Launch a dedicated cloud GPU server running Laboratory OS to download and run Qwen3 1.7B using any compatible app or framework.
Direct Download
Must be used with a compatible app, notebook, or codebase. May run slowly, or not work at all, depending on local system resources, particularly GPU(s) and available VRAM.
Open WebUI is an open-source, self-hosted web interface with a polished, ChatGPT-like user experience for interacting with LLMs. Integrates seamlessly with local Ollama installation.
The most full-featured web interface for experimenting with open source Large Language Models. Featuring a wide range of configurable settings, inference engines, and plugins.
Model Report
Alibaba Cloud / Qwen3 1.7B
Qwen3-1.7B is a dense transformer language model with 1.7 billion parameters developed by Alibaba Cloud's Qwen Team. The model features dual-mode reasoning capabilities, operating in either "thinking" mode for step-by-step reasoning with intermediate computations or "non-thinking" mode for rapid direct responses. It supports 119 languages and utilizes a 32,768-token context window with grouped query attention architecture.
Explore the Future of AI
Your server, your data, under your control
Qwen3-1.7B is a dense large language model comprising 1.7 billion parameters. Developed by the Qwen Team at Alibaba Cloud, it is part of the broader Qwen3 series introduced on April 29, 2025. Qwen3-1.7B aims to balance efficiency, multilinguality, and advanced reasoning across a diverse set of language and agentic tasks. The model is built upon architectural innovations and a unique "dual-mode reasoning" paradigm that supports both rapid response and step-by-step computational reasoning, extending the model's capabilities for real-world applications in numerous languages and domains.
Technical Capabilities and Features
A distinguishing technological feature of Qwen3-1.7B is its ability to operate in two distinct modes: "thinking" and "non-thinking." In thinking mode, the model can reason step by step, generating intermediate computations before arriving at a final answer. This is particularly beneficial for tasks such as logical reasoning, mathematics, and programming, where transparency of process and carefully reasoned outputs are desired. The intermediate thought process is encapsulated within distinctive markup (i.e., <think>...</think> blocks) in the output.
In contrast, the non-thinking mode enables rapid, direct responses without intermediary reasoning steps, maximizing efficiency for routine conversational or fact-based queries. Users can dynamically switch between these modes—either by setting parameters in the tokenizer or by including special directives (such as /think or /no_think) within prompts—optimizing the tradeoff between latency and computational budget.
Visualization of Qwen3's dual-mode reasoning capabilities, showing how the model processes information differently in thinking vs. non-thinking modes.
Qwen3 models are designed for high multilingual proficiency, supporting 119 languages and dialects. This extensive coverage enhances worldwide accessibility and cross-linguistic understanding, with measured improvements across diverse language benchmarks for languages including Spanish, Arabic, Japanese, Thai, and more.
The model is further optimized for agentic tasks, excelling in the orchestration of code and external tool calling. This design, in conjunction with the Qwen-Agent framework, supports robust integration with external APIs and smart workflows, expanding its utility for automation and multi-tool scenarios.
Human preference alignment is also a value proposition of Qwen3-1.7B, as evidenced by its strong performance in machine-human evaluation for creative writing, instruction following, and multi-turn dialog.
Demonstration of Qwen3's improved agentic capabilities and interactive reasoning in an environment. [Source]
Architecture and Training Methodology
Qwen3-1.7B employs a dense causal transformer architecture, featuring 1.7 billion parameters, of which 1.4 billion are non-embedding. It utilizes 28 transformer layers with grouped query attention (16 query heads and 8 key/value heads), and a 32,768-token context window to enable handling of long documents and conversations. The architecture supports advanced mechanisms such as SwiGLU activations, Rotary Positional Embeddings (RoPE), and RMSNorm with pre-normalization for efficient and stable training.
Major improvements over prior Qwen2.5 and Qwen2 models include the removal of QKV-bias and the introduction of QK-Norm to further stabilize attention layers, especially in large-context settings. Qwen3 models leverage a byte-level byte-pair encoding tokenizer with a 151,669-token vocabulary, facilitating robust multilingual performance.
Long-context abilities are enhanced via mechanisms such as YARN and Dual Chunk Attention, with extended positional encoding ranges (up to a million) using the ABF technique to support efficient inference over lengthy sequences.
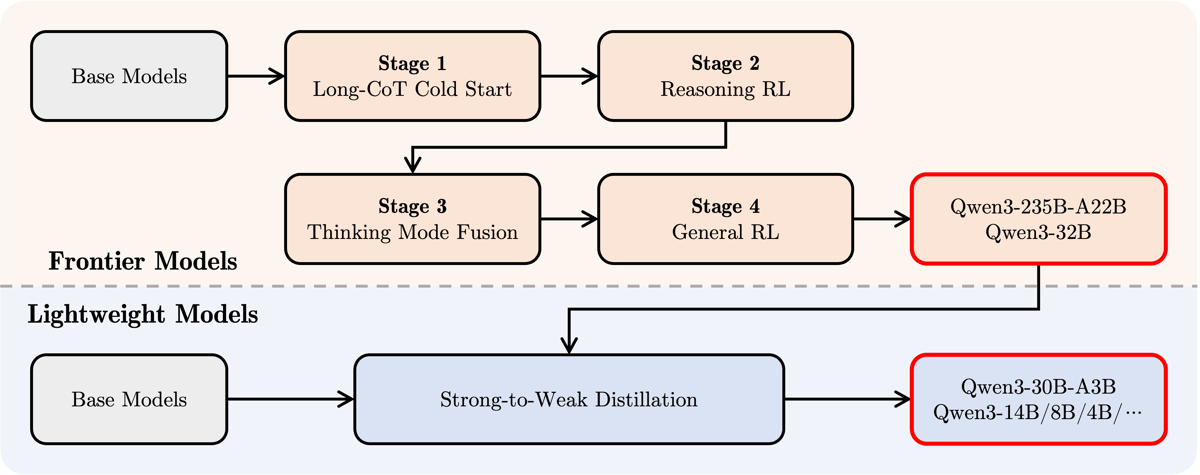
The training dataset for Qwen3-1.7B spans approximately 36 trillion tokens, with content sourced from diverse domains and supporting 119 languages. Pre-training was accompanied by staged post-training involving reinforcement learning and chain-of-thought (CoT) fine-tuning, as well as specialized strong-to-weak distillation methods to transfer advanced reasoning skills from frontier models (such as Qwen3-235b-a22b) down to lightweight versions like Qwen3-1.7B.
Diagram illustrating the two main Qwen3 post-training pipelines: a multistage process for frontier models and a strong-to-weak distillation path for lightweight variants.
Benchmarking results demonstrate that Qwen3-1.7B consistently delivers competitive results, often outperforming larger models from previous generations on a variety of tasks. In pre-training benchmarks, Qwen3-1.7B-Base achieves:
MMLU: 62.63
GSM8K (math): 75.44
EvalPlus (coding): 52.70
MMMLU (multilingual): 63.27
Post-training, the model's performance in thinking mode surpasses that of DeepSeek-R1-Distill-Qwen-1.5B and similar competitive baselines on STEM and reasoning-heavy tasks, such as the MATH-500 and AIME'24 exams. In non-thinking mode, it exceeds peer models—including Gemma-3-1b-it and Qwen2.5-3B—across general, alignment, and multilingual benchmarks.
Its long-context handling is notable as well; Qwen3-1.7B achieves RULER average scores of 85.2 in non-thinking mode, reflecting strength in retaining and reasoning over extended sequences.
Model Family and Comparative Context
Qwen3-1.7B is one among several dense models in the Qwen3 suite, which also includes Qwen3-0.6B, Qwen3-4b, Qwen3-8b, Qwen3-14b, and the flagship Qwen3-32b. The family further comprises Mixture-of-Experts (MoE) variants, such as Qwen3-30b-a3b and Qwen3-235b-a22b, which serve as teacher models for distillation.
Models like Qwen3-4b and Qwen3-8b have demonstrated the ability to surpass Qwen2.5-7B and Qwen2.5-14B across various tasks despite having fewer parameters. The distillation pipeline allows Qwen3-1.7B and other lightweight variants to inherit the multi-turn reasoning and mode-switching abilities of much larger models while maintaining a low parameter count.
Limitations
While Qwen3-1.7B exhibits strong all-around performance, certain limitations have been observed. In information retrieval tasks, thinking mode can marginally decrease performance as the generation of intermediate steps may distract from answer precision. Greedy decoding, especially in thinking mode, may result in suboptimal outputs or repetitive text and is therefore discouraged. Tweaking the presence_penalty can reduce repetitiveness, but higher penalties may slightly affect model performance or lead to language mixing. General reinforcement learning fine-tuning, while broadening capability, can also lead to minor reductions in specialty task performance relative to models fine-tuned solely on those domains.
Applications
Qwen3-1.7B's versatility enables use in a variety of real-world scenarios, including:
Multilingual conversational agents
Complex problem solving with explicit stepwise reasoning
Coding assistance and tool automation via agentic capabilities
Instruction following and creative writing aligned with human preferences
Local deployment on lightweight devices for edge applications
Licensing
All open-weight variants of Qwen3, including Qwen3-1.7B, are distributed under the Apache 2.0 license, permitting broad research and commercial use, subject to the terms and conditions specified therein.