Note: CogVideoX 1.5 5B I2V weights are released under a CogVideoX License, and cannot be utilized for commercial purposes. Please read the license to verify if your use case is permitted.
Laboratory OS
Launch a dedicated cloud GPU server running Laboratory OS to download and run CogVideoX 1.5 5B I2V using any compatible app or framework.
Direct Download
Must be used with a compatible app, notebook, or codebase. May run slowly, or not work at all, depending on local system resources, particularly GPU(s) and available VRAM.
Generate images and videos using a powerful low-level workflow graph builder - the fastest, most flexible, and most advanced visual generation UI.
Model Report
THUDM / CogVideoX 1.5 5B I2V
CogVideoX 1.5 5B I2V is an image-to-video generation model developed by THUDM using a diffusion transformer architecture with 3D causal variational autoencoder. The model generates temporally coherent videos from input images and text prompts, supporting resolutions up to 1360 pixels and video lengths of 5-10 seconds at 16 fps, trained on 35 million curated video clips.
Explore the Future of AI
Your server, your data, under your control
CogVideoX 1.5 5B I2V is a generative image-to-video artificial intelligence model developed by THUDM and Zhipu AI, officially released on November 8, 2024. As the latest entry in the CogVideoX model series, CogVideoX 1.5 5B I2V incorporates updated neural architectures and training methodologies. The model is designed to generate temporally coherent videos conditioned on both images and text prompts, supporting flexibility and performance.
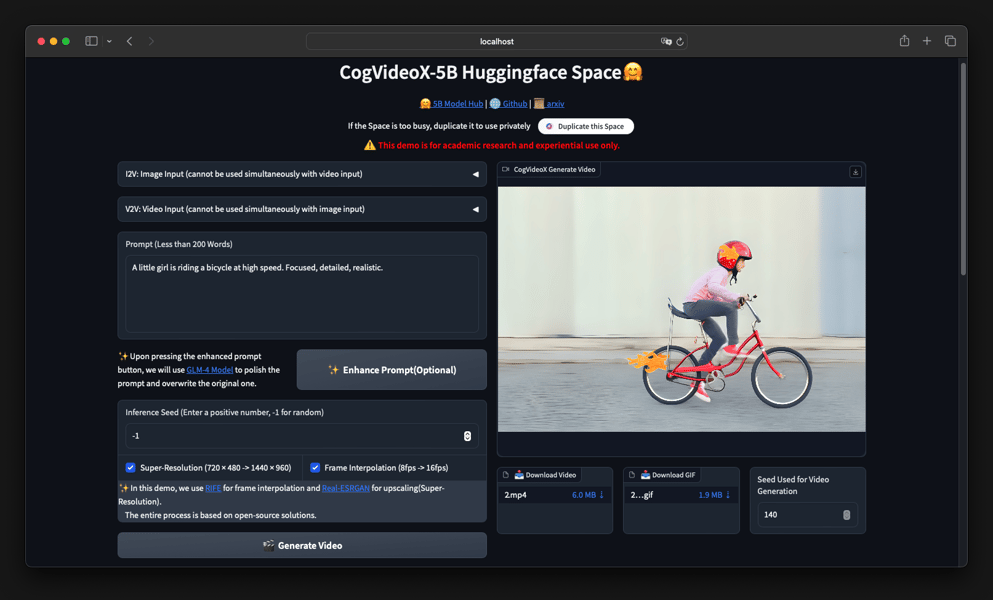
A web demo interface for CogVideoX-5B, showing configuration options for image-to-video and video generation, with a generated sample video depicting a girl riding a bicycle. [Prompt: 'A little girl is riding a bicycle at high speed. Focused, detailed, realistic.']
CogVideoX 1.5 5B I2V is built upon a diffusion transformer backbone, integrating both a three-dimensional (3D) causal variational autoencoder (VAE) and an expert transformer module. The 3D causal VAE compresses videos along spatial and temporal axes, significantly enhancing compression rates and temporal consistency while reducing computational overhead, as documented in the CogVideoX technical report.
Within the model, the expert transformer introduces expert adaptive LayerNorm to better align text and visual modalities. By processing each modality independently before fusion, the architecture ensures robust cross-modal alignment and minimizes the additional parameter count. CogVideoX implements a 3D full attention mechanism, simultaneously modeling spatial and temporal dependencies and handling large object or camera motions with improved stability.
The application of patchification—converting video latents into sequences of spatiotemporal patches—further enhances efficiency. These patch sequences are embedded using 3D rotary positional embeddings (3D-RoPE), a method extending position encoding to cover video data across spatial and temporal dimensions. The model also uses progressive training, first learning semantic concepts at lower resolutions and gradually increasing to higher resolutions to capture fine-grained details.
Training Data and Methodology
The model was trained on a curated dataset comprising approximately 35 million high-quality video clips with descriptive captions, each averaging about six seconds in length. Video data were rigorously filtered using pipelines that score aesthetic quality and dynamic motion, including optical flow and custom negative labels. The filtering process was supported by labels such as "Lack of Motion Connectivity" or "Low Quality," with multiple neural classifiers and aesthetic scoring systems used to discard undesirable examples, as described in the official CogVideoX documentation.
Textual captions for videos were generated through a multi-stage pipeline involving initial short captions (via the Panda70M model), dense image recaptioning (using CogVLM), and summarization with large language models such as GPT-4. A further fine-tuned video captioning model (CogVLM2-Caption) accelerated large-scale dense caption creation.
During training, the model also leveraged billions of high-quality images sourced from datasets such as LAION-5B and COYO-700M, selected by objective aesthetic filters.
Key training strategies included mixed-duration and multi-resolution batches to improve generalization, explicit uniform timestep sampling for stability, v-prediction and zero SNR schedules in the diffusion process, and a final high-quality (HQ) fine-tuning stage to enhance visual fidelity and reduce unwanted artifacts.
Technical Capabilities and Features
CogVideoX 1.5 5B I2V supports a flexible range of video generation tasks. The core functionality is image-to-video generation, in which an input image and a descriptive prompt guide the creation of a video. The model also retains capabilities for text-to-video synthesis and video continuation.
The model supports flexibility in output resolution and video length. It can generate videos at any resolution where the shorter side is at least 768 pixels, with the maximum dimension up to 1360 pixels, subject to divisibility constraints. Video lengths of 5 or 10 seconds are supported, typically generated at 16 frames per second.
Prompt optimization was a focal point during training, and users are advised to use large language models—such as GLM-4 or GPT-4—to craft detailed prompts for best results, as outlined in the CogVideoX user guide.
Model robustness is reinforced by the addition of noise to the image condition during training, allowing for varied input styles in image-to-video synthesis. Architectural innovations, such as 3D hybrid attention, contribute to enhanced temporal consistency even during scenes with dynamic or large-scale motion.
Performance, Benchmarks, and Evaluation
Extensive benchmarking demonstrates CogVideoX 1.5 5B I2V's performance across quantitative metrics and human evaluations. In automated testing, comparisons showed specific metrics where it achieved higher scores than other models, such as human action recognition, scene depiction, dynamic degree, multiple object support, and dynamic quality, with scores closely matching human judgment (CogVideoX technical paper).
In a 256x256, 17-frame reconstruction test, the 3D VAE achieved a Peak Signal-to-Noise Ratio (PSNR) of 29.1 and minimized flickering artifacts, as measured by a score of 85.5. Human evaluations showed CogVideoX achieved higher scores compared to other models on sensory quality, instruction following, physics simulation, and cover quality. Scalability tests confirmed that even smaller variants (e.g., CogVideoX-2B) function comparably under certain conditions, and further gains are anticipated with increased model size and data.
A sample video output from CogVideoX-5B, illustrating text-to-video generation capability. [Source]
A collage showing diverse text prompts and video frame sequences generated by CogVideoX, including prompts such as 'A man is skiing.' and 'A lion is drinking water.'.
CogVideoX 1.5 5B I2V's primary application is image-to-video generation, enabling the synthesis of temporally consistent video sequences from a static image and a text prompt. The model additionally supports text-to-video workflows and can be linked with captioning models to facilitate video-to-video transformation by converting existing footage into captions and then generating new videos based on those descriptions.
A CogVideo sample output, demonstrating high-frame-rate video synthesis from a text prompt. [Source]
Model fine-tuning for domain-specific scenarios, such as interior design, is also supported, as described in several public model repositories.
Despite these strengths, the model has notable limitations. Generating longer videos or high resolutions increases computational demand, both in terms of memory and time requirements. Quantized inference modes allow reduced memory usage but can slow down generation. Fine-tuning for higher visual quality can slightly degrade semantic fidelity. Other known constraints include an input prompt length cap of 224 tokens and exclusive support for English prompts.
Model Family and Release Timeline
CogVideoX 1.5 5B I2V extends the CogVideoX family of multimodal video-generation models. Predecessors include the original CogVideo (ICLR 2023 paper), which established large-scale, open-source text-to-video generation; CogVideoX-2B; and CogVideoX-5B, each with distinct capacity, resolution, and memory usage characteristics.
The I2V specialization was made available on September 19, 2024, while the 1.5 5B upgrade—encoding advances in model size, resolution, and sampling techniques—was launched on November 8, 2024. Future features, such as DDIM inverse support and ecosystem-level developments (for example, the CogKit framework), are scheduled for release in 2025.
Licensing
CogVideoX 1.5 5B I2V is distributed under the CogVideoX LICENSE, which governs usage of the model's Transformer components, including both image-to-video and text-to-video systems. Associated code in the main repositories is made available under the Apache 2.0 License.