Note: CogVideoX 5B weights are released under a CogVideoX License, and cannot be utilized for commercial purposes. Please read the license to verify if your use case is permitted.
Laboratory OS
Launch a dedicated cloud GPU server running Laboratory OS to download and run CogVideoX 5B using any compatible app or framework.
Direct Download
Must be used with a compatible app, notebook, or codebase. May run slowly, or not work at all, depending on local system resources, particularly GPU(s) and available VRAM.
Generate images and videos using a powerful low-level workflow graph builder - the fastest, most flexible, and most advanced visual generation UI.
Model Report
THUDM / CogVideoX 5B
CogVideoX-5B is a diffusion transformer model developed by THUDM for text-to-video and image-to-video synthesis, generating 10-second videos at 768x1360 resolution and 8 frames per second. The model employs a 3D causal VAE, 3D rotary position embeddings, and hybrid attention mechanisms to maintain temporal consistency across video sequences, trained on 35 million video clips and 2 billion images with comprehensive filtering and captioning processes.
Explore the Future of AI
Your server, your data, under your control
CogVideoX-5B is a large-scale generative AI model developed for text-to-video and image-to-video synthesis. Part of the broader CogVideoX family by THUDM and Zhipu AI, CogVideoX-5B builds upon its predecessor, CogVideo, by offering enhanced video duration, spatial resolution, and semantic consistency. The model is designed to translate textual descriptions or static images into coherent, high-fidelity video sequences, supporting a range of creative and research applications in artificial intelligence and computer vision. Its public release is accompanied by extensive technical documentation, research benchmarks, and open-source code to facilitate reproducibility and further development within the scientific community, as detailed in the CogVideoX research paper.
CogVideoX project logo, representing the model's focus on generative video synthesis.
CogVideoX-5B supports text-to-video, image-to-video, and video continuation tasks, enabling flexible video synthesis based on diverse input formats. A distinctive feature is the focus on long-term temporal consistency, achieved via a 3D full attention mechanism that models relationships across both spatial and temporal dimensions. Additionally, multi-modal input fusion is supported, allowing the model to align text and video features for improved semantic accuracy.
The model accepts natural language prompts or static images and generates high-resolution videos, each up to 10 seconds in length at a resolution of 768 x 1360 pixels and 8 frames per second. These capabilities are further extended in later variants, such as CogVideoX1.5-5B, which supports a higher frame rate of 16 frames per second for smoother motion representation. The CogVideoX-5B-I2V variant enables controlled video generation from an input image as background, guided by a text prompt for granular customization.
Video-to-video generation is also possible through integration with captioning models such as CogVLM2-Caption, which produces descriptive text from a source video that can then serve as input for CogVideoX-5B, facilitating video remixing and editing workflows.
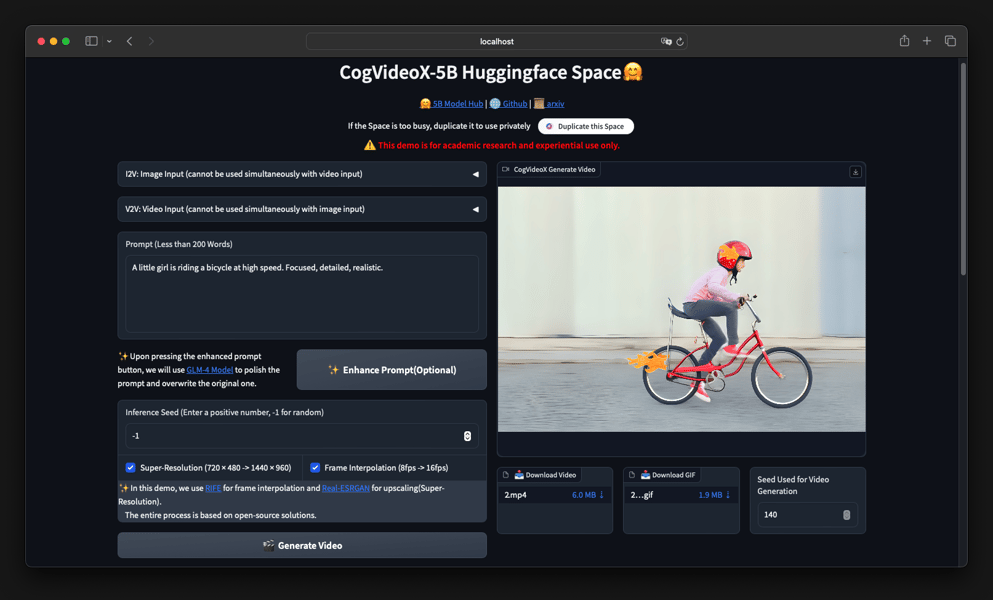
CogVideoX-5B Huggingface web demo displaying a generated video and user interface for prompt-based video synthesis.
Video sample generated by CogVideoX-5B, demonstrating its text-to-video synthesis capabilities. [Source]
Model Architecture
CogVideoX-5B employs a diffusion transformer architecture, drawing on advances in Diffusion Transformers (DiT) to learn the complex distributions required for high-quality video generation. The model architecture features several key components:
A 3D Causal Variational Autoencoder (VAE) is used to encode and compress video sequences along both spatial and temporal axes, improving continuity and video fidelity while controlling data dimensionality. This VAE leverages 3D convolutions with temporal causality, ensuring each output frame depends only on current and previous information, thus preserving realistic motion.
A specialized Expert Transformer module facilitates the deep fusion of video and text features, utilizing adaptive layer normalization to manage modality-specific data. The model applies a "patchify" process, segmenting encoded video representations into sequences suitable for transformer input.
For positional encoding, CogVideoX-5B implements 3D Rotary Position Embeddings (3D-RoPE), independently embedding spatial and temporal coordinates—this accelerates convergence during training and improves performance on longer, complex sequences.
A 3D hybrid attention mechanism unifies spatial and temporal attention, enabling the model to model large-scale motions and maintain scene consistency across extended video durations. This attention strategy is adaptable to various parallel training and acceleration methods.
Sequences of video frames generated by CogVideo, each row illustrating a different prompt and the corresponding model output.
The CogVideoX-5B model is trained on a diverse dataset comprising approximately 35 million high-quality video clips averaging six seconds each, in addition to two billion filtered images sourced from the LAION-5B and COYO-700M collections. Videos are subjected to a rigorous filtering pipeline that employs classifiers to exclude low-quality, redundant, or otherwise unsuitable content. Labels indicating editing, poor motion connectivity, and other noise profiles are used to enhance dataset integrity.
A unique aspect of the dataset preparation is the "Dense Video Caption Data Generation" process. Since many videos lack granular textual descriptions, short captions are generated from sampled frames using image captioning models like CogVLM; these are then summarized by large language models to form detailed video captions. This strategy enables effective supervision and semantic alignment during training.
To support mixed-duration learning, the model batch processing framework mixes videos of varying lengths and resolutions. Progressive training is adopted: lower-resolution sequences are presented initially to foster semantic understanding, followed by higher-resolution fine-tuning to refine visual detail. Explicit uniform sampling across diffusion steps is used to stabilize optimization and improve convergence, aligning with techniques documented in latent diffusion models.
CogVideoX demonstration: 32-frame sequence illustrating continuous action generated by the model, in this case, a man running in the sea.
CogVideoX-5B performance has been assessed on a broad range of metrics using benchmarks such as VBench. Automated evaluations measure the fidelity of actions, scenes, motion dynamics, object multiplicity, and appearance consistency. Dynamic quality and metamorphic amplitude—captured via metrics like "GPT4o-MTScore"—have been leveraged to mitigate biases associated with static video content.
The model achieved strong results across automated metrics, particularly in action plausibility, dynamic scene structure, and semantic alignment, as presented in comparative evaluations. Human evaluation frameworks involved scoring generated videos on sensory quality, instruction-following ability, physical realism, and coverage of the prompt, with CogVideoX-5B demonstrated preferred performance compared to several established contemporaries.
Sample video generated by CogVideoX-5B for the prompt: 'A garden comes to life as a kaleidoscope of butterflies flutters amidst the blossoms...' [Source]Sample video from CogVideoX-5B, guided by the prompt: 'A small boy sprints through the torrential downpour as lightning crackles...' [Source]CogVideoX-5B output for the prompt: 'A suited astronaut reaches out to shake hands with an alien being under the pink-tinged sky of Mars...' [Source]CogVideoX-5B video sample generated with prompt: 'An elderly gentleman sits at the water's edge, engrossed in his artwork...' [Source]
Model Variants, Limitations, and Release Information
The CogVideoX family encompasses several variants tailored for different use cases. CogVideoX-2B is an entry-level model optimized for lower resource consumption and development flexibility, supporting 720 x 480 resolution videos. CogVideoX1.5-5B represents an upgraded architecture, allowing for higher frame rates and enhanced resolution.
CogVideoX-5B has several documented limitations. The model is primarily trained and evaluated on English prompts, with non-English input requiring third-party translation and prompt refinement. While the video fidelity improves with high-resolution fine-tuning, there can be a minor trade-off in semantic detail. Hardware compatibility is constrained by model size, though quantization and memory optimization techniques allow reduced VRAM consumption at the possible expense of inference speed. The model is also sensitive to prompt quality, as it is trained on long, descriptive textual inputs.
Major releases include the open-sourcing of CogVideoX-2B and CogVideoX-5B, as well as the publication of fine-tuning frameworks such as CogKit, enabling further research and customization. Model code and weights are distributed under open-source licenses, with most modules available under the Apache 2.0 or the dedicated CogVideoX license.
External Resources
For further information, technical documentation, and access to model checkpoints and tools, the following external resources are available: