Launch a dedicated cloud GPU server running Laboratory OS to download and run CodeLlama 7B using any compatible app or framework.
Direct Download
Must be used with a compatible app, notebook, or codebase. May run slowly, or not work at all, depending on local system resources, particularly GPU(s) and available VRAM.
Open WebUI is an open-source, self-hosted web interface with a polished, ChatGPT-like user experience for interacting with LLMs. Integrates seamlessly with local Ollama installation.
The most full-featured web interface for experimenting with open source Large Language Models. Featuring a wide range of configurable settings, inference engines, and plugins.
Model Report
codellama / CodeLlama 7B
CodeLlama 7B is a transformer-based language model developed by Meta, built on the Llama 2 architecture and specialized for code generation, completion, and understanding tasks. The model supports multiple programming languages including Python, C++, Java, and JavaScript, with capabilities for fill-in-the-middle code completion and extended context windows up to 100,000 tokens for handling large codebases.
Explore the Future of AI
Your server, your data, under your control
Code Llama 7B is an open-access large language model designed by Meta for code synthesis, understanding, and related programming tasks. As a member of the broader Code Llama suite, it specializes in generating, completing, and analyzing code across a range of programming languages. Developed, trained, and released by Meta between January and July 2023, Code Llama 7B leverages advancements in transformer architectures to address the challenges of code completion, debugging, and comprehension within both research and industry settings.
Code Llama 7B provides a natural language explanation of a Python function when prompted, illustrating its code understanding capabilities.
Code Llama 7B is constructed upon the Llama 2 architecture, re-trained and fine-tuned on code-centric data to enhance its performance in programming environments. The model employs a transformer-based, auto-regressive design which is adept at generating sequences of tokens, effectively enabling tasks such as code autocompletion, fill-in-the-middle infilling, and code summarization. Its architecture allows for stable generations with extended context windows, supporting up to 100,000 tokens, thanks to training on sequences of 16,000 tokens. This capacity makes it capable of reasoning over and generating large codebases, which is particularly valuable in professional software engineering and debugging scenarios.
Among its notable features is the fill-in-the-middle (FIM) capability, which allows the model to insert code within existing files rather than only producing code snippets sequentially. The model comes in several specialized variants, including a Python-focused edition and an Instruct variant fine-tuned for instruction-following scenarios, helping to provide guided, safe, and task-oriented outputs. Multilingual code support covers languages such as Python, C++, Java, PHP, TypeScript (JavaScript), C#, and Bash, catering to a broad spectrum of software development contexts. Further, the model’s large context window aids in handling longer code generation and complex debugging tasks by incorporating more substantial pieces of existing code as input.
A demonstration of Code Llama 7B automatically identifying, correcting, and explaining a bug in a Python code snippet. Prompt: '# Fix the bug in the code above and explain the fix.'
The development of Code Llama 7B involved extensive re-training of Llama 2 weights using a curated corpus of source code and code-related texts. The dataset encompassed approximately 500 billion tokens, drawn from diverse sources to ensure coverage across many programming languages and paradigms. The specialized Python variant received further fine-tuning on a dedicated subset comprising 100 billion tokens exclusively of Python code. Meta utilized its Research Super Cluster for large-scale training.
Instruction tuning for the Instruct version entailed feeding the model natural language prompts alongside expected outputs, promoting adherence to user instructions and safety protocols. This targeted training approach enhances the model’s ability to generate precise and safe responses to user requests, making it well-suited for deployment in code assistance tools and educational resources.
Code Llama 7B generates a concise summary of a given Python code segment in response to the prompt: '# Summarize this code.'
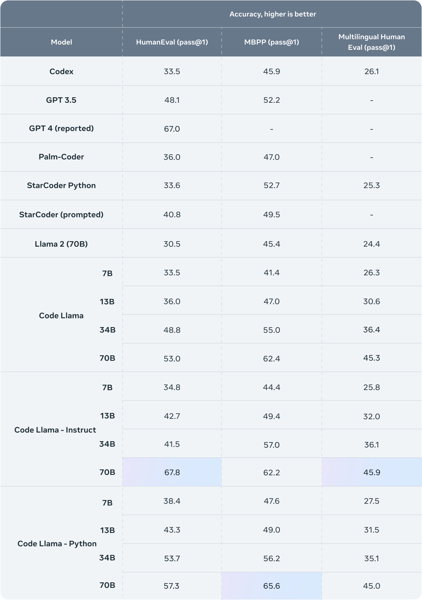
Code Llama 7B and its family variants have been rigorously evaluated against industry-standard benchmarks including HumanEval, Mostly Basic Python Programming (MBPP), and MultiPL-E. Results indicate that Code Llama 7B exhibits strong performance relative to other public large language models and earlier iterations, particularly in code generation, completion, and comprehension tasks. The Python-specialized model has demonstrated higher accuracy on Python-centric benchmarks, in some cases surpassing larger general-purpose models in execution correctness.
Quantitative comparison of Code Llama variants—including 7B—against other large language models on code-generation benchmarks such as HumanEval and MBPP. Higher values indicate greater accuracy.
According to the official research publication, Code Llama models consistently outperform comparable open-access code models and predecessor architectures, particularly for real-time completion scenarios requiring lower latency.
Applications and Use Cases
The model is designed to facilitate a wide range of code-related tasks. In practice, developers employ Code Llama 7B for code autocompletion, bug detection and correction, code summarization, and the automated generation of explanatory documentation. The instruction-tuned variant is suitable for contexts where guided interaction and safety are priorities, such as educational environments or as part of interactive code assistant systems. The Python-specialized model is optimized for workflows concentrated in Python, delivering improved results on Python generation and comprehension tasks.
Code Llama 7B's multilingual support and large context window enable its use across diverse programming projects, from lightweight real-time completion in integrated development environments (IDEs) to deeper analysis and refactoring of substantial codebases. Ongoing testing and research focus on extending the model’s language and task coverage while maintaining safety and reliability.
Model Limitations, License, and Sustainability
Despite the model’s advanced capabilities, several important limitations have been identified. Outputs may occasionally be inaccurate, unexpected, or fail to generalize outside the conditions of training data, particularly with inputs in languages other than English or in highly specialized programming contexts. The model is not recommended for general-purpose natural language processing tasks, as it is optimized for code-oriented interactions. Developers are encouraged to perform context-specific safety evaluations prior to deployment.
Early red teaming assessments indicate that Code Llama 7B generates safer code than prior general language models, but comprehensive risk assessment remains necessary for production scenarios.
Code Llama 7B is released under the Meta Community License, permitting both research and commercial usage within the terms established by Meta. Users must adhere to Meta’s acceptable use policy.
In terms of sustainability, training all Code Llama models—across nine configurations—required 400,000 GPU hours, primarily on A100-80GB hardware. This process generated estimated emissions of 65.3 tCO2eq, which were fully offset in alignment with Meta’s sustainability program.