Note: CogVideoX 5B I2V weights are released under a CogVideoX License, and cannot be utilized for commercial purposes. Please read the license to verify if your use case is permitted.
Laboratory OS
Launch a dedicated cloud GPU server running Laboratory OS to download and run CogVideoX 5B I2V using any compatible app or framework.
Direct Download
Must be used with a compatible app, notebook, or codebase. May run slowly, or not work at all, depending on local system resources, particularly GPU(s) and available VRAM.
Generate images and videos using a powerful low-level workflow graph builder - the fastest, most flexible, and most advanced visual generation UI.
Model Report
THUDM / CogVideoX 5B I2V
CogVideoX-5B-I2V is an open-source image-to-video generative AI model developed by THUDM that produces 6-second videos at 720×480 resolution from input images and English text prompts. The model employs a diffusion transformer architecture with 3D Causal VAE compression and generates 49 frames at 8 fps, supporting various video synthesis applications through its controllable conditioning mechanism.
Explore the Future of AI
Your server, your data, under your control
CogVideoX-5B-I2V is an open-source image-to-video (I2V) generative artificial intelligence model developed by THUDM and Zhipu AI as part of the CogVideoX series, with its initial release on September 19, 2024. It is designed to generate short video sequences conditioned on an input image and a text prompt, enabling users to exert fine control over visual content and scene dynamics. This model utilizes advanced transformer-based diffusion architecture along with specialized training methods to align images, text, and generated video frames effectively, supporting various research and creative applications in image-to-video synthesis.
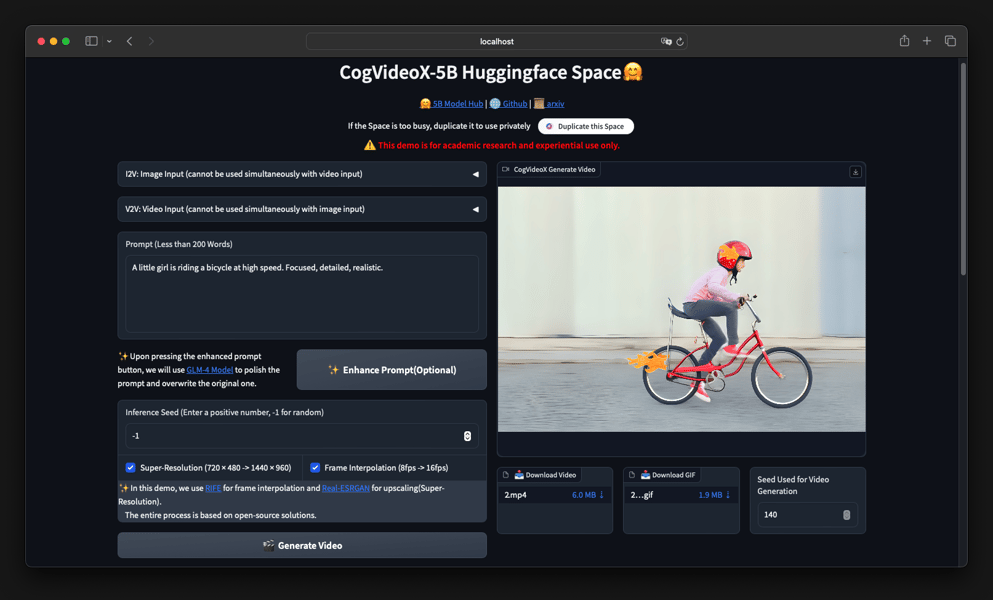
A web demo interface for the CogVideoX-5B model, displaying I2V generation based on user-supplied images and text prompts. The interface integrates enhancement options such as super-resolution and frame interpolation.
CogVideoX-5B-I2V operates on a diffusion transformer architecture, integrating innovative modules to address challenges specific to video generation from static images. The model leverages a 3D Causal Variational Autoencoder (VAE) to compress input video data into a low-dimensional latent space, which effectively captures temporal and spatial dependencies across video frames, as described in the CogVideoX paper. This latent representation is further processed through a sequence of transformer layers that use a combination of expert transformers with adaptive LayerNorm, enhancing alignment between visual and textual modalities.
The fusion between visual and textual information is achieved by concatenating patchified image/video embeddings with text embeddings along the sequence dimension, both of which are encoded by modality-specific backbones (e.g., T5 encoder for text). 3D rotary positional encoding is applied to preserve structural consistency throughout the video sequence. The training objective follows the v-prediction scheme with a noise schedule inspired by Latent Diffusion Models, facilitating higher fidelity in the generated frames and smooth temporal transitions, according to model details.
CogVideoX-5B-I2V incorporates a hybrid 3D attention mechanism that unifies spatial and temporal modeling within a single transformer block, mitigating common video synthesis issues such as object inconsistency during rapid motion. The latent output from the transformer is then decoded by the VAE back to pixel space to reconstruct the final video.
Training Data and Optimization Strategies
Training CogVideoX-5B-I2V involves curated datasets and nuanced optimization techniques to balance semantic richness and visual quality. The video component of the dataset consists of approximately 35 million high-quality, captioned video clips, each selected with video filters and caption models to ensure dynamic content and descriptive textual information. The training set is further augmented with 2 billion high-scoring images drawn from large-scale datasets like LAION-5B and COYO-700M, as detailed in the dataset construction method.
To ensure dense and informative captions, a multi-stage captioning pipeline was deployed: short captions were generated by the Panda70M model, key frame descriptions were obtained by an image captioning model (CogVLM), and summary captions for videos were synthesized by GPT-4 or fine-tuned LLaMA2. This pipeline maximizes alignment between text prompts and visual content, optimizing the model’s response to prompt engineering.
Progressive training techniques, including resolution progression and multi-resolution frame packing, allow the model to initially learn at lower resolutions and then incorporate higher resolution details, which stabilizes training and improves both semantic and visual fidelity. Explicit uniform timestep sampling contributes to a smoother training loss curve and quicker convergence, as described in training optimizations.
Technical Capabilities and Performance
CogVideoX-5B-I2V produces videos with a minimum dimension (width or height) of 768 pixels and a maximum dimension up to 1360 pixels, with a standard output resolution of 720×480 for this variant, based on technical documentation. Videos are generated at 8 frames per second and may last up to 6 seconds, typically encompassing 49 frames. The model exclusively supports English text prompts, which are recommended to be optimized into longer, detailed forms via large language models, since it was trained with verbose and descriptive prompts.
Overview of CogVideoX-generated video sequences, each row illustrating frame progressions for a distinct prompt, reflecting the model's diversity of output.
A key innovation of the I2V model is its controllability: users can provide a specific image as the visual anchor, ensuring that the initial video frames remain faithful to the supplied input. Features such as expert transformer blocks and 3D full attention improve cross-modal fusion and temporal continuity, while the use of quantized inference (INT8, BF16, FP8) makes the model compatible with a range of computational environments. The model also supports advanced memory and speed optimizations with compatible software settings, as indicated in the requirements and optimizations.
Performance is assessed via a suite of metrics from VBench, including Human Action, Scene, Dynamic Degree, Multiple Objects, and Appearance Style, as well as Dynamic Quality and GPT4o-MTScore. CogVideoX-5B serves as the base architecture and demonstrates competitive or leading results on several of these benchmarks, according to benchmarking evidence. Human evaluation studies further indicate consistent performance in sensory quality, instruction following, and physical realism.
Frame-by-frame progression from a 32-frame, 4-second video generated by CogVideoX, showing the continuity and temporal coherence achieved by the model.
Sample video output from CogVideoX-5B, demonstrating its ability to generate coherent, dynamic scenes from text and image input. [Source]
Applications, Usage, and Limitations
CogVideoX-5B-I2V is primarily intended for image-to-video synthesis, where the main use case involves conditioning a generated animation on both an initial image and a descriptive prompt. This facilitates applications in content creation, video prototyping, artistic rendering, and other domains where precise visual control is desirable.
The model is also applicable for tasks such as video continuation and video-to-video generation, where captioning tools extract dense semantics from input video and re-inject them via prompting for high-fidelity reconstructions. Community-driven fine-tuning has extended CogVideoX to specialized domains, such as interior design, through focused training efforts, using the fine-tuning framework.
Several limitations are noted: English is the only supported prompt language; using the model with other languages requires external translation. Quantized modes increase memory efficiency but reduce inference speed. Fine-tuning procedures can be memory-intensive, and improvements in visual sharpness during late-stage fine-tuning may sometimes coincidence with a slight reduction in semantic alignment.
Another CogVideoX-5B video generation sample, further illustrating the model's temporal coherence. [Source]Example output from the CogVideoX-5B I2V model, exhibiting complex scene generation from prompt and image input. [Source]
Comparison within the CogVideoX Family and Development History
The CogVideoX family encompasses several models, with CogVideoX-5B-I2V serving as the image-to-video variant of the larger 5B parameter model. Notable differences between CogVideoX-2B, CogVideoX-5B, and the more recent CogVideoX1.5 series include resolution limits, video length, and architectural refinements, as shown in the model release timeline. For CogVideoX-5B-I2V, videos are generated at a standard resolution of 720×480 pixels, while CogVideoX1.5 and its derivatives can output higher resolutions and longer sequence lengths.
The evolution of the series includes significant milestones such as the open-sourcing of the initial 2B parameter model in August 2024, the expansion to 5B parameters later that month, and the subsequent release of the image-to-video variant and related caption models. Technical documentation, fine-tuning instructions, and tooling for efficient memory use and parallel inference support a broad community of developers and researchers, as outlined in technical resources.
Both permissive and custom licenses are used across the CogVideoX model variants. The repository code is available under the Apache 2.0 License, while model weights, including I2V and T2V variants, fall under the CogVideoX LICENSE.
Additional Resources
For documentation, technical details, and further exploration, the following resources are recommended: