Launch a dedicated cloud GPU server running Laboratory OS to download and run CodeLlama 13B using any compatible app or framework.
Direct Download
Must be used with a compatible app, notebook, or codebase. May run slowly, or not work at all, depending on local system resources, particularly GPU(s) and available VRAM.
Open WebUI is an open-source, self-hosted web interface with a polished, ChatGPT-like user experience for interacting with LLMs. Integrates seamlessly with local Ollama installation.
The most full-featured web interface for experimenting with open source Large Language Models. Featuring a wide range of configurable settings, inference engines, and plugins.
Model Report
Meta / CodeLlama 13B
CodeLlama 13B is a code-focused large language model developed by Meta, derived from Llama 2 architecture and trained on approximately 500 billion tokens of programming-related data. The model supports code generation, completion, debugging, and understanding across multiple programming languages including Python, C++, Java, and JavaScript, with context windows up to 100,000 tokens during inference.
Explore the Future of AI
Your server, your data, under your control
Code Llama 13B is a large language model (LLM) developed by Meta, purpose-built for programming tasks such as code generation, completion, and understanding. Introduced on August 24, 2023, this model is part of the broader Code Llama family, itself derived from the architecture of Llama 2. Code Llama 13B leverages domain-specific training on code and code-related data, providing robust support for a wide array of programming languages and use cases in software development.
Code Llama 13B automatically fixes a bug in Python code and provides a detailed explanation of the correction, illustrating its utility in automated debugging and code understanding tasks.
Code Llama 13B utilizes an auto-regressive transformer-based architecture, building on the design of Llama 2. The model is specifically adapted for programming through continued pretraining on a mixture of source code, natural language about code, and technical documentation. This training process encompasses approximately 500 billion tokens primarily focused on popular programming languages such as Python, C++, Java, JavaScript (TypeScript), PHP, C#, and Bash.
The model's development took place on Meta's Research Super Cluster, utilizing proprietary training libraries and methods for large-scale optimization. Code Llama 13B incorporates fill-in-the-middle (FIM) training, which enables the model to insert code snippets into existing files—a capability crucial for effective code completion and automated refactoring. The model can process sequences up to 16,000 tokens during training, with support for context windows as large as 100,000 tokens during inference in certain configurations.
Technical Capabilities
Code Llama 13B is designed to address a broad spectrum of software engineering workflows. At its core, it generates source code based on user-supplied prompts—these may be written in natural language, code, or a combination of both. The model excels at:
Code Generation: Synthesizing functions, modules, or full scripts from descriptions or partial code.
Code Completion: Predicting code segments necessary to complete a partial file, including in the middle of existing code.
Code Understanding: Producing natural language explanations or summaries of complex source code.
Debugging Assistance: Identifying and amending code defects, then rationalizing the solution in human-readable language.
Code Llama 13B provides a natural language explanation of a Python function, exemplifying its capabilities for code understanding and education. (Prompt: '# Explain this code in natural language.')
Code Llama 13B generates a summary of a Python script, supporting developers in understanding and documenting codebases. (Prompt: '# Summarize this code.')
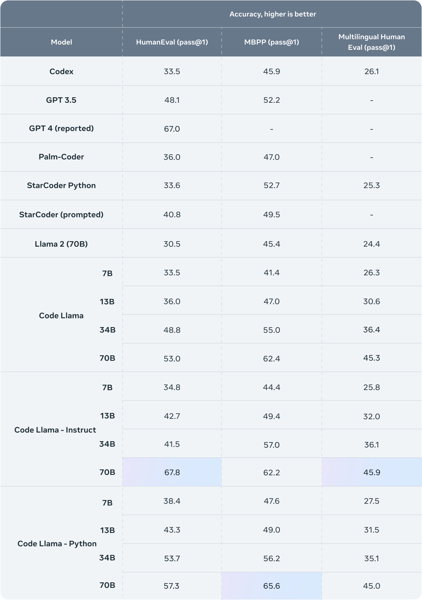
Quantitative evaluation demonstrates that Code Llama 13B achieves strong accuracy across standard coding benchmarks. On metrics such as HumanEval, MBPP, and MultiPL-E, Code Llama models, including the 13B variant, consistently surpass prior open-source baselines and earlier versions of Llama. Detailed benchmarking data, as shown below, places Code Llama 13B among the top-performing publicly available models at the time of release, with especially competitive results in multilingual code tasks and Python specialization.
Comparison of Code Llama models and other LLMs on HumanEval, MBPP, and Multilingual HumanEval. Code Llama 13B achieves high accuracy scores, reflecting its capability in diverse coding tasks.
These benchmarks highlight Code Llama 13B's balance between computational efficiency and output quality. The model enables real-time assistance for code completion, debugging, and synthesis, without the higher latency associated with larger models such as the 34B or 70B parameter variants.
Applications and Use Cases
Code Llama 13B finds utility in a range of programming environments. As a productivity tool, it expedites workflows for professional developers by completing code, fixing bugs, generating documentation, and refactoring existing projects. Within educational settings, the model aids new programmers by offering clear explanations, generating robust boilerplate, and lowering barriers to software creation. Its design also supports more advanced applications, such as automated migration between programming languages and safe, instruction-following code generation.
Specialized versions within the Code Llama family, including instruction-tuned and Python-focused models, further enable adaptation to distinct use cases. For instance, the 'Instruct' variant is optimized for responding to user requests with aligned, safe behaviors, while the 'Python' variant is fine-tuned for Python development and evaluation as described in the model documentation.
Limitations and Responsible Use
As with all generative AI models, Code Llama 13B exhibits certain limitations. The model's outputs, while effective in many contexts, are not always perfectly accurate or fully predictable. Developers should not treat Code Llama 13B as a general-purpose language model, as its training and optimization are focused solely on code and code-related tasks.
Biases and risks inherent in the model's training data or generative process may result in unexpected or suboptimal outputs, especially when applied outside of intended software engineering tasks or in languages other than English. Safety evaluations documented in Meta's research indicate improved behavior over earlier models in code security scenarios, but the onus remains on users to institute rigorous safety checks and validation specific to their deployment context.
Code Llama models are provided under the Llama 2 community license, which enables both academic research and commercial application, while mandating compliance with the accompanying acceptable use policy.
Model Family and Release
Code Llama is offered in multiple parameter sizes—7B, 13B, 34B, and 70B—each available in base, instruction-tuned, and Python-specialized configurations. The 13B variant offers a balance between efficiency and accuracy, making it particularly suitable for latency-sensitive tasks and resource-constrained environments.
The initial release of Code Llama emerged on August 24, 2023, with subsequent updates broadening the range and parameter sizes of models in the series. The architecture, training methods, and licensing remain consistent across the family.
A clean digital illustration referencing the Llama 2 series, highlighting its foundational role in the architecture of Code Llama models.