Note: CogVideoX 1.5 5B weights are released under a CogVideoX License, and cannot be utilized for commercial purposes. Please read the license to verify if your use case is permitted.
Laboratory OS
Launch a dedicated cloud GPU server running Laboratory OS to download and run CogVideoX 1.5 5B using any compatible app or framework.
Direct Download
Must be used with a compatible app, notebook, or codebase. May run slowly, or not work at all, depending on local system resources, particularly GPU(s) and available VRAM.
Generate images and videos using a powerful low-level workflow graph builder - the fastest, most flexible, and most advanced visual generation UI.
Model Report
THUDM / CogVideoX 1.5 5B
CogVideoX 1.5 5B is an open-source video generation model developed by THUDM that creates high-resolution videos up to 1360x768 resolution from text prompts and images. The model employs a 3D causal variational autoencoder with 8x8x4 compression and an expert transformer architecture featuring adaptive LayerNorm for multimodal alignment. It supports both text-to-video and image-to-video synthesis with durations of 5-10 seconds at 16 fps, released under Apache 2.0 license.
Explore the Future of AI
Your server, your data, under your control
CogVideoX 1.5 5B is an open-source generative AI model for video synthesis, developed by THUDM and released in November 2024. Building on the CogVideoX series, this model implements text- and image-to-video synthesis, enabling the generation of high-resolution, temporally coherent videos from natural language prompts and visual inputs. CogVideoX 1.5 5B incorporates techniques in model architecture, compression, and multimodal alignment, which affect the quality and controllability of generated video content. The design and empirical evaluation of the model are documented in the official research paper.
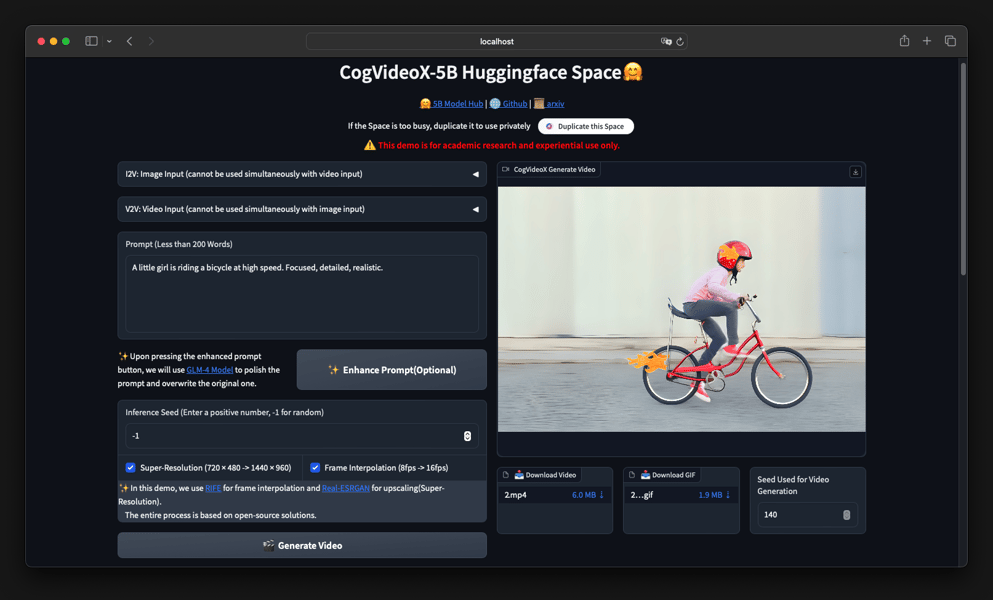
The CogVideoX-5B web demo interface, showing end-to-end video generation from textual and visual prompts, and integration with super-resolution and interpolation tools.
CogVideoX 1.5 5B enables the generation of video clips up to 1360 x 768 resolution and durations of 5 or 10 seconds at 16 frames per second, supporting both text-to-video and image-to-video paradigms. The model accepts detailed English prompts, leveraging prompt optimization through large language models to affect generation results.
