Launch a dedicated cloud GPU server running Laboratory OS to download and run CodeLlama 34B using any compatible app or framework.
Direct Download
Must be used with a compatible app, notebook, or codebase. May run slowly, or not work at all, depending on local system resources, particularly GPU(s) and available VRAM.
Open WebUI is an open-source, self-hosted web interface with a polished, ChatGPT-like user experience for interacting with LLMs. Integrates seamlessly with local Ollama installation.
The most full-featured web interface for experimenting with open source Large Language Models. Featuring a wide range of configurable settings, inference engines, and plugins.
Model Report
Meta / CodeLlama 34B
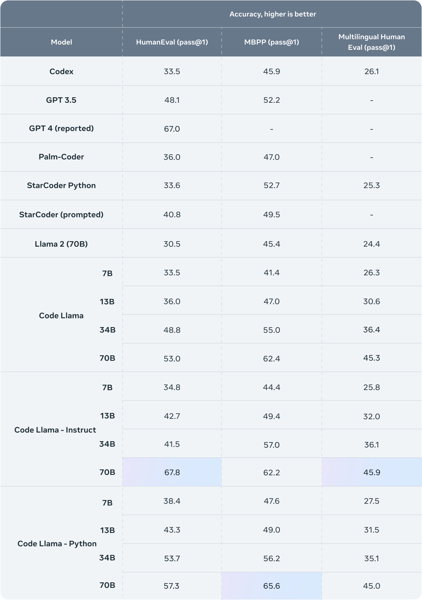
CodeLlama 34B is a large language model developed by Meta that builds upon Llama 2's architecture and is optimized for code generation, understanding, and programming tasks. The model supports multiple programming languages including Python, C++, Java, and JavaScript, with an extended context window of up to 100,000 tokens for handling large codebases. Available in three variants (Base, Python-specialized, and Instruct), it achieved 53.7% accuracy on HumanEval and 56.2% on MBPP benchmarks, demonstrating capabilities in code completion, debugging, and natural language explanations.
Explore the Future of AI
Your server, your data, under your control
Code Llama 34B is a large language model (LLM) developed by Meta, optimized for code generation, understanding, and related tasks. Released on August 24, 2023, Code Llama 34B is part of the broader Code Llama family, which leverages the underlying architecture of Llama 2 to support a range of programming-focused applications. This model is designed to interpret code, follow instructions for programming tasks, and provide context-rich code completions and explanations, addressing both professional and educational programming needs as documented in the Meta blog post and Meta publication.
Animated demonstration of Code Llama 34B identifying and correcting a bug in a Python code snippet, then explaining the correction in natural language. Prompt: '# Fix the bug in the code above and explain the fix.'
Code Llama 34B builds upon the auto-regressive transformer architecture introduced with Llama 2. It is specifically adapted for code by further training on extensive datasets of programming code and code-related natural language. This code specialization extends to longer sequence handling, enabling context windows of up to 100,000 tokens, and allows the model to engage effectively with large codebases and complex tasks. The training process utilized Meta’s Research Super Cluster and included approximately 500 billion tokens of code and code-related data as detailed in the HuggingFace model card.
The training procedure involves the same foundational data as Llama 2 but introduces differentiated weighting and fine-tuning strategies, including further pre-training on curated code corpora and reinforcement learning from human feedback to improve instruction following and safety. The Python-specialized variant received additional fine-tuning on 100 billion Python tokens for improved performance in that language, as described in the Meta blog post.
Capabilities and Variants
Code Llama 34B supports a range of programming languages, including Python, C++, Java, PHP, Typescript (JavaScript), C#, and Bash. The model generates code from natural language or code prompts, interprets code snippets, performs debugging, provides natural language explanations, and completes code based on partial inputs. It also demonstrates infilling capabilities in select variants, allowing code to be inserted seamlessly into existing code blocks, as detailed in the Meta publication.
Animated sequence illustrating Code Llama 34B providing a natural language explanation for a Python function that calculates the nth Fibonacci number. Prompt: '# Explain this code in natural language.'
There are three primary variants of Code Llama 34B to address diverse use cases:
The Base model is intended for general code synthesis, completion, and understanding.
Code Llama 34B - Python is fine-tuned for enhanced performance on Python-specific tasks.
Code Llama 34B - Instruct is aligned to follow natural language instructions and generate contextually relevant, safe, and helpful responses, as stated in the Meta blog post.
Performance is stable and accurate across long contexts, supporting both zero-shot and instruction-guided programming tasks. The model's design prioritizes developer productivity and educational accessibility.
Performance Benchmarks
On industry-standard benchmarks, Code Llama 34B's performance is assessed against established code-specific models. In controlled internal evaluations, Code Llama 34B achieved an accuracy score of 53.7% on the HumanEval benchmark, which tests functional correctness in code generation from docstrings, and obtained 56.2% on MBPP, a benchmark for code completion from English prompts, as described in the Meta blog post and Meta publication. These results are comparable to those of models such as ChatGPT.
Table comparing performance of Code Llama and several other language models across HumanEval, MBPP, and Multilingual HumanEval benchmarks. Code Llama 34B's performance is presented for these tasks.
Evaluations on additional benchmarks, such as MultiPL-E, show that Code Llama 34B and its family achieved notable results compared to other publicly available open-source models on multi-language programming tasks, as detailed in the Meta publication. Each variant's benchmarks reflect its respective training focus, with the Python-specialized and Instruct models achieving peak scores on Python and instruction-following assessments.
Applications and Use Cases
Code Llama 34B is designed as an assistive tool for software development, code comprehension, and instruction. It can generate new code from text prompts, complete partially written code, explain code functionality in natural language, and assist in debugging by identifying and correcting errors. Its extended context window facilitates navigation and manipulation of large codebases, supporting refactoring and documentation tasks, according to the Meta blog post. The model's application spans productivity toolchains for experienced developers, educational support for programming learners, and program synthesis for research.
In addition to direct code generation, Code Llama 34B serves roles in code review, automated documentation, and providing insights into code logic. The model's capabilities across multiple languages and programming tasks position it as a resource for both commercial and academic environments, as outlined in the HuggingFace model card.
Limitations and Responsible Use
As with other large language models, Code Llama 34B is subject to certain limitations. Its responses can at times be inaccurate or unsuitable for sensitive environments, necessitating thorough safety review and tailored deployment protocols for production scenarios, as noted in the HuggingFace model card. Potential risks include generation of erroneous, incomplete, or unsafe code, and developers are encouraged to conduct domain-specific validation and align with Meta’s Acceptable Use Policy.
Code Llama 34B and its variants are static models—that is, they do not learn or adapt after deployment. Their training data emphasize English and popular programming languages, with less tested support for other languages. The model, notably in its base and Python versions, is not recommended for general-purpose natural language tasks outside software contexts, according to the Meta blog post.
Red teaming has been conducted to assess the risk of generating malicious code, and while Code Llama provided safer outputs compared to certain proprietary models in testing, adherence to responsible AI guidelines remains essential, as described in the Meta blog post.
Licensing and Accessibility
Code Llama 34B is distributed under the Llama 2 community license, offering commercial and research use under community-centric terms. These include requirements for attribution, responsible deployment, adherence to the Acceptable Use Policy, and restrictions on using model outputs to improve other LLMs outside the Llama family, as outlined in the HuggingFace model card. Organizations exceeding specific user thresholds must request licensing directly from Meta.
The model and derivatives are available as open foundation resources, accompanied by documentation and model cards supporting transparency and reproducibility, as stated in the Meta research paper. Reporting channels exist for responsible disclosure of issues, misuse, and security concerns via Meta’s recommended pathways.