Launch a dedicated cloud GPU server running Laboratory OS to download and run Lumina Image 2.0 using any compatible app or framework.
Direct Download
Must be used with a compatible app, notebook, or codebase. May run slowly, or not work at all, depending on local system resources, particularly GPU(s) and available VRAM.
Forge is a platform built on top of Stable Diffusion WebUI to make development easier, optimize resource management, speed up inference, and study experimental features.
Model Report
Alpha-VLLM / Lumina Image 2.0
Lumina Image 2.0 is a 2 billion parameter text-to-image generative model developed by Alpha-VLLM that utilizes a flow-based diffusion transformer architecture. The model generates high-fidelity images up to 1024x1024 pixels from textual descriptions, employs a Gemma-2-2B text encoder and FLUX-VAE-16CH variational autoencoder, and is released under the Apache-2.0 license with support for multiple inference solvers and fine-tuning capabilities.
Explore the Future of AI
Your server, your data, under your control
Lumina-Image 2.0 is a large-scale text-to-image generative model designed to create high-fidelity images from textual descriptions. Developed as part of a unified and efficient generative framework, Lumina-Image 2.0 employs a 2 billion parameter flow-based diffusion transformer architecture, pairing model engineering with efficient inference strategies. It serves as the central model within the Lumina family, providing core image synthesis capabilities, and supporting further extension through accessory frameworks. Lumina-Image 2.0 is released under the Apache-2.0 license, promoting research accessibility and development extensibility.
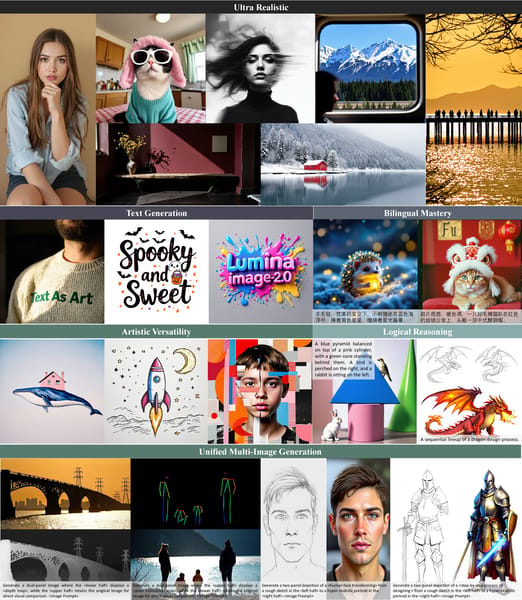
Composite grid demonstrating Lumina-Image 2.0 outputs across various categories such as photorealism, text-rendering, multilingual generation, artistic style, logical reasoning, and unified multi-image tasks.
At its core, Lumina-Image 2.0 utilizes a flow-based diffusion transformer architecture, integrating the interpretability of flow models with the generative strength of diffusion processes. The model’s text embedding pipeline employs the Gemma-2-2B text encoder, allowing nuanced mapping of text prompts to visual features. Image data is processed and reconstructed through a FLUX-VAE-16CH variational autoencoder, supporting high-resolution outputs up to 1024x1024 pixels.
Key architectural choices focus on efficient attention computation, incorporating the flash-attn library to accelerate training and inference while minimizing computational overhead. The environment for fine-tuning and model operation is standardized on PyTorch 2.1.0 and CUDA 12.1, ensuring compatibility with contemporary deep learning infrastructure. Multiple inference solvers are supported, including Midpoint Solver, Euler Solver, and DPM Solver, giving users flexibility in balancing speed and image fidelity.
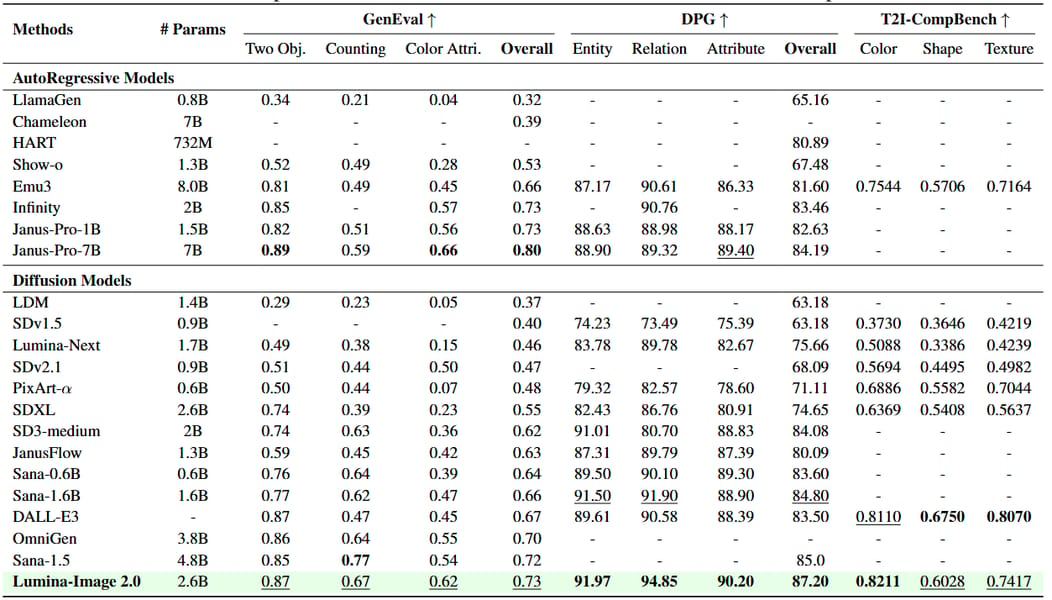
Quantitative comparison table illustrating Lumina-Image 2.0 performance across standard benchmarks relative to contemporary autoregressive and diffusion models.
While detailed pre-training dataset information is not publicly disclosed, the fine-tuning process relies on paired image-text data in a structured JSON-like format, with each entry specifying an image_path and a corresponding prompt. This approach allows further adaptation for domain-specific applications, including style adaptation, subject fidelity, and nuanced prompt alignment. Alternative fine-tuning workflows are enabled through the broader Lumina-Accessory framework, enhancing the core model’s capabilities in image editing, identity preservation, and task-specific adaptation.
The learning pipeline emphasizes modularity for research and extension. Datasets for fine-tuning are specified via configuration files, and scripts are provided to streamline training with commonly-used deep learning tools. Stochastic training strategies and efficient memory management are supported by the integration of flash attention and diffusion solvers.
Features and Applications
Lumina-Image 2.0 is optimized for a wide spectrum of text-to-image tasks. The primary capability is image generation directly from text descriptions, with parameterizable controls for image resolution, guidance scale, and inference steps. The model supports advanced editing and controllable generation scenarios through the Lumina-Accessory system, enabling targeted modifications while maintaining image coherence or identity.
Applications include generic text-to-image synthesis, artistic style generation, multilingual image creation, logical scene construction, and advanced prompt following. Further, experiments with video generation via the related "Lumina-Video 1.0" project suggest an extensible design that underpins multimodal generative research.
In benchmarking contexts, Lumina-Image 2.0 has been evaluated across standard generative image tasks such as GenEval, DPG, and T2I-CompBench, demonstrating competitive performance relative to other diffusion and autoregressive models, as documented in its technical report and metrics table.
Model Releases, Timeline, and Ecosystem
The initial release of Lumina-Image 2.0, including model checkpoints and code, was made available on January 25, 2025. Subsequent milestones include the publication of the latest model weights on Hugging Face on January 31, 2025, integration with ComfyUI in early February, and availability within the Diffusers library as of February 12, 2025. LoRA fine-tuning scripts and further documentation updates followed in February, supporting community-driven customization and improvement. The release of the full technical report on March 28, 2025, provided additional depth on model design and benchmarking methodology.
In April 2025, the Lumina-Accessory extension was released, thus broadening the model’s utility for controllable editing, multi-task adaptation, and identity-preserving transformations. This ecosystem encourages modular development and supports a variety of downstream applications and integrations.
Related Models and Extensions
Within the broader Lumina family, Lumina-Image 2.0 serves as the foundational image synthesis engine. Its capabilities are extended through Lumina-Accessory, which provides frameworks for fine-tuning, image editing, and more dynamic generation control, as well as through exploratory initiatives such as Lumina-Video 1.0 that push towards text-to-video generation using related architectural foundations. These related projects illustrate a commitment to unified, multimodal generative research.
Licensing and Availability
Lumina-Image 2.0 is distributed under the Apache-2.0 open-source license, ensuring broad access for academic, research, and development communities. Pretrained model weights, codebase, and fine-tuning tools are accessible via the official GitHub repository, with additional weights and packaged versions on Hugging Face and ComfyUI. The project maintains ongoing updates and documentation to facilitate reproducibility and experimentation.