The model utilizes a causal 3D variational autoencoder (VAE), which compresses spatiotemporal video data into a latent representation. The encoder, decoder, and regularizer in this VAE achieve an 8x8x4 pixel-to-latent compression ratio, affecting computational efficiency and maintaining temporal coherence.
The underlying transformer employs an expert transformer architecture with adaptive LayerNorm, which processes and aligns multimodal content through separate expert pathways for text and vision. This design facilitates integration of textual and visual information, affecting semantic correspondence between input and generated video.
For temporal consistency and the depiction of large-scale object motion, CogVideoX 1.5 5B incorporates a 3D full-attention mechanism, operating jointly across space and time. This is complemented by a multi-resolution frame pack technique, enabling batch training over various video lengths and resolutions, and explicit uniform sampling to stabilize diffusion model optimization.
Example output video: This sample demonstrates CogVideoX-5B generating a realistic video based on a natural language prompt. [Source]
Model Architecture and Training Regimen
The architecture of CogVideoX 1.5 5B is based on a diffusion transformer backbone. The 3D causal VAE serves as the initial compression block, encoding raw video into a structured latent space. This latent sequence is then unfolded and processed by the diffusion transformer, which integrates text and visual features through concatenated embeddings, expert adaptive normalization, and 3D rotary positional encodings.
Progressive training is used to optimize the model: it first learns from lower-resolution (256px) video data to capture semantic and low-frequency patterns, and then is fine-tuned using higher resolutions (up to 1360 x 768), with an additional focus on high-frequency visual details during a final fine-tuning stage. The training dataset consists of approximately 35 million curated video clips, each accompanied by captions generated and refined using a dense captioning pipeline. This involves models such as Panda70M for brief captioning, CogVLM for dense frame descriptions, and summary aggregation via LLMs such as GPT-4, with further acceleration by CogVLM2-Caption.
Film-strip collage of CogVideo model outputs, showing video frame sequences generated from diverse text prompts.
Another video sample generated by CogVideoX-5B, illustrating dynamic scene generation from natural language. [Source]
Empirical Performance
CogVideoX 1.5 5B's performance was assessed on a range of automated and human evaluation metrics. In comparative tests, the model produced results on Vbench criteria including human action, scene representation, dynamism, object multiplicity, and stylistic fidelity. Human raters have further assessed the quality of generated clips on sensory detail, instruction following, physics simulation, and coverage, with CogVideoX models' aggregate scores being compared to both open-source and closed-source baselines.
The integrated 3D VAE has been shown to yield high peak signal-to-noise ratio (PSNR) and low flicker scores, supporting temporal coherence across generated frames. Inference can be performed in various precision modes (e.g., BF16, FP16, INT8), with quantization offering memory savings at the expense of speed.
Sequential frames from a CogVideo-generated video, illustrating temporal consistency and plausible motion synthesis.
CogVideoX 1.5 5B supports multiple video generation tasks, including text-to-video, image-to-video (using background images with prompts), and video continuation. Through integration with CogVLM2-Caption, it also enables video-to-video generation by extracting new captions from source videos for guided resynthesis.
Within the CogVideoX model family, earlier variants such as CogVideoX-2B and CogVideoX-5B offer similar core capabilities but differ in supported resolutions, framerates, and resource requirements. CogVideoX 1.5 5B I2V extends image-to-video capabilities with flexible resolution settings.
Limitations and Licensing
Despite architectural characteristics, limitations persist. The model currently supports only English language input and requires external translation for other languages. While quantized inference enables operation on GPUs with reduced memory, it results in slower generation speeds. Enabling memory-optimization tools can also impact throughput. Additionally, improvements in visual fidelity from fine-tuning may marginally reduce semantic coverage. Long-term temporal coherence for videos with intricate narratives remains an active area of research.
CogVideoX 1.5 5B is published under the Apache 2.0 License, while certain components and earlier versions may have separate licensing terms (CogVideoX LICENSE). The codebase and weights are openly available for research and non-commercial use.