Launch a dedicated cloud GPU server running Laboratory OS to download and run DeepSeek VL2 Tiny using any compatible app or framework.
Direct Download
Must be used with a compatible app, notebook, or codebase. May run slowly, or not work at all, depending on local system resources, particularly GPU(s) and available VRAM.
Open WebUI is an open-source, self-hosted web interface with a polished, ChatGPT-like user experience for interacting with LLMs. Integrates seamlessly with local Ollama installation.
The most full-featured web interface for experimenting with open source Large Language Models. Featuring a wide range of configurable settings, inference engines, and plugins.
Model Report
Deepseek AI / DeepSeek VL2 Tiny
DeepSeek VL2 Tiny is a vision-language model from Deepseek AI that activates 1.0 billion parameters using Mixture-of-Experts architecture. The model combines a SigLIP vision encoder with a DeepSeekMoE-based language component to handle multimodal tasks including visual question answering, optical character recognition, document analysis, and visual grounding across images and text.
Explore the Future of AI
Your server, your data, under your control
DeepSeek-VL2-Tiny is a vision-language model developed by DeepSeek AI as part of the DeepSeek-VL2 series of Mixture-of-Experts (MoE) models. Designed for multimodal tasks, DeepSeek-VL2-Tiny integrates advanced visual and language understanding within an efficient, scalable architecture. Released in December 2024, the model enables applications including visual question answering, optical character recognition, document analysis, and visual grounding, and is positioned alongside variants like DeepSeek-VL2-Small and DeepSeek-VL2.
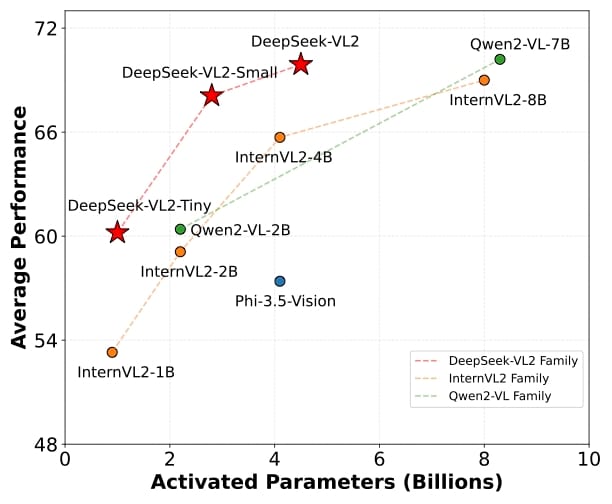
Performance and scalability of the DeepSeek-VL2 family, including DeepSeek-VL2-Tiny. The chart compares average benchmark scores relative to activated parameters among several leading vision-language models.
DeepSeek-VL2-Tiny is constructed using a modular architecture that combines a vision encoder, a visual-language adaptor, and a Mixture-of-Experts language model. The vision encoder utilizes SigLIP-SO400M-384 to process input images, employing a dynamic tiling strategy to efficiently handle images of varying sizes and resolutions. This tiling segments high-resolution images into local tiles (typically 384x384 pixels) and generates a global thumbnail tile, enabling the model to extract both detailed and contextual visual information. The encoded visual data is compressed using a two-stage transformation—first through a 2x2 pixel shuffle, reducing each tile's spatial embedding, then via a multilayer perceptron—which aligns the visual representation with the language model's embedding space.
The language component of DeepSeek-VL2-Tiny builds on DeepSeekMoE, incorporating multi-head latent attention to optimize inference efficiency by compressing the key-value cache into latent vectors. This approach enables sparse computation during training and inference, and a global bias term is employed to balance computational loads across experts. The LLaVA-style decoder-only architecture facilitates consistent joint processing of vision-language inputs.
Parameterization and Variant Positioning
Within the DeepSeek-VL2 family, DeepSeek-VL2-Tiny activates 1.0 billion parameters, with a base language model activating 0.57 billion out of a total of 3 billion parameters. This positions it as a highly parameter-efficient alternative to larger models in the series, such as DeepSeek-VL2-Small and the standard DeepSeek-VL2, which feature more activated and total parameters and thus scale up in both performance and computational resource requirements. All members of the DeepSeek-VL2 series maintain a sequence length of 4096 tokens, supporting complex multi-modal interactions.
Benchmark Performance
DeepSeek-VL2-Tiny achieves competitive results on a range of publicly recognized benchmarks relative to its compact size. In optical character recognition, the model reaches 809 on OCRBench, 88.9 on DocVQA, 81.0 on ChartQA, 66.1 on InfoVQA, and 80.7 on TextVQA. For general question answering and mathematics, it achieves scores including 45.9 on MMStar, 71.6 on AI2D, and 53.6 on MathVista (testmini), among others. On visual grounding tasks, DeepSeek-VL2-Tiny attains 84.7 (val) and up to 87.8 (testA) on RefCOCO, alongside strong results on RefCOCO+ and RefCOCOg. Collectively, these outcomes place the model favorably against other open-source dense and MoE-based vision-language models at comparable scales, as detailed in the technical report.
Training Data and Methods
Training of DeepSeek-VL2-Tiny utilizes a three-stage process. Initially, a vision-language alignment phase focuses on calibrating the multimodal connectors, relying on datasets such as ShareGPT4V with approximately 1.2 million caption and conversation samples. The main pretraining stage incorporates both vision-language and text-only data, drawing from major datasets like WIT, WikiHow, and OBELICS, supplemented with in-house and Chinese content. Dedicated subsets address OCR, visual question answering, document and chart understanding, as well as visual grounding, combining open-source resources such as LaTeX OCR, 12M RenderedText, PubTabNet, and FinTabNet, with extensive proprietary datasets for both English and Chinese text.
The third training stage, supervised fine-tuning, emphasizes instruction-following and conversational responsiveness by integrating in-house data and curated multimodal supervision. Data curation routines include cleaning, regenerating, and quality-controlling responses for public datasets, as well as constructing specialized Chinese QA datasets to complete language coverage. Throughout the process, training leverages optimization techniques such as tensor and expert parallelism and employs the HAI-LLM platform to facilitate the complex GPU workloads necessary for handling large-scale multimodal data.
Applications and Model Scope
DeepSeek-VL2-Tiny supports a broad array of multimodal use cases. Its primary applications include visual question answering, OCR, document, table, and chart analysis, as well as visual grounding—tasks central to document intelligence, knowledge extraction, and perception in artificial agents. Beyond these, the model is applicable to chatbot interactions involving graphical user interfaces, meme interpretation, multi-image dialogue, and visual storytelling scenarios. It is also designed to be adaptable for use in embodied AI and agentic applications that require visual grounding to inform their environment understanding. As with most vision-language models of its size, there are limitations in handling images with extreme blurriness, rare objects, or complex creative storytelling formats.
Licensing and Accessibility
DeepSeek-VL2-Tiny is distributed under the MIT License, with models themselves governed by the DeepSeek Model License. These provisions allow for commercial use and encourage transparency for both research and application development.