Launch a dedicated cloud GPU server running Laboratory OS to download and run Gemma 3n E2B using any compatible app or framework.
Direct Download
Must be used with a compatible app, notebook, or codebase. May run slowly, or not work at all, depending on local system resources, particularly GPU(s) and available VRAM.
Open WebUI is an open-source, self-hosted web interface with a polished, ChatGPT-like user experience for interacting with LLMs. Integrates seamlessly with local Ollama installation.
The most full-featured web interface for experimenting with open source Large Language Models. Featuring a wide range of configurable settings, inference engines, and plugins.
Model Report
Google / Gemma 3n E2B
Gemma 3n E2B is a multimodal generative AI model developed by Google DeepMind that supports text, image, audio, and video inputs. Built on the MatFormer architecture with 6 billion raw parameters but 2 billion effective parameters, it employs Per-Layer Embeddings and KV Cache Sharing for efficient operation on resource-constrained devices. The model was trained on over 11 trillion tokens across 140+ languages with a June 2024 knowledge cutoff.
Explore the Future of AI
Your server, your data, under your control
Gemma 3n E2B is an open, multimodal generative AI model developed by Google DeepMind, engineered for efficient operation on resource-constrained devices while supporting a broad range of input modalities, including text, images, audio, and video. Leveraging innovations in transformer architecture and parameter optimization, Gemma 3n E2B delivers capabilities in diverse language, vision, and audio processing tasks with minimal memory requirements. The model is a member of the Gemma 3n family and builds upon research initiatives underpinning the Gemini model series, with optimizations oriented toward practical deployment on edge and mobile devices.
Gemma 3n branding, representing the family of models designed for efficient, multimodal AI inference.
Gemma 3n E2B is based on the MatFormer, or Matryoshka Transformer, architecture—a nested transformer paradigm that enables large models to encapsulate smaller, fully functional sub-models. This design supports "elastic inference," allowing the same neural backbone to operate flexibly across different parameter budgets and application constraints. In Gemma 3n, the E4B model (8 billion raw parameters, 4 billion effective) contains the E2B sub-model (6 billion raw, 2 billion effective), permitting model extraction, rapid inference, and tailored deployments via a "Mix-n-Match" method of variable feed-forward network dimensions or skipped layers, as detailed in the MatFormer paper.
Diagram of the MatFormer architecture in Gemma 3n, illustrating how larger models contain fully functional sub-models with flexible depth and feed-forward configurations.
To further reduce memory demands, Gemma 3n E2B implements Per-Layer Embeddings (PLE), enabling much of the embedding computation to be offloaded to the CPU while reserving only core transformer weights in high-speed memory. This approach ensures that, although the model has a raw parameter count of 6 billion, its memory footprint matches that of traditional 2-billion-parameter models.
A comparative diagram showing how Per-Layer Embeddings drastically reduce parameters loaded into accelerator memory for Gemma 3n E2B.
Another innovation is Key-Value (KV) Cache Sharing, which accelerates the prefill phase for streaming applications. By sharing the keys and values of the middle layers across higher transformer layers, the time-to-first-token for long-sequence inputs such as audio and video streams is significantly reduced.
Input Modalities and Model Components
Gemma 3n E2B is a fundamentally multimodal model. The text encoder and decoder are joined by efficient vision and audio components. The vision encoder is built on MobileNet-V5-300M, an advanced and lightweight architecture that utilizes deep pyramid modules and a multi-scale fusion adapter for visual language modeling. This provides visual processing capability for edge devices, supporting a range of input resolutions and operating efficiently on mobile devices.
For audio, Gemma 3n E2B incorporates an encoder derived from the Universal Speech Model (USM), generating a token approximately every 160ms. This specialized architecture enables robust automatic speech recognition and translation, with demonstrated effectiveness for English-Spanish, French, Italian, and Portuguese speech translation tasks.
The input context size supports sequences up to 32,000 tokens, with limitations on individual image and audio resolutions to optimize for on-device efficiency. Images are normalized to 256×256, 512×512, or 768×768 pixels and encoded as 256 tokens each.
Training Data and Preprocessing
Gemma 3n E2B was trained on a dataset exceeding 11 trillion tokens, accumulated from diverse sources and multilingual web documents spanning over 140 languages. The corpus also integrates substantial quantities of code, mathematical text, images, and audio material to foster broad reasoning and comprehension abilities. The knowledge cutoff for the model is June 2024.
In order to maintain safety and compliance, a robust data-cleaning pipeline was applied during preprocessing. These methods included advanced filtering for harmful content, automated removal of personal and sensitive information, and additional quality checks in accordance with Google's responsible AI policies.
Performance and Benchmarks
Gemma 3n E2B has undergone comprehensive evaluation across established benchmarks in reasoning, factuality, multilingual understanding, and code generation. On benchmarks such as HellaSwag, BoolQ, PIQA, TriviaQA, and MMLU, the model performs well for its parameter count. For example, on the HellaSwag benchmark, Gemma 3n E2B achieves 72.2% accuracy (10-shot); on MMLU, it attains 60.1% accuracy (0-shot) when instruction-tuned.
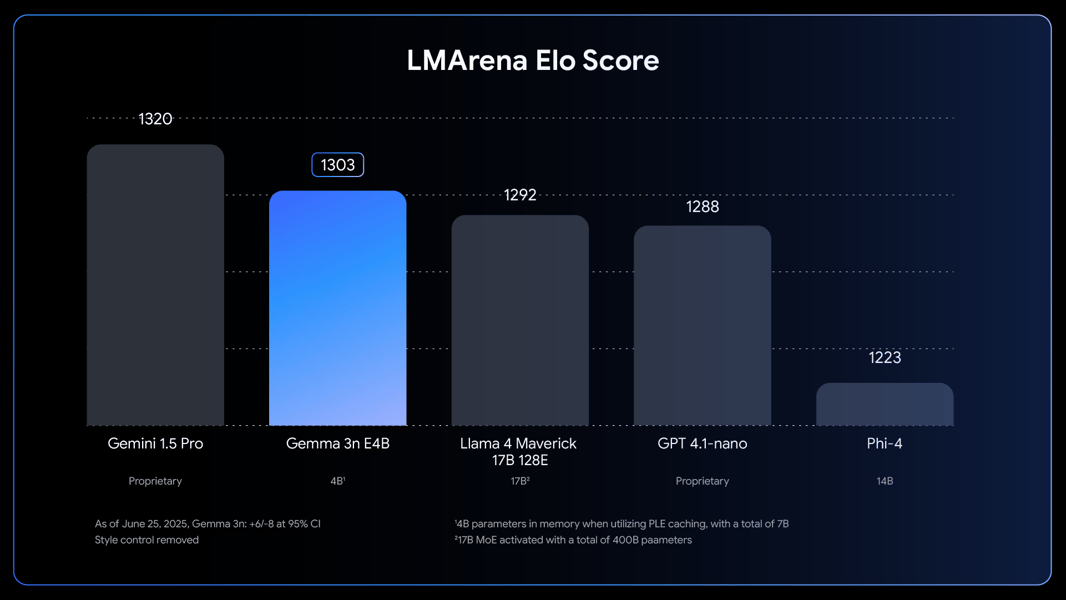
The larger E4B model, which contains the E2B sub-model, reached an LMArena Elo score above 1300.
LMArena Elo scores indicate benchmarking of Gemma 3n E4B among models of varying sizes.
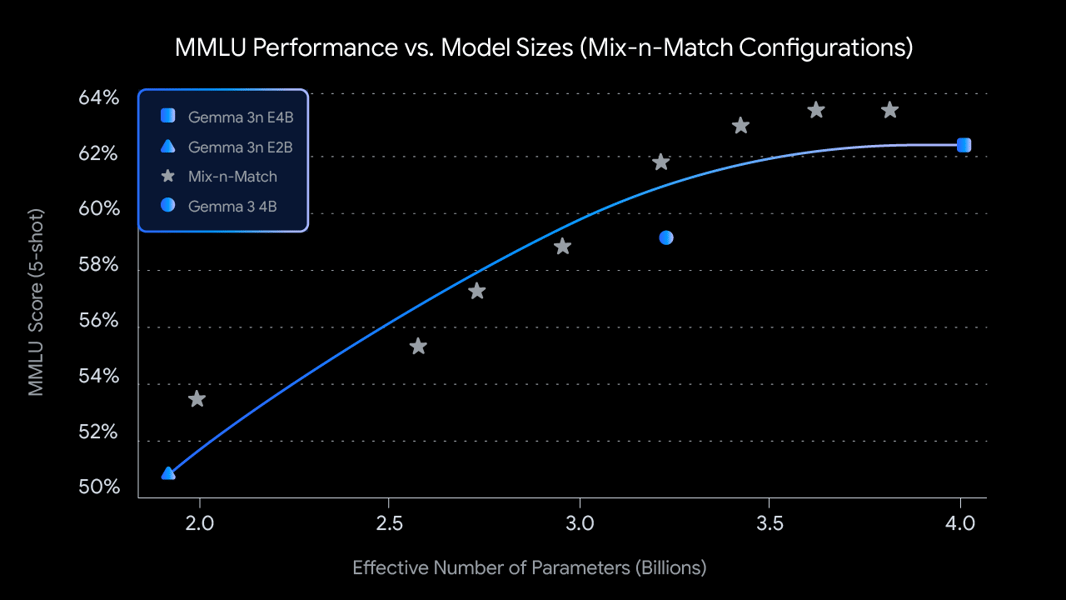
The flexible MatFormer architecture also enables fine-tuned trade-offs between model size and performance using the Mix-n-Match configuration technique, as demonstrated by rising MMLU scores with increased parameter budgets.
Line graph showing the relationship between MMLU performance and parameter count for Gemma 3n's Mix-n-Match configurations.
Performance across multilingual, STEM, and code generation tasks has also been validated, with results on complex reasoning and generative tasks.
Use Cases, Release Timeline, and Model Family
Gemma 3n E2B's design lends itself to a variety of content generation, data processing, and communication applications—ranging from chatbots and conversational AI to real-time speech translation, visual information extraction, and educational aides. The combination of low-memory operation and multi-modality positions the model for edge deployments and on-device inference in mobile-first architectures.
Development of Gemma 3n E2B aligns with the Gemini project, and the model was officially released on June 26, 2025, following a period of developer preview. Its knowledge cutoff is June 2024.
Within the broader Gemma 3n family, other variants such as E4B provide greater capacity and performance at modestly higher memory costs, while leveraging the same architectural optimizations. Most notably, the MatFormer design allows extraction of smaller sub-models, such as E2B, from larger models, affording flexibility in deployment scenarios.
Limitations and Responsible Use
While Gemma 3n E2B demonstrates robust performance across numerous benchmarks and modalities, the model inherits several limitations common to large language models. These include potential biases or coverage gaps stemming from the training data, challenges in responding to highly ambiguous or nuanced queries, and difficulties with certain forms of common sense or highly specialized factual knowledge. Safety evaluations have been predominately conducted in English, and, at launch, audio sequence length is capped at 30 seconds, though longer durations may be supported with further training.
Users must agree to Google's usage license and prohibited use policy before accessing Gemma 3n models, in accordance with responsible AI guidelines.