Code Llama 70B’s versatility supports a variety of programming applications, from software development and code review to educational tools for learning programming concepts. It can function as an assistant within integrated development environments (IDEs), facilitating code completion, real-time debugging, and documentation generation.
The suite comprises several model variants:
Code Llama 70B (general coding)
Code Llama 70B-Python (fine-tuned for Python tasks)
Code Llama 70B-Instruct (instruction-following for natural language queries)
Developers are encouraged to utilize the instruct variants for most use cases involving human interaction, as these versions have been specifically aligned for helpfulness and safety in responding to developer prompts. Base and language-specialized versions are appropriate for tasks that require raw code synthesis or domain-specific expertise.
Earlier models in the Code Llama family, such as Code Llama 7B, Code Llama 13B, and Code Llama 34B parameter models, offer a trade-off between inference speed and code generation ability. These smaller models are useful for low-latency or resource-constrained scenarios, and some include features like fill-in-the-middle (FIM) completion for advanced code editing workflows, as documented in the official GitHub repository.
Limitations, Licensing, and Responsible Use
Code Llama 70B, like other large language models, is subject to inherent limitations including the potential for unpredictable responses and inaccuracies. Its training was centered on English and programming languages, and its performance on non-English or niche codebases may vary. Outputs should be rigorously evaluated and safety testing conducted before deployment in sensitive applications. Data on model robustness and failure modes is detailed in the Code Llama arXiv preprint and associated documentation.