Launch a dedicated cloud GPU server running Laboratory OS to download and run CogVideoX 2B using any compatible app or framework.
Direct Download
Must be used with a compatible app, notebook, or codebase. May run slowly, or not work at all, depending on local system resources, particularly GPU(s) and available VRAM.
Generate images and videos using a powerful low-level workflow graph builder - the fastest, most flexible, and most advanced visual generation UI.
Model Report
THUDM / CogVideoX 2B
CogVideoX-2B is an open-source text-to-video diffusion model developed by THUDM that generates videos up to 720×480 resolution and six seconds in length. The model employs a 3D causal variational autoencoder and Expert Transformer architecture with 3D rotary position embeddings for temporal coherence. Trained on 35 million video clips and 2 billion images using progressive training techniques, it supports INT8 quantization and is released under Apache 2.0 license.
Explore the Future of AI
Your server, your data, under your control
CogVideoX-2B is a large-scale text-to-video generative diffusion model developed by THUDM and Zhipu AI. Part of the broader CogVideoX family, this open-source model is designed to synthesize coherent, high-resolution, and semantically consistent video clips from textual descriptions or images. Building on previous limitations in video generation, such as short duration and restricted motion, CogVideoX-2B introduces architectural and training innovations aimed at enabling longer and more visually consistent video outputs. The model was officially released on August 6, 2024, along with its associated 3D causal variational autoencoder (VAE) and detailed technical documentation CogVideoX paper.
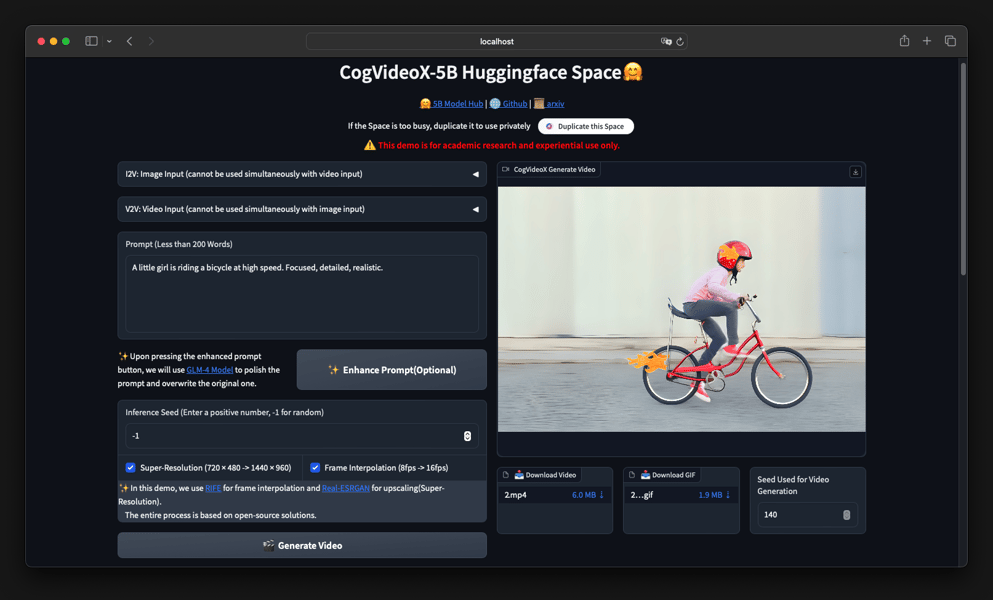
Web demo interface of the CogVideoX model, showing input settings and a generated video output. Prompt: 'A little girl is riding a bicycle at high speed. Focused, detailed, realistic.'
CogVideoX-2B is based on a diffusion Transformer architecture, leveraging several core components to efficiently generate video content from text prompts. At the heart of the model is a 3D causal VAE, which compresses and reconstructs video data across spatial and temporal dimensions, substantially reducing the input sequence length and computational demands. The VAE employs three-dimensional convolutions, yielding higher compression ratios and frame continuity, and uses temporally causal convolutions to ensure that future information does not impact current frame predictions CogVideoX technical report.
Text-to-video alignment is further supported through the use of an Expert Transformer architecture, featuring Expert Adaptive LayerNorm (AdaLN) modules that facilitate deep fusion of language and vision modalities. Video features are encoded using a Patchify approach, which enables joint image and video training by reformatting image and video inputs as sequences of frame-based latent codes. For temporal and spatial understanding, the model uses a 3D rotary position embedding (3D-RoPE), separately encoding x, y, and t coordinates to maintain long-range coherence in generated scenes.
A summary collage of prompt-to-video sequences generated by the CogVideoX model, each row associated with a textual prompt and a distinct visual scene.
CogVideoX-2B is trained on a broad and diverse visual corpus, combining approximately 35 million high-quality, single-shot video clips—each paired with descriptive text—and over 2 billion filtered images from large-scale datasets such as LAION-5B and COYO-700M. Videos are screened using a filtration pipeline built on multiple criteria, such as motion continuity and image aesthetics, to maximize output quality data details.
In handling mixed data types and durations, CogVideoX-2B treats static images as single-frame videos, utilizing mixed-duration training and the Multi-Resolution Frame Pack technique to combine variable-length and different resolution videos within a batch. This approach helps optimize dataset utilization and model generalization.
Progressive training is applied by first exposing the model to low-resolution, short-duration content to capture basic semantics and gradually increasing both resolution and video length throughout training. Explicit uniform sampling of diffusion timesteps ensures stable training and consistent loss curves. To improve video-text alignment, a multi-stage captioning pipeline generates dense descriptions for video data by combining clip-level and frame-level captions, summarizing with large language models such as GPT-4 and Llama 2.
Capabilities and Features
CogVideoX-2B can generate videos up to 720×480 pixels at lengths of up to six seconds and eight frames per second, with output encompassing a wide range of scene dynamics and semantic complexity CogVideoX-2B Hugging Face page. The model maintains temporal and spatial coherence in the resulting videos and supports diverse aspect ratios through careful handling during progressive training.
Features include prompt optimization, where input prompts are refined by large language models such as GLM-4 or GPT-4 for higher output quality. The model accommodates INT8 and FP8 quantized inference, thereby reducing memory requirements and allowing operation on lower-resource hardware. Additionally, the architecture is designed for scalability, supporting future enhancements with larger model sizes and training datasets.
Sample output from CogVideoX-2B, demonstrating text-to-video generation from a single text prompt. [Source]
Performance Evaluation
CogVideoX-2B's performance is assessed using automated metrics from the Vbench benchmark, measuring aspects such as Human Action (96.6), Scene (55.35), Dynamic Degree (66.39), Multiple Objects (57.68), Appearance Style (24.37), Dynamic Quality (57.7), and GPT4o-MT Score (3.09) technical report. The 3D VAE deployed within CogVideoX-2B achieves a peak signal-to-noise ratio (PSNR) of 29.1 and a frame flickering score of 85.5 on standard benchmarks.
The use of Explicit Uniform Sampling during diffusion training is reported to yield more consistent loss reduction and better model convergence. Human evaluation studies involving larger CogVideoX models assess perceptual criteria, such as sensory quality and prompt adherence, in comparison to other contemporary generative models.
A 32-frame sequential output from CogVideoX models showing video continuity. Prompt: 'A man is running in the sea.'
CogVideoX-2B is primarily trained and evaluated on English prompts, with multi-language support relying on external language models for translation. Memory optimization features, such as model CPU offload, may reduce VRAM usage but can impact inference speed. Running the model under quantized (INT8) inference may result in slight slowdowns, though with minimal degradation in visual quality. Video outputs are subject to resolution and duration ceilings, with CogVideoX-2B supporting up to 720×480 resolution and six seconds per clip. Semantic fidelity may decrease slightly when fine-tuned on specialized, visually focused training subsets, and aggressive VAE compression ratios can challenge model convergence full discussion.
Licensing
The CogVideoX-2B model, along with its codebase and associated modules, is released under the Apache 2.0 License. This license permits broad use and modification, promoting scientific research and collaboration.