Launch a dedicated cloud GPU server running Laboratory OS to download and run DeepSeek VL2 Small using any compatible app or framework.
Direct Download
Must be used with a compatible app, notebook, or codebase. May run slowly, or not work at all, depending on local system resources, particularly GPU(s) and available VRAM.
Open WebUI is an open-source, self-hosted web interface with a polished, ChatGPT-like user experience for interacting with LLMs. Integrates seamlessly with local Ollama installation.
The most full-featured web interface for experimenting with open source Large Language Models. Featuring a wide range of configurable settings, inference engines, and plugins.
Model Report
Deepseek AI / DeepSeek VL2 Small
DeepSeek VL2 Small is a 2.8 billion parameter multimodal vision-language model that uses a Mixture-of-Experts architecture with dynamic tiling for processing high-resolution images. Built on the DeepSeekMoE-16B framework with SigLIP vision encoding, it handles tasks including visual question answering, OCR, document analysis, and visual grounding across multiple languages, achieving competitive performance on benchmarks like DocVQA while maintaining computational efficiency through sparse expert routing.
Explore the Future of AI
Your server, your data, under your control
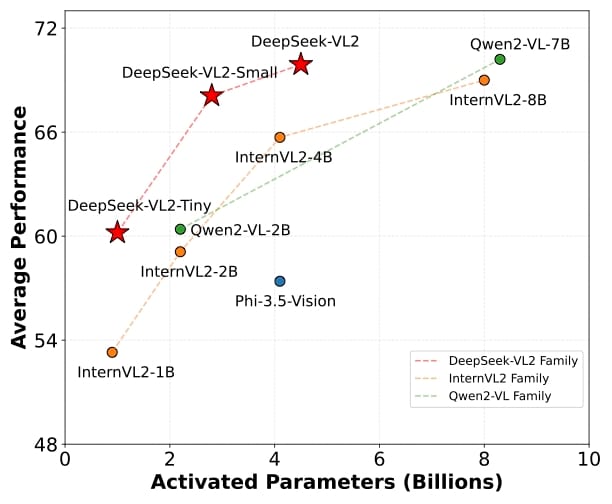
Performance chart positioning DeepSeek-VL2 model variants (including Small) alongside alternative multimodal models as a function of activated parameters. DeepSeek-VL2 models are highlighted, illustrating relative performance scaling across model sizes.
DeepSeek-VL2-Small is part of the DeepSeek-VL2 family of large Mixture-of-Experts (MoE) vision-language models developed by DeepSeek-AI. Designed for multimodal understanding, the VL2 series builds upon earlier iterations to provide performance in tasks such as visual question answering, optical character recognition (OCR), document and chart analysis, and visual grounding, with a focus on computational efficiency and scalability. The DeepSeek-VL2-Small model comprises 2.8 billion activated parameters and leverages the DeepSeekMoE-16B architecture, contributing to its performance in both language and vision domains according to the official technical report.
Architecture and Innovations
DeepSeek-VL2 models, including the Small variant, follow a LLaVA-style modular architecture comprising a vision encoder, a vision-language adaptor, and a Mixture-of-Experts language model. The vision encoder is based on SigLIP-SO400M-384, responsible for extracting image features. These features pass through a two-layer multilayer perceptron (MLP) that projects the visual data into the activation space used by the language model. The core language model, DeepSeekMoE, employs a sparse mixture-of-experts framework optimized with Multi-head Latent Attention (MLA), which compresses key-value caches into compact latent representations for more efficient inference.
A key innovation is the dynamic tiling vision encoding strategy, which segments large and high-resolution images into local tiles (384x384 pixels) and a global thumbnail. This enables processing of varying aspect ratios and ultra-high-resolution content. Each tile undergoes separate encoding, followed by a 2x2 pixel shuffle operation to reduce the token length, which contributes to maintaining a manageable computational footprint. When more than two images are input, the dynamic tiling is disabled to prioritize throughput and context length.
The MoE framework within DeepSeek-VL2-Small uses 64 routed experts and 2 shared experts, employing a softmax-based gating mechanism with Top-K routing. This allows the model to dynamically select a subset of experts per input, facilitating both scalability and specialization among expert modules.
Training Data and Methodology
Training of DeepSeek-VL2-Small involves a three-stage pipeline. The initial phase centers on vision-language alignment, using datasets such as ShareGPT4V to optimize the vision-language connector while keeping the language model parameters frozen. This stage focuses on building cross-modal bridges.
The second pretraining phase expands to joint optimization of all model components, employing an interleaved mixture of vision-language and text-only samples. The vision-language data includes sources like WIT, WikiHow, and portions of OBELICS for broad coverage, as well as curated Chinese content for multilingual performance. Specialized datasets target tasks such as OCR (e.g., LaTeX OCR, RenderedText), table and chart understanding (e.g., PubTabNet, FinTabNet), and visual grounding.
Supervised fine-tuning constitutes the final stage, where instruction-following and conversational abilities are refined using a comprehensive in-house dataset encompassing question-answer pairs, document understanding dialogues, table-based questions, reasoning, and visual grounding. This stage supports the model's responses in terms of contextual relevance and accuracy, particularly in multilingual scenarios.
Performance and Evaluation
DeepSeek-VL2-Small demonstrates performance on a range of established multimodal benchmarks, particularly in OCR and document understanding, general visual question-answering, and visual grounding tasks. On the DocVQA benchmark for document comprehension, DeepSeek-VL2-Small achieves a score of 92.3, outperforming comparably sized alternatives such as InternVL2-2B and Qwen2-VL-2B, as reported in the official benchmark tables. In visual reasoning and grounding, results on datasets like RefCOCO and RefCOCOg also indicate competitive accuracy, with scores exceeding 90 on key test sets.
The model supports sequence lengths up to 4096 tokens, permitting the integration of conversations and multiple image contexts. Visual grounding capabilities are specifically enhanced, enabling both object localization from textual prompts and in-context grounding that requires cross-referencing between images and regions of interest.
Applications and Limitations
Typical application domains for DeepSeek-VL2-Small include visual question answering, dense captioning, chart and table analysis, and GUI perception, as detailed in the DeepSeek-VL2 documentation. It is also suited for tasks like visual reasoning, meme understanding, and multi-image conversational settings, where grounded responses referencing visual content are essential.
Certain limitations remain. The current version limits context to a small number of images per conversation, which restricts complex multi-image tasks. Some challenges persist in handling low-quality or unseen content and in advanced reasoning or creative storytelling. The basic demonstration interface is not yet fully optimized for high-throughput deployment, suggesting considerations for production use